📚 Part 1: Java 集合使用手册
0.String - 不可变字符串
// 初始化
String s = "hello";
String s2 = new String("world");
String s3 = String.valueOf(123); // 数字转字符串
// 基本属性
int len = s.length(); // 长度
boolean empty = s.isEmpty(); // 是否为空
char ch = s.charAt(0); // 获取字符
// 查找
int index = s.indexOf("ll"); // 查找子串位置
int lastIndex = s.lastIndexOf("l"); // 最后出现位置
boolean contains = s.contains("el"); // 是否包含
// 截取
String sub = s.substring(1, 4); // [1, 4) 截取
String sub2 = s.substring(2); // 从索引2到结尾
// 替换
String replaced = s.replace("l", "L"); // 替换所有
String replaced2 = s.replaceFirst("l", "L"); // 替换第一个
String replaced3 = s.replaceAll("[aeiou]", "*"); // 正则替换
// 分割
String[] parts = "a,b,c".split(","); // 按分隔符分割
String[] parts2 = "a b c".split("\\s+"); // 按空格分割
// 拼接
String joined = String.join(",", "a", "b", "c"); // "a,b,c"
String concat = s.concat(" world"); // 拼接
// 大小写
String upper = s.toUpperCase();
String lower = s.toUpperCase().toLowerCase();
// 去空格
String trimmed = " hello ".trim(); // 去两端空格
String stripped = " hello ".strip(); // Java 11+
// 比较
boolean equals = s.equals("hello");
boolean equalsIgnoreCase = s.equalsIgnoreCase("HELLO");
int compare = s.compareTo("world"); // 字典序比较
// 判断
boolean startsWith = s.startsWith("he");
boolean endsWith = s.endsWith("lo");
// 转换
char[] chars = s.toCharArray(); // 转字符数组
byte[] bytes = s.getBytes(); // 转字节数组
StringBuilder - 可变字符串
使用场景:单线程环境下需要频繁修改字符串
// 初始化
StringBuilder sb = new StringBuilder();
StringBuilder sb2 = new StringBuilder("hello");
StringBuilder sb3 = new StringBuilder(100); // 指定初始容量
// 添加(拼接)
sb.append("hello"); // 尾部添加
sb.append(123); // 添加数字
sb.append('!'); // 添加字符
sb.insert(0, "start "); // 指定位置插入
// 删除
sb.delete(0, 5); // 删除 [0, 5)
sb.deleteCharAt(0); // 删除指定位置
sb.setLength(0); // 清空(重置长度为0)
// 修改
sb.replace(0, 5, "world"); // 替换 [0, 5)
sb.setCharAt(0, 'H'); // 修改指定位置字符
// 反转
sb.reverse();
// 查询
int len = sb.length();
char ch = sb.charAt(0);
String sub = sb.substring(0, 5);
// 转换为 String
String result = sb.toString();
// 常见应用:循环拼接字符串
StringBuilder result = new StringBuilder();
for (int i = 0; i < 1000; i++) {
result.append(i).append(",");
}
// 比用 String + 拼接快得多!
StringBuffer - 可变字符串
使用场景:多线程环境下需要频繁修改字符串
// API 与 StringBuilder 完全相同
StringBuffer sb = new StringBuffer();
sb.append("hello");
sb.append(" world");
String result = sb.toString();
// 区别:StringBuffer 的方法都是 synchronized 的
// 多线程安全,但性能比 StringBuilder 差
常用字符串操作技巧
// 1. 字符串转数字
int num = Integer.parseInt("123");
long l = Long.parseLong("123");
double d = Double.parseDouble("3.14");
// 2. 数字转字符串
String s1 = String.valueOf(123);
String s2 = Integer.toString(123);
String s3 = "" + 123; // 不推荐
// 3. 字符串数组拼接
String[] arr = {"a", "b", "c"};
String joined = String.join(",", arr); // "a,b,c"
// 4. 重复字符串(Java 11+)
String repeated = "ab".repeat(3); // "ababab"
// 5. 判断空字符串
if (s != null && !s.isEmpty()) { }
if (s != null && !s.isBlank()) { } // Java 11+,忽略空白字符
// 6. 字符串格式化
String formatted = String.format("Hello %s, you are %d years old", "Alice", 25);
1. List - 列表
ArrayList - 动态数组
// 初始化
List<Integer> list = new ArrayList<>();
List<String> list2 = new ArrayList<>(Arrays.asList("a", "b", "c"));
List<Integer> list3 = new ArrayList<>(100); // 指定初始容量
// 增
list.add(1); // 尾部添加
list.add(0, 10); // 指定位置添加
list.addAll(Arrays.asList(2,3,4)); // 批量添加
// 删
list.remove(0); // 删除指定索引
list.remove(Integer.valueOf(1)); // 删除指定元素
list.clear(); // 清空
// 改
list.set(0, 100); // 修改指定位置
// 查
int val = list.get(0); // 获取元素
int size = list.size(); // 获取大小
boolean empty = list.isEmpty(); // 是否为空
boolean contains = list.contains(1); // 是否包含
int index = list.indexOf(1); // 查找索引
// 遍历
for (int num : list) {
System.out.println(num);
}
// 或使用迭代器
Iterator<Integer> it = list.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
LinkedList - 双向链表
LinkedList<Integer> list = new LinkedList<>();
// 头部操作
list.addFirst(1);
list.removeFirst();
int first = list.getFirst();
// 尾部操作
list.addLast(2);
list.removeLast();
int last = list.getLast();
// 作为队列使用
list.offer(3); // 入队
int head = list.poll(); // 出队
// 作为栈使用
list.push(4); // 入栈
int top = list.pop(); // 出栈
2. Set - 集合
HashSet - 无序不重复
// 初始化
Set<Integer> set = new HashSet<>();
Set<String> set2 = new HashSet<>(Arrays.asList("a", "b", "c"));
// 增
set.add(1);
set.addAll(Arrays.asList(2, 3, 4));
// 删
set.remove(1);
set.clear();
// 查
boolean contains = set.contains(1);
int size = set.size();
boolean empty = set.isEmpty();
// 遍历
for (int num : set) {
System.out.println(num);
}
TreeSet - 有序集合(红黑树)
TreeSet<Integer> set = new TreeSet<>();
// 基本操作同 HashSet
set.add(3);
set.add(1);
set.add(2);
System.out.println(set); // [1, 2, 3] 自动排序
// 特有方法
int first = set.first(); // 最小元素
int last = set.last(); // 最大元素
int lower = set.lower(2); // 小于 2 的最大元素
int higher = set.higher(2); // 大于 2 的最小元素
int floor = set.floor(2); // ≤ 2 的最大元素
int ceiling = set.ceiling(2); // ≥ 2 的最小元素
// 子集操作
SortedSet<Integer> subset = set.subSet(1, 3); // [1, 3)
SortedSet<Integer> headSet = set.headSet(2); // < 2
SortedSet<Integer> tailSet = set.tailSet(2); // >= 2
LinkedHashSet - 保持插入顺序
Set<Integer> set = new LinkedHashSet<>();
set.add(3);
set.add(1);
set.add(2);
System.out.println(set); // [3, 1, 2] 保持插入顺序
3. Map - 映射
HashMap - 键值对
// 初始化
Map<String, Integer> map = new HashMap<>();
// 增/改
map.put("apple", 1);
map.put("banana", 2);
map.putIfAbsent("apple", 10); // 键不存在时才添加
// 删
map.remove("apple");
map.clear();
// 查
int val = map.get("apple");
int valOrDefault = map.getOrDefault("orange", 0);
boolean hasKey = map.containsKey("apple");
boolean hasValue = map.containsValue(1);
int size = map.size();
// 遍历键值对
for (Map.Entry<String, Integer> entry : map.entrySet()) {
String key = entry.getKey();
int value = entry.getValue();
}
// 遍历键
for (String key : map.keySet()) {
System.out.println(key);
}
// 遍历值
for (int value : map.values()) {
System.out.println(value);
}
// Java 8+ 新方法
map.computeIfAbsent("cherry", k -> 3);
map.merge("apple", 1, Integer::sum); // 累加
TreeMap - 有序映射(红黑树)
TreeMap<Integer, String> map = new TreeMap<>();
map.put(3, "c");
map.put(1, "a");
map.put(2, "b");
// 基本操作同 HashMap
// 特有方法
int firstKey = map.firstKey();
int lastKey = map.lastKey();
Map.Entry<Integer, String> firstEntry = map.firstEntry();
Map.Entry<Integer, String> lastEntry = map.lastEntry();
int lowerKey = map.lowerKey(2); // < 2 的最大键
int higherKey = map.higherKey(2); // > 2 的最小键
int floorKey = map.floorKey(2); // <= 2 的最大键
int ceilingKey = map.ceilingKey(2); // >= 2 的最小键
LinkedHashMap - 保持插入顺序
Map<String, Integer> map = new LinkedHashMap<>();
map.put("c", 3);
map.put("a", 1);
map.put("b", 2);
// 遍历时保持插入顺序: c, a, b
4. Queue - 队列
普通队列
Queue<Integer> queue = new LinkedList<>();
// 入队
queue.offer(1);
queue.add(2); // 队列满时抛异常
// 出队
int head = queue.poll(); // 空时返回 null
int head2 = queue.remove(); // 空时抛异常
// 查看队首
int peek = queue.peek(); // 空时返回 null
int peek2 = queue.element(); // 空时抛异常
PriorityQueue - 优先队列(堆)
// 小根堆(默认)
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 大根堆
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
// 自定义对象
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
minHeap.offer(3);
minHeap.offer(1);
minHeap.offer(2);
while (!minHeap.isEmpty()) {
System.out.println(minHeap.poll()); // 1, 2, 3
}
Deque - 双端队列
Deque<Integer> deque = new ArrayDeque<>();
// ===== 头部操作(相当于队列的 front) =====
deque.offerFirst(1); // 将 1 添加到 deque 的头部
deque.pollFirst(); // 移除并返回头部元素,如果为空返回 null
deque.peekFirst(); // 返回头部元素,但不删除,如果为空返回 null
// ===== 尾部操作(相当于队列的 rear) =====
deque.offerLast(2); // 将 2 添加到 deque 的尾部
deque.pollLast(); // 移除并返回尾部元素,如果为空返回 null
deque.peekLast(); // 返回尾部元素,但不删除,如果为空返回 null
// ===== 作为栈使用(LIFO) =====
deque.push(3); // 将 3 压入栈顶
int top = deque.pop(); // 弹出栈顶元素并返回
5. Stack - 栈(不推荐使用)
Stack<Integer> stack = new Stack<>();
stack.push(1); // 入栈
int top = stack.pop(); // 出栈
int peek = stack.peek(); // 查看栈顶
boolean empty = stack.isEmpty();
int size = stack.size();
// 推荐使用 Deque 代替 Stack
Deque<Integer> stack2 = new ArrayDeque<>();
6.其他技巧
Arrays.sort - 排序
// ==================== Arrays.sort() ====================
// 一维数组排序
int[] nums = {5,3,1,4,2};
Arrays.sort(nums); // 升序排序
// 二维数组排序
int[][] arr = {{1,3},{2,2},{1,2}};
// 按第一个元素升序
Arrays.sort(arr, (a,b) -> a[0] - b[0]);
// 按第一个元素降序
Arrays.sort(arr, (a,b) -> b[0] - a[0]);
// 多条件排序
Arrays.sort(arr, (a,b) ->
a[0] == b[0] ? a[1] - b[1] : a[0] - b[0]
); // 先按a[0]排序,相同再按a[1]
// 降序 + 升序组合
Arrays.sort(arr, (a,b) ->
b[0] == a[0] ? a[1] - b[1] : b[0] - a[0]
);
// ==================== Arrays 工具 ====================
// 填充数组
int[] arr2 = new int[5];
Arrays.fill(arr2, -1);
// 指定范围填充
Arrays.fill(arr2, 1, 4, 9);
// 复制数组
int[] copy = Arrays.copyOf(arr2, arr2.length);
Arrays工具
// ==================== Arrays 工具 ====================
// 填充数组
int[] arr2 = new int[5];
Arrays.fill(arr2, -1);
// 指定范围填充
Arrays.fill(arr2, 1, 4, 9);
// 复制数组
int[] copy = Arrays.copyOf(arr2, arr2.length);```
---
## 🧮 Part 2: 算法模板
### 1. 树的遍历
#### 二叉树定义
```java
class TreeNode {
int val; // 节点值
TreeNode left; // 左子节点
TreeNode right; // 右子节点
TreeNode(int val) { this.val = val; }
}
Math - 数值操作
// ==================== Math ====================
int max = Math.max(a, b); // 最大值
int min = Math.min(a, b); // 最小值
int abs = Math.abs(-10); // 绝对值
double pow = Math.pow(2,3); // 幂运算 2^3
double ceil = Math.ceil(3.2); // 向上取整
double floor = Math.floor(3.8); // 向下取整
long round = Math.round(3.6); // 四舍五入
🧮 Part 2: 算法模板
1. 树的遍历
二叉树定义
class TreeNode {
int val; // 节点值
TreeNode left; // 左子节点
TreeNode right; // 右子节点
TreeNode(int val) { this.val = val; }
}
DFS - 深度优先遍历
前序遍历(根-左-右)
// 递归版本 - 最简洁直观
void preorder(TreeNode root) {
if (root == null) return; // 递归终止条件:空节点
System.out.println(root.val); // 1. 先访问根节点
preorder(root.left); // 2. 再遍历左子树
preorder(root.right); // 3. 最后遍历右子树
}
// 迭代版本 - 使用栈模拟递归
List<Integer> preorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Stack<TreeNode> stack = new Stack<>();
stack.push(root); // 根节点入栈
while (!stack.isEmpty()) {
TreeNode node = stack.pop(); // 弹出栈顶节点
res.add(node.val); // 访问该节点
// 关键:先压右子节点,再压左子节点
// 这样出栈时左子节点先出(栈是后进先出)
if (node.right != null) stack.push(node.right);
if (node.left != null) stack.push(node.left);
}
return res;
}
中序遍历(左-根-右)
// 递归版本
void inorder(TreeNode root) {
if (root == null) return; // 递归终止条件
inorder(root.left); // 1. 先遍历左子树
System.out.println(root.val); // 2. 再访问根节点
inorder(root.right); // 3. 最后遍历右子树
}
// 迭代版本 - 一直向左走到底
List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
Stack<TreeNode> stack = new Stack<>();
TreeNode curr = root;
while (curr != null || !stack.isEmpty()) {
// 第一步:一直向左走到底,沿途节点入栈
while (curr != null) {
stack.push(curr);
curr = curr.left;
}
// 第二步:弹出栈顶(当前最左节点),访问它
curr = stack.pop();
res.add(curr.val);
// 第三步:转向右子树
curr = curr.right;
}
return res;
}
后序遍历(左-右-根)
// 递归版本
void postorder(TreeNode root) {
if (root == null) return; // 递归终止条件
postorder(root.left); // 1. 先遍历左子树
postorder(root.right); // 2. 再遍历右子树
System.out.println(root.val); // 3. 最后访问根节点
}
// 迭代版本 - 巧妙方法:前序遍历变形 + 反转
// 思路:前序是"根左右",改成"根右左",反转后得到"左右根"
List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
if (root == null) return res;
Stack<TreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.isEmpty()) {
TreeNode node = stack.pop();
res.add(node.val); // 添加到结果(根右左顺序)
// 注意:这里先左后右,出栈时就是先右后左
if (node.left != null) stack.push(node.left);
if (node.right != null) stack.push(node.right);
}
Collections.reverse(res); // 反转得到左右根
return res;
}
BFS - 层序遍历
// 按层遍历二叉树,每层的节点放在一个列表中
List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
if (root == null) return res;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root); // 根节点入队
while (!queue.isEmpty()) {
int size = queue.size(); // 当前层的节点数(重要!)
List<Integer> level = new ArrayList<>();
// 遍历当前层的所有节点
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll(); // 出队
level.add(node.val); // 记录节点值
// 将下一层的节点入队
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
res.add(level); // 保存当前层结果
}
return res;
}
线段树(Segment Tree)
/**
* 线段树:用于高效处理区间查询和单点修改
* 时间复杂度:构建 O(n),查询 O(log n),更新 O(log n)
*/
class SegmentTree {
private int[] tree; // 线段树数组
private int n; // 原数组大小
public SegmentTree(int[] nums) {
n = nums.length;
tree = new int[4 * n]; // 线段树最多需要 4n 空间
build(nums, 0, 0, n - 1);
}
// 构建线段树:递归构建
// node: 当前节点在 tree 中的索引
// start, end: 当前节点代表的区间 [start, end]
private void build(int[] nums, int node, int start, int end) {
if (start == end) {
// 叶子节点:直接存储原数组的值
tree[node] = nums[start];
return;
}
int mid = start + (end - start) / 2;
int leftNode = 2 * node + 1; // 左子节点索引
int rightNode = 2 * node + 2; // 右子节点索引
// 递归构建左右子树
build(nums, leftNode, start, mid);
build(nums, rightNode, mid + 1, end);
// 当前节点的值 = 左子树 + 右子树(区间和)
tree[node] = tree[leftNode] + tree[rightNode];
}
// 区间查询:查询区间 [l, r] 的和
public int query(int l, int r) {
return query(0, 0, n - 1, l, r);
}
private int query(int node, int start, int end, int l, int r) {
// 情况1:当前区间与查询区间完全不相交
if (l > end || r < start) return 0;
// 情况2:当前区间完全包含在查询区间内
if (l <= start && end <= r) return tree[node];
// 情况3:部分相交,需要递归查询左右子树
int mid = start + (end - start) / 2;
int leftSum = query(2 * node + 1, start, mid, l, r);
int rightSum = query(2 * node + 2, mid + 1, end, l, r);
return leftSum + rightSum;
}
// 单点更新:将 index 位置的值更新为 val
public void update(int index, int val) {
update(0, 0, n - 1, index, val);
}
private void update(int node, int start, int end, int index, int val) {
if (start == end) {
// 找到叶子节点,更新值
tree[node] = val;
return;
}
int mid = start + (end - start) / 2;
int leftNode = 2 * node + 1;
int rightNode = 2 * node + 2;
// 判断 index 在左子树还是右子树
if (index <= mid) {
update(leftNode, start, mid, index, val);
} else {
update(rightNode, mid + 1, end, index, val);
}
// 更新完子树后,更新当前节点
tree[node] = tree[leftNode] + tree[rightNode];
}
}
2. 图算法
图的表示
// 方式1:邻接表(适合稀疏图)
Map<Integer, List<Integer>> graph = new HashMap<>();
// 或使用 ArrayList
List<List<Integer>> graph = new ArrayList<>();
// 方式2:邻接矩阵(适合密集图)
int[][] graph = new int[n][n]; // graph[i][j] 表示 i 到 j 的边权
DFS - 图的深度优先遍历
// 递归实现 DFS
void dfs(int node, Set<Integer> visited, List<List<Integer>> graph) {
visited.add(node); // 标记当前节点已访问
System.out.println(node); // 处理当前节点
// 遍历所有邻居节点
for (int neighbor : graph.get(node)) {
if (!visited.contains(neighbor)) { // 如果邻居未访问
dfs(neighbor, visited, graph); // 递归访问邻居
}
}
}
// 使用示例
Set<Integer> visited = new HashSet<>();
dfs(0, visited, graph); // 从节点 0 开始 DFS
BFS - 图的广度优先遍历
// 使用队列实现 BFS
void bfs(int start, List<List<Integer>> graph) {
Set<Integer> visited = new HashSet<>();
Queue<Integer> queue = new LinkedList<>();
queue.offer(start); // 起始节点入队
visited.add(start); // 标记已访问
while (!queue.isEmpty()) {
int node = queue.poll(); // 出队
System.out.println(node); // 处理当前节点
// 遍历所有邻居节点
for (int neighbor : graph.get(node)) {
if (!visited.contains(neighbor)) {
queue.offer(neighbor); // 邻居入队
visited.add(neighbor); // 标记已访问
}
}
}
}
拓扑排序(Kahn 算法)
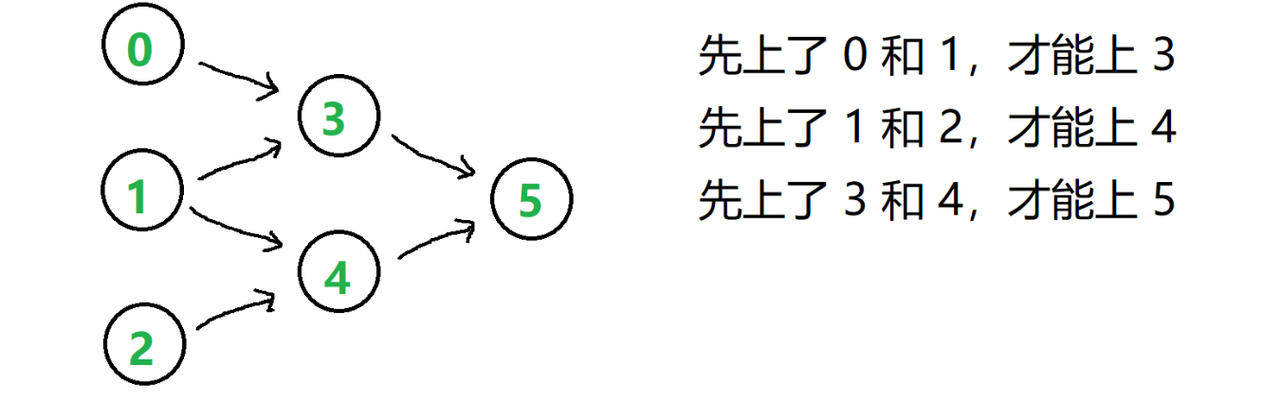
/**
* 拓扑排序:将有向无环图(DAG)转换为线性序列
* 应用:课程安排、任务调度等
* 核心思想:不断移除入度为0的节点
*/
List<Integer> topologicalSort(int n, int[][] edges) {
// 构建邻接表
List<List<Integer>> graph = new ArrayList<>();
int[] inDegree = new int[n]; // 记录每个节点的入度
for (int i = 0; i < n; i++) {
graph.add(new ArrayList<>());
}
// 构建图并计算入度
for (int[] edge : edges) {
graph.get(edge[0]).add(edge[1]); // edge[0] -> edge[1]
inDegree[edge[1]]++; // edge[1] 的入度+1
}
// 将所有入度为0的节点入队
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < n; i++) {
if (inDegree[i] == 0) {
queue.offer(i);
}
}
List<Integer> res = new ArrayList<>();
while (!queue.isEmpty()) {
int node = queue.poll();
res.add(node); // 将节点加入结果
// 删除该节点的所有出边
for (int neighbor : graph.get(node)) {
inDegree[neighbor]--; // 邻居的入度-1
if (inDegree[neighbor] == 0) { // 入度变为0,入队
queue.offer(neighbor);
}
}
}
// 如果所有节点都被访问,说明无环,返回结果;否则返回空
return res.size() == n ? res : new ArrayList<>();
}
Dijkstra 最短路径算法
/**
* Dijkstra算法:单源最短路径(不能有负权边)
* 时间复杂度:O(E log V),E是边数,V是顶点数
* 核心思想:贪心,每次选择距离最小的未访问节点
*/
int[] dijkstra(int n, int[][] edges, int start) {
// 构建邻接表: {neighbor, weight}
List<List<int[]>> graph = new ArrayList<>();
for (int i = 0; i < n; i++) {
graph.add(new ArrayList<>());
}
for (int[] edge : edges) {
// edge = [from, to, weight]
graph.get(edge[0]).add(new int[]{edge[1], edge[2]});
}
// dist[i] 表示从 start 到 i 的最短距离
int[] dist = new int[n];
Arrays.fill(dist, Integer.MAX_VALUE);
dist[start] = 0;
// 优先队列: {distance, node},按距离从小到大排序
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[0] - b[0]);
pq.offer(new int[]{0, start});
while (!pq.isEmpty()) {
int[] curr = pq.poll();
int d = curr[0], node = curr[1];
// 如果当前距离大于已知最短距离,跳过
if (d > dist[node]) continue;
// 遍历所有邻居,尝试松弛操作
for (int[] neighbor : graph.get(node)) {
int next = neighbor[0], weight = neighbor[1];
int newDist = d + weight;
// 如果找到更短的路径,更新距离
if (newDist < dist[next]) {
dist[next] = newDist;
pq.offer(new int[]{newDist, next});
}
}
}
return dist;
}
Bellman-Ford 算法(可处理负权边)
/**
* Bellman-Ford算法:单源最短路径,可处理负权边
* 时间复杂度:O(V * E)
* 可以检测负环
*/
int[] bellmanFord(int n, int[][] edges, int start) {
int[] dist = new int[n];
Arrays.fill(dist, Integer.MAX_VALUE);
dist[start] = 0;
// 松弛操作:最多进行 n-1 次
// 原理:最短路径最多包含 n-1 条边
for (int i = 0; i < n - 1; i++) {
for (int[] edge : edges) {
int u = edge[0], v = edge[1], w = edge[2];
// 松弛操作:如果经过 u 到 v 更短,则更新
if (dist[u] != Integer.MAX_VALUE && dist[u] + w < dist[v]) {
dist[v] = dist[u] + w;
}
}
}
// 第 n 次松弛:如果还能更新,说明存在负环
for (int[] edge : edges) {
int u = edge[0], v = edge[1], w = edge[2];
if (dist[u] != Integer.MAX_VALUE && dist[u] + w < dist[v]) {
return null; // 存在负环
}
}
return dist;
}
Floyd-Warshall 全源最短路径
/**
* Floyd-Warshall算法:计算所有点对之间的最短路径
* 时间复杂度:O(V³)
* 核心思想:动态规划,逐步加入中间节点
*/
int[][] floydWarshall(int n, int[][] edges) {
int[][] dist = new int[n][n];
// 初始化距离矩阵
for (int i = 0; i < n; i++) {
Arrays.fill(dist[i], Integer.MAX_VALUE / 2); // 除以2防止溢出
dist[i][i] = 0; // 自己到自己距离为0
}
// 填入边的权重
for (int[] edge : edges) {
dist[edge[0]][edge[1]] = edge[2];
}
// 动态规划:k 是中间节点
// dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j])
for (int k = 0; k < n; k++) { // 枚举中间节点
for (int i = 0; i < n; i++) { // 枚举起点
for (int j = 0; j < n; j++) { // 枚举终点
// 如果经过 k 中转更短,则更新
dist[i][j] = Math.min(dist[i][j], dist[i][k] + dist[k][j]);
}
}
}
return dist;
}
Prim 最小生成树
/**
* Prim算法:构建最小生成树
* 时间复杂度:O(E log V)
* 核心思想:从一个节点开始,逐步扩展,每次选最小边
*/
int prim(int n, int[][] edges) {
// 构建邻接表
List<List<int[]>> graph = new ArrayList<>();
for (int i = 0; i < n; i++) {
graph.add(new ArrayList<>());
}
for (int[] edge : edges) {
// 无向图:添加双向边
graph.get(edge[0]).add(new int[]{edge[1], edge[2]});
graph.get(edge[1]).add(new int[]{edge[0], edge[2]});
}
boolean[] visited = new boolean[n];
// 优先队列:{node, weight},按权重从小到大
PriorityQueue<int[]> pq = new PriorityQueue<>((a, b) -> a[1] - b[1]);
pq.offer(new int[]{0, 0}); // 从节点0开始,权重0
int totalWeight = 0; // 最小生成树的总权重
int edgeCount = 0; // 已添加的边数
while (!pq.isEmpty() && edgeCount < n) {
int[] curr = pq.poll();
int node = curr[0], weight = curr[1];
if (visited[node]) continue; // 已访问,跳过
visited[node] = true;
totalWeight += weight; // 加入最小生成树
edgeCount++;
// 将邻居节点的边加入优先队列
for (int[] neighbor : graph.get(node)) {
if (!visited[neighbor[0]]) {
pq.offer(neighbor);
}
}
}
// 如果所有节点都连通,返回总权重;否则返回-1
return edgeCount == n ? totalWeight : -1;
}
Kruskal 最小生成树(并查集)
/**
* 并查集:用于判断连通性和合并集合
*/
class UnionFind {
int[] parent; // parent[i] 表示 i 的父节点
int[] rank; // rank[i] 表示以 i 为根的树的高度
public UnionFind(int n) {
parent = new int[n];
rank = new int[n];
for (int i = 0; i < n; i++) {
parent[i] = i; // 初始时每个节点的父节点是自己
}
}
// 查找:找到 x 所在集合的代表元素(路径压缩)
public int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]); // 路径压缩:直接连到根节点
}
return parent[x];
}
// 合并:将 x 和 y 所在的集合合并(按秩合并)
public boolean union(int x, int y) {
int rootX = find(x), rootY = find(y);
if (rootX == rootY) return false; // 已经在同一集合
// 按秩合并:将矮树挂到高树上
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
parent[rootY] = rootX;
rank[rootX]++; // 高度相同,随便挂,高度+1
}
return true;
}
}
/**
* Kruskal算法:构建最小生成树
* 时间复杂度:O(E log E)
* 核心思想:按边权从小到大排序,用并查集避免成环
*/
int kruskal(int n, int[][] edges) {
// 按边权从小到大排序
Arrays.sort(edges, (a, b) -> a[2] - b[2]);
UnionFind uf = new UnionFind(n);
int totalWeight = 0;
int edgeCount = 0;
for (int[] edge : edges) {
// 如果两个节点不在同一集合,添加这条边
if (uf.union(edge[0], edge[1])) {
totalWeight += edge[2];
edgeCount++;
if (edgeCount == n - 1) break; // 最小生成树有 n-1 条边
}
}
return edgeCount == n - 1 ? totalWeight : -1;
}
3. 回溯算法
组合问题
/**
* 组合问题:从 n 个数中选 k 个数的所有组合
* 例如:n=4, k=2 -> [[1,2],[1,3],[1,4],[2,3],[2,4],[3,4]]
*/
List<List<Integer>> combine(int n, int k) {
List<List<Integer>> res = new ArrayList<>();
backtrack(res, new ArrayList<>(), 1, n, k);
return res;
}
void backtrack(List<List<Integer>> res, List<Integer> path, int start, int n, int k) {
// 递归终止条件:已选择 k 个数
if (path.size() == k) {
res.add(new ArrayList<>(path)); // 注意:要复制一份
return;
}
// 从 start 开始枚举,避免重复
for (int i = start; i <= n; i++) {
path.add(i); // 做选择
backtrack(res, path, i + 1, n, k); // 递归
path.remove(path.size() - 1); // 撤销选择(回溯)
}
}
全排列
/**
* 全排列问题:给定数组,返回所有可能的排列
* 例如:[1,2,3] -> [[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
*/
List<List<Integer>> permute(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
backtrack(res, new ArrayList<>(), nums, new boolean[nums.length]);
return res;
}
void backtrack(List<List<Integer>> res, List<Integer> path, int[] nums, boolean[] used) {
// 递归终止条件:所有数字都已使用
if (path.size() == nums.length) {
res.add(new ArrayList<>(path));
return;
}
// 枚举所有数字
for (int i = 0; i < nums.length; i++) {
if (used[i]) continue; // 已使用过,跳过
path.add(nums[i]); // 做选择
used[i] = true; // 标记已使用
backtrack(res, path, nums, used); // 递归
used[i] = false; // 撤销标记(回溯)
path.remove(path.size() - 1); // 撤销选择(回溯)
}
}
子集问题
/**
* 子集问题:返回数组的所有子集(幂集)
* 例如:[1,2,3] -> [[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
*/
List<List<Integer>> subsets(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
backtrack(res, new ArrayList<>(), nums, 0);
return res;
}
void backtrack(List<List<Integer>> res, List<Integer> path, int[] nums, int start) {
// 每个状态都是一个子集
res.add(new ArrayList<>(path));
// 枚举后续元素
for (int i = start; i < nums.length; i++) {
path.add(nums[i]); // 做选择
backtrack(res, path, nums, i + 1); // 递归
path.remove(path.size() - 1); // 撤销选择(回溯)
}
}
N 皇后问题
/**
* N皇后问题:在 n×n 的棋盘上放置 n 个皇后,使它们互不攻击
* 规则:任意两个皇后不能在同一行、同一列、同一对角线
*/
List<List<String>> solveNQueens(int n) {
List<List<String>> res = new ArrayList<>();
char[][] board = new char[n][n];
// 初始化棋盘:'.' 表示空位
for (int i = 0; i < n; i++) {
Arrays.fill(board[i], '.');
}
backtrack(res, board, 0);
return res;
}
void backtrack(List<List<String>> res, char[][] board, int row) {
// 递归终止条件:所有行都放置完成
if (row == board.length) {
res.add(construct(board)); // 将棋盘转换为字符串列表
return;
}
// 尝试在当前行的每一列放置皇后
for (int col = 0; col < board.length; col++) {
if (!isValid(board, row, col)) continue; // 不合法,跳过
board[row][col] = 'Q'; // 放置皇后
backtrack(res, board, row + 1); // 递归下一行
board[row][col] = '.'; // 撤销放置(回溯)
}
}
// 检查在 (row, col) 位置放置皇后是否合法
boolean isValid(char[][] board, int row, int col) {
int n = board.length;
// 检查列:同一列不能有其他皇后
for (int i = 0; i < row; i++) {
if (board[i][col] == 'Q') return false;
}
// 检查左上对角线
for (int i = row - 1, j = col - 1; i >= 0 && j >= 0; i--, j--) {
if (board[i][j] == 'Q') return false;
}
// 检查右上对角线
for (int i = row - 1, j = col + 1; i >= 0 && j < n; i--, j++) {
if (board[i][j] == 'Q') return false;
}
return true;
}
// 将棋盘转换为字符串列表
List<String> construct(char[][] board) {
List<String> res = new ArrayList<>();
for (char[] row : board) {
res.add(new String(row));
}
return res;
}
4. 动态规划
0-1 背包问题
/**
* 0-1背包:每个物品只能选一次
* weights[i]: 第i个物品的重量
* values[i]: 第i个物品的价值
* capacity: 背包容量
* 返回:最大价值
*/
int knapsack(int[] weights, int[] values, int capacity) {
int n = weights.length;
// dp[i][w] 表示前 i 个物品,背包容量为 w 时的最大价值
int[][] dp = new int[n + 1][capacity + 1];
for (int i = 1; i <= n; i++) {
for (int w = 0; w <= capacity; w++) {
// 如果当前物品的重量 <= 背包容量
if (weights[i - 1] <= w) {
// 选择:max(不拿, 拿)
dp[i][w] = Math.max(
dp[i - 1][w], // 不拿第i个物品
dp[i - 1][w - weights[i - 1]] + values[i - 1] // 拿第i个物品
);
} else {
// 放不下,只能不拿
dp[i][w] = dp[i - 1][w];
}
}
}
return dp[n][capacity];
}
/**
* 0-1背包 - 空间优化版本
* 时间复杂度:O(n * capacity)
* 空间复杂度:O(capacity)
*/
int knapsackOptimized(int[] weights, int[] values, int capacity) {
int[] dp = new int[capacity + 1];
for (int i = 0; i < weights.length; i++) {
// 注意:必须从后往前遍历,避免重复使用同一物品
for (int w = capacity; w >= weights[i]; w--) {
dp[w] = Math.max(dp[w], dp[w - weights[i]] + values[i]);
}
}
return dp[capacity];
}
完全背包问题
/**
* 完全背包:每个物品可以选无限次
* 与0-1背包的区别:内层循环从前往后遍历
*/
int completeKnapsack(int[] weights, int[] values, int capacity) {
int[] dp = new int[capacity + 1];
for (int i = 0; i < weights.length; i++) {
// 注意:从前往后遍历,允许重复使用物品
for (int w = weights[i]; w <= capacity; w++) {
dp[w] = Math.max(dp[w], dp[w - weights[i]] + values[i]);
}
}
return dp[capacity];
}
最长公共子序列(LCS)
/**
* 最长公共子序列:找两个字符串的最长公共子序列长度
* 子序列:不要求连续
* 例如:"abcde" 和 "ace" 的LCS是 "ace",长度为3
*/
int longestCommonSubsequence(String text1, String text2) {
int m = text1.length(), n = text2.length();
// dp[i][j] 表示 text1[0..i-1] 和 text2[0..j-1] 的LCS长度
int[][] dp = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (text1.charAt(i - 1) == text2.charAt(j - 1)) {
// 字符相同:LCS长度+1
dp[i][j] = dp[i - 1][j - 1] + 1;
} else {
// 字符不同:取两种情况的最大值
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
return dp[m][n];
}
最长递增子序列(LIS)
/**
* 最长递增子序列 - O(n²) 动态规划解法
* dp[i] 表示以 nums[i] 结尾的最长递增子序列长度
*/
int lengthOfLIS(int[] nums) {
int n = nums.length;
int[] dp = new int[n];
Arrays.fill(dp, 1); // 初始每个元素自己构成长度为1的子序列
int maxLen = 1;
for (int i = 1; i < n; i++) {
for (int j = 0; j < i; j++) {
// 如果 nums[i] 可以接在 nums[j] 后面
if (nums[i] > nums[j]) {
dp[i] = Math.max(dp[i], dp[j] + 1);
}
}
maxLen = Math.max(maxLen, dp[i]);
}
return maxLen;
}
/**
* 最长递增子序列 - O(n log n) 二分解法
* tails[i] 表示长度为 i+1 的递增子序列的最小尾部元素
*/
int lengthOfLISBinary(int[] nums) {
List<Integer> tails = new ArrayList<>();
for (int num : nums) {
// 二分查找:找到第一个 >= num 的位置
int left = 0, right = tails.size();
while (left < right) {
int mid = left + (right - left) / 2;
if (tails.get(mid) < num) {
left = mid + 1;
} else {
right = mid;
}
}
// 如果 num 比所有元素都大,追加到末尾
if (left == tails.size()) {
tails.add(num);
} else {
// 否则替换找到的位置
tails.set(left, num);
}
}
return tails.size();
}
编辑距离
/**
* 编辑距离:将 word1 转换为 word2 的最少操作次数
* 操作:插入、删除、替换
* 例如:"horse" -> "ros" 需要3步(删除h、删除r、替换s)
*/
int minDistance(String word1, String word2) {
int m = word1.length(), n = word2.length();
// dp[i][j] 表示 word1[0..i-1] 转换为 word2[0..j-1] 的最少操作数
int[][] dp = new int[m + 1][n + 1];
// 边界条件:一个字符串为空
for (int i = 0; i <= m; i++) dp[i][0] = i; // word1 -> 空串:删除i个字符
for (int j = 0; j <= n; j++) dp[0][j] = j; // 空串 -> word2:插入j个字符
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
// 字符相同:不需要操作
dp[i][j] = dp[i - 1][j - 1];
} else {
// 字符不同:三种操作取最小
dp[i][j] = Math.min(
Math.min(
dp[i - 1][j], // 删除 word1[i-1]
dp[i][j - 1] // 插入 word2[j-1]
),
dp[i - 1][j - 1] // 替换 word1[i-1] 为 word2[j-1]
) + 1;
}
}
}
return dp[m][n];
}
股票买卖问题
只能买卖一次
/**
* 买卖股票的最佳时机 I:只能买卖一次
* 贪心思想:记录最低价格,计算每天卖出的最大利润
*/
int maxProfit(int[] prices) {
int minPrice = Integer.MAX_VALUE; // 记录目前为止的最低价格
int maxProfit = 0; // 记录最大利润
for (int price : prices) {
minPrice = Math.min(minPrice, price);
maxProfit = Math.max(maxProfit, price - minPrice);
}
return maxProfit;
}
可以买卖多次
/**
* 买卖股票的最佳时机 II:可以买卖多次
* 贪心思想:只要今天价格比昨天高,就在昨天买今天卖
*/
int maxProfitMultiple(int[] prices) {
int profit = 0;
for (int i = 1; i < prices.length; i++) {
// 如果今天价格更高,累加差价
if (prices[i] > prices[i - 1]) {
profit += prices[i] - prices[i - 1];
}
}
return profit;
}
最多买卖 k 次
/**
* 买卖股票的最佳时机 III/IV:最多买卖 k 次
* dp[i][j] 表示第 i 次交易后,第 j 天的最大利润
*/
int maxProfitK(int k, int[] prices) {
if (prices.length == 0) return 0;
int n = prices.length;
// 如果 k >= n/2,相当于无限次交易
if (k >= n / 2) {
int profit = 0;
for (int i = 1; i < n; i++) {
if (prices[i] > prices[i - 1]) {
profit += prices[i] - prices[i - 1];
}
}
return profit;
}
int[][] dp = new int[k + 1][n];
for (int i = 1; i <= k; i++) {
int maxDiff = -prices[0]; // 第 i-1 次交易后买入的最大收益
for (int j = 1; j < n; j++) {
// 不操作 vs 卖出
dp[i][j] = Math.max(dp[i][j - 1], prices[j] + maxDiff);
// 更新买入的最大收益
maxDiff = Math.max(maxDiff, dp[i - 1][j] - prices[j]);
}
}
return dp[k][n - 1];
}
打家劫舍
/**
* 打家劫舍 I:线性排列的房屋
* 不能抢相邻的房屋
* dp[i] = max(dp[i-1], dp[i-2] + nums[i])
*/
int rob(int[] nums) {
if (nums.length == 0) return 0;
if (nums.length == 1) return nums[0];
int prev2 = 0, prev1 = 0; // prev2: dp[i-2], prev1: dp[i-1]
for (int num : nums) {
int temp = prev1;
// 不抢 vs 抢
prev1 = Math.max(prev1, prev2 + num);
prev2 = temp;
}
return prev1;
}
/**
* 打家劫舍 II:环形排列的房屋
* 第一个和最后一个房屋相邻
* 思路:分两种情况,取最大值
* 1. 抢第一个房屋,不抢最后一个
* 2. 不抢第一个房屋,抢最后一个
*/
int robCircular(int[] nums) {
if (nums.length == 1) return nums[0];
return Math.max(
robRange(nums, 0, nums.length - 2),
robRange(nums, 1, nums.length - 1)
);
}
int robRange(int[] nums, int start, int end) {
int prev2 = 0, prev1 = 0;
for (int i = start; i <= end; i++) {
int temp = prev1;
prev1 = Math.max(prev1, prev2 + nums[i]);
prev2 = temp;
}
return prev1;
}
分割等和子集
/**
* 分割等和子集:判断是否能将数组分成两个和相等的子集
* 本质:0-1背包问题,目标是找到和为 sum/2 的子集
*/
boolean canPartition(int[] nums) {
int sum = 0;
for (int num : nums) sum += num;
if (sum % 2 != 0) return false; // 和为奇数,不可能分割
int target = sum / 2;
// dp[j] 表示能否凑出和为 j
boolean[] dp = new boolean[target + 1];
dp[0] = true; // 和为0总是可以(不选任何数)
for (int num : nums) {
// 从后往前遍历,避免重复使用
for (int j = target; j >= num; j--) {
dp[j] = dp[j] || dp[j - num]; // 不选 num 或 选 num
}
}
return dp[target];
}
零钱兑换
/**
* 零钱兑换 I:最少硬币数
* dp[i] 表示凑出金额 i 所需的最少硬币数
*/
int coinChange(int[] coins, int amount) {
int[] dp = new int[amount + 1];
Arrays.fill(dp, amount + 1); // 初始化为不可能的大值
dp[0] = 0; // 凑出0元需要0个硬币
for (int i = 1; i <= amount; i++) {
for (int coin : coins) {
if (i >= coin) {
// 选择使用当前硬币
dp[i] = Math.min(dp[i], dp[i - coin] + 1);
}
}
}
return dp[amount] > amount ? -1 : dp[amount];
}
/**
* 零钱兑换 II:组成方案数
* dp[i] 表示凑出金额 i 的方案数
*/
int change(int amount, int[] coins) {
int[] dp = new int[amount + 1];
dp[0] = 1; // 凑出0元有1种方案(不选)
// 外层遍历硬币,内层遍历金额(避免重复计数)
for (int coin : coins) {
for (int i = coin; i <= amount; i++) {
dp[i] += dp[i - coin];
}
}
return dp[amount];
}
5. 双指针
对撞指针
// 两数之和(有序数组)
int[] twoSum(int[] nums, int target) {
int left = 0, right = nums.length - 1;
while (left < right) {
int sum = nums[left] + nums[right];
if (sum == target) {
return new int[]{left, right};
} else if (sum < target) {
left++;
} else {
right--;
}
}
return new int[]{-1, -1};
}
// 三数之和
List<List<Integer>> threeSum(int[] nums) {
List<List<Integer>> res = new ArrayList<>();
Arrays.sort(nums);
for (int i = 0; i < nums.length - 2; i++) {
if (i > 0 && nums[i] == nums[i - 1]) continue;
int left = i + 1, right = nums.length - 1;
while (left < right) {
int sum = nums[i] + nums[left] + nums[right];
if (sum == 0) {
res.add(Arrays.asList(nums[i], nums[left], nums[right]));
while (left < right && nums[left] == nums[left + 1]) left++;
while (left < right && nums[right] == nums[right - 1]) right--;
left++;
right--;
} else if (sum < 0) {
left++;
} else {
right--;
}
}
}
return res;
}
快慢指针
// 链表中点
ListNode findMiddle(ListNode head) {
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}
// 环形链表
boolean hasCycle(ListNode head) {
if (head == null) return false;
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) return true;
}
return false;
}
// 找环的入口
ListNode detectCycle(ListNode head) {
ListNode slow = head, fast = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
slow = head;
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
return slow;
}
}
return null;
}
6. 单调栈
// 下一个更大元素
int[] nextGreaterElement(int[] nums) {
int n = nums.length;
int[] res = new int[n];
Arrays.fill(res, -1);
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < n; i++) {
while (!stack.isEmpty() && nums[stack.peek()] < nums[i]) {
int idx = stack.pop();
res[idx] = nums[i];
}
stack.push(i);
}
return res;
}
// 每日温度
int[] dailyTemperatures(int[] temperatures) {
int n = temperatures.length;
int[] res = new int[n];
Stack<Integer> stack = new Stack<>();
for (int i = 0; i < n; i++) {
while (!stack.isEmpty() && temperatures[stack.peek()] < temperatures[i]) {
int idx = stack.pop();
res[idx] = i - idx;
}
stack.push(i);
}
return res;
}
// 柱状图中最大的矩形
int largestRectangleArea(int[] heights) {
Stack<Integer> stack = new Stack<>();
stack.push(-1);
int maxArea = 0;
for (int i = 0; i < heights.length; i++) {
while (stack.peek() != -1 && heights[stack.peek()] >= heights[i]) {
int h = heights[stack.pop()];
int w = i - stack.peek() - 1;
maxArea = Math.max(maxArea, h * w);
}
stack.push(i);
}
while (stack.peek() != -1) {
int h = heights[stack.pop()];
int w = heights.length - stack.peek() - 1;
maxArea = Math.max(maxArea, h * w);
}
return maxArea;
}
7. 前缀和
// 一维前缀和
class PrefixSum {
private int[] preSum;
public PrefixSum(int[] nums) {
preSum = new int[nums.length + 1];
for (int i = 0; i < nums.length; i++) {
preSum[i + 1] = preSum[i] + nums[i];
}
}
// 查询区间 [left, right] 的和
public int query(int left, int right) {
return preSum[right + 1] - preSum[left];
}
}
// 二维前缀和
class MatrixPrefixSum {
private int[][] preSum;
public MatrixPrefixSum(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
preSum = new int[m + 1][n + 1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
preSum[i][j] = preSum[i - 1][j] + preSum[i][j - 1]
- preSum[i - 1][j - 1] + matrix[i - 1][j - 1];
}
}
}
// 查询子矩阵 [row1, col1] 到 [row2, col2] 的和
public int query(int row1, int col1, int row2, int col2) {
return preSum[row2 + 1][col2 + 1]
- preSum[row1][col2 + 1]
- preSum[row2 + 1][col1]
+ preSum[row1][col1];
}
}
📌 总结
这份文档涵盖了:
- Java 集合框架:List、Set、Map、Queue、Stack 的完整使用方法
- 树算法:DFS、BFS、线段树
- 图算法:遍历、最短路径、最小生成树
- 经典算法:回溯、动态规划、二分查找、滑动窗口、双指针、单调栈、前缀和
建议配合 LeetCode 刷题使用,遇到问题时可以快速查阅对应的模板代码。
持续更新中… 🚀