参考资料:机器学习考题集
机器学习基础(30%)
第一题:线性回归梯度下降
题目: 对线性模型 $h_\theta(x) = \theta^\top x$,给定训练集 $\{(x^{(i)}, y^{(i)})\}$,推导其向量形式的最小二乘损失梯度下降更新公式为:
$$\theta := \theta + \alpha \sum_{i=1}^{n} (y^{(i)} - h_\theta(x^{(i)})) x^{(i)}$$解:
最小二乘损失函 数为:
$$J(\theta) = \frac{1}{2}\sum_{i=1}^{n}(h_\theta(x^{(i)}) - y^{(i)})^2 = \frac{1}{2}\sum_{i=1}^{n}(\theta^\top x^{(i)} - y^{(i)})^2$$对 $\theta$ 求梯度:
$$\begin{aligned} \nabla_\theta J(\theta) &= \sum_{i=1}^{n}(\theta^\top x^{(i)} - y^{(i)}) \cdot x^{(i)} \\ &= \sum_{i=1}^{n}(h_\theta(x^{(i)}) - y^{(i)}) x^{(i)} \end{aligned}$$梯度下降更新规则为 $\theta := \theta - \alpha \nabla_\theta J(\theta)$,因此:
$$\theta := \theta - \alpha \sum_{i=1}^{n}(h_\theta(x^{(i)}) - y^{(i)}) x^{(i)} = \theta + \alpha \sum_{i=1}^{n}(y^{(i)} - h_\theta(x^{(i)})) x^{(i)}$$第二题:交叉熵损失梯度
题目: Cross Entropy Loss 定义如下:
$$l_{ce}((t_1,\ldots,t_k),y) = -\log\left(\frac{\exp(t_y)}{\sum_j \exp(t_j)}\right)$$令向量 $t = (t_1,t_2,\ldots,t_k)$,推导 CEL 对任意 $t_i$ 求导为:
$$\frac{\partial l_{ce}(t,y)}{\partial t_i} = \phi_i - \mathbb{1}\{y=i\}$$解:
记 $\phi_i = \frac{\exp(t_i)}{\sum_j \exp(t_j)}$ 为 softmax 函数。
首先简化损失函数:
$$l_{ce}(t,y) = -\log(\phi_y) = -t_y + \log\left(\sum_j \exp(t_j)\right)$$对 $t_i$ 求导:
$$\begin{aligned} \frac{\partial l_{ce}(t,y)}{\partial t_i} &= -\frac{\partial t_y}{\partial t_i} + \frac{\partial}{\partial t_i}\log\left(\sum_j \exp(t_j)\right) \\ &= -\mathbb{1}\{y=i\} + \frac{\exp(t_i)}{\sum_j \exp(t_j)} \\ &= \phi_i - \mathbb{1}\{y=i\} \end{aligned}$$其中 $\mathbb{1}\{y=i\}$ 是指示函数,当 $y=i$ 时为1,否则为0。
第三题:高斯假设下的最大似然估计
题目: 证明在高斯差异假定下,对线性模型 $h_\theta(x) = \theta^\top x$,最大化参数似然 $L(\theta)$ 等价于最小化二乘损失 $\sum_{i=1}^{n}(y^{(i)} - \theta^\top x^{(i)})^2$。
解:
假设误差 $\epsilon^{(i)} = y^{(i)} - \theta^\top x^{(i)}$ 服从独立同分布的高斯分布 $\mathcal{N}(0, \sigma^2)$,即:
$$ p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\right) $$因此:
$$p(y^{(i)} | x^{(i)}; \theta) = \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)} - \theta^\top x^{(i)})^2}{2\sigma^2}\right)$$似然函数为:
$$\begin{aligned} L(\theta) &= \prod_{i=1}^{n} p(y^{(i)} | x^{(i)}; \theta) \\ &= \prod_{i=1}^{n} \frac{1}{\sqrt{2\pi}\sigma}\exp\left(-\frac{(y^{(i)} - \theta^\top x^{(i)})^2}{2\sigma^2}\right) \end{aligned}$$对数似然为:
$$\begin{aligned} \log L(\theta) &= \sum_{i=1}^{n}\left[\log\frac{1}{\sqrt{2\pi}\sigma} - \frac{(y^{(i)} - \theta^\top x^{(i)})^2}{2\sigma^2}\right] \\ &= n\log\frac{1}{\sqrt{2\pi}\sigma} - \frac{1}{2\sigma^2}\sum_{i=1}^{n}(y^{(i)} - \theta^\top x^{(i)})^2 \end{aligned}$$因此最大化 $L(\theta)$ 等价于最小化 $\sum_{i=1}^{n}(y^{(i)} - \theta^\top x^{(i)})^2$。
第四题:Logistic回归的NLL损失
题目: 对Logistic回归模型 $h_\theta(x) = g(\theta^\top x) = \frac{1}{1+e^{-\theta^\top x}}$,推导其在单样本 $(x,y)$ 下的NLL(negative log likelihood)损失,以及损失对特定参数 $\theta_j$ 的导数为 $(h_\theta(x) - y)x_j$。
提示:Logistic回归预测概率的统一形式为 $P(y|x;\theta) = (h_\theta(x))^y(1-h_\theta(x))^{1-y}$
解:
根据提示,Logistic回归的概率模型为:
$$P(y|x;\theta) = (h_\theta(x))^y(1-h_\theta(x))^{1-y}$$其中 $y \in \{0,1\}$,$h_\theta(x) = g(\theta^\top x) = \frac{1}{1+e^{-\theta^\top x}}$。
对数似然为:
$$\log P(y|x;\theta) = y\log(h_\theta(x)) + (1-y)\log(1-h_\theta(x))$$NLL损失为:
$$\text{NLL}(x,y;\theta) = -\log P(y|x;\theta) = -y\log(h_\theta(x)) - (1-y)\log(1-h_\theta(x))$$对 $\theta_j$ 求导。首先注意到:
$$\frac{\partial h_\theta(x)}{\partial \theta_j} = h_\theta(x)(1-h_\theta(x)) \cdot x_j$$这是因为 $g'(z) = g(z)(1-g(z))$。
因此:
$$\begin{aligned} \frac{\partial \text{NLL}}{\partial \theta_j} &= -y\frac{1}{h_\theta(x)}\frac{\partial h_\theta(x)}{\partial \theta_j} - (1-y)\frac{1}{1-h_\theta(x)}\left(-\frac{\partial h_\theta(x)}{\partial \theta_j}\right) \\ &= -y\frac{1}{h_\theta(x)} \cdot h_\theta(x)(1-h_\theta(x))x_j + (1-y)\frac{1}{1-h_\theta(x)} \cdot h_\theta(x)(1-h_\theta(x))x_j \\ &= -y(1-h_\theta(x))x_j + (1-y)h_\theta(x)x_j \\ &= (h_\theta(x) - y)x_j \end{aligned}$$第五题:Poisson分布的指数族形式
题目: 已知指数分布族定义如下:$p(y;\eta) = b(y)\exp(\eta^\top y - a(\eta))$。推导Poisson分布的指数分布族形式,并构建Poisson分布对应的广义线性模型。其中,Poisson分布 $\text{Pois}(\lambda)$ 的概率密度函数如下:
$$P(X=k) = \frac{\lambda^k e^{-\lambda}}{k!}$$解:
将Poisson分布改写为指数族形式:
$$\begin{aligned} P(X=k) &= \frac{\lambda^k e^{-\lambda}}{k!} \\ &= \frac{1}{k!}\exp(k\log\lambda - \lambda) \\ &= \frac{1}{k!}\exp(\eta \cdot k - e^\eta) \end{aligned}$$其中 $\eta = \log\lambda$(自然参数),因此 $\lambda = e^\eta$。
对应指数族形式:
- $b(y) = \frac{1}{y!}$
- $\eta = \log\lambda$
- $a(\eta) = e^\eta = \lambda$
- $y$ 的充分统计量就是 $y$ 本身
构建广义线性模型:
- 假设 $y|x;\theta \sim \text{Pois}(\lambda)$
- 自然参数 $\eta = \theta^\top x$
- 因为 $\lambda = e^\eta$,所以 $\lambda = e^{\theta^\top x}$
- 响应函数(期望)为:$h_\theta(x) = \mathbb{E}[y|x;\theta] = \lambda = e^{\theta^\top x}$
这就是Poisson回归模型。
第六题:Shapley值计算
题目: 计算以下3人团队的Shapley值 $\phi_1$、$\phi_2$、$\phi_3$。
给定:
- $C_{123} = 10000$,$C_0 = 0$
- $C_{12} = 7500$,$C_{13} = 7500$,$C_{23} = 5000$
- $C_1 = 5000$,$C_2 = 5000$,$C_3 = 0$
解:
Shapley值的公式为:
$$\phi_i = \sum_{S \subseteq N \setminus \{i\}} \frac{|S|!(|N|-|S|-1)!}{|N|!}[C(S \cup \{i\}) - C(S)]$$对于3人团队,$|N| = 3$,计算每个玩家的边际贡献:
玩家1的Shapley值:
$$\begin{aligned} \phi_1 &= \frac{0!2!}{3!}[C_1 - C_0] + \frac{1!1!}{3!}[C_{12} - C_2] + \frac{1!1!}{3!}[C_{13} - C_3] + \frac{2!0!}{3!}[C_{123} - C_{23}] \\ &= \frac{1}{3}[5000 - 0] + \frac{1}{6}[7500 - 5000] + \frac{1}{6}[7500 - 0] + \frac{1}{3}[10000 - 5000] \\ &= \frac{5000}{3} + \frac{2500}{6} + \frac{7500}{6} + \frac{5000}{3} \\ &= \frac{10000}{3} + \frac{10000}{6} = \frac{20000 + 10000}{6} = 5000 \end{aligned}$$玩家2的Shapley值:
$$\begin{aligned} \phi_2 &= \frac{0!2!}{3!}[C_2 - C_0] + \frac{1!1!}{3!}[C_{12} - C_1] + \frac{1!1!}{3!}[C_{23} - C_3] + \frac{2!0!}{3!}[C_{123} - C_{13}] \\ &= \frac{1}{3}[5000 - 0] + \frac{1}{6}[7500 - 5000] + \frac{1}{6}[5000 - 0] + \frac{1}{3}[10000 - 7500] \\ &= \frac{5000}{3} + \frac{2500}{6} + \frac{5000}{6} + \frac{2500}{3} \\ &= \frac{10000 + 2500 + 5000 + 5000}{6} = \frac{22500}{6} =3750 \end{aligned}$$玩家3的Shapley值:
由对称性或直接计算:
$$\phi_3 = 10000 - \phi_1 - \phi_2 = 10000 - 5000 - 4583.33 = 416.67$$或直接计算:
$$\begin{aligned} \phi_3 &= \frac{1}{3}[0] + \frac{1}{6}[7500 - 5000] + \frac{1}{6}[5000 - 5000] + \frac{1}{3}[10000 - 7500] \\ &= 0 + \frac{2500}{6} + 0 + \frac{2500}{3} = \frac{7500}{6} =1250 \end{aligned}$$答案: $\phi_1 = 5000$,$\phi_2 = 3750$,$\phi_3 $=1250
第七题:协方差矩阵性质
题目: 基于协方差矩阵定义 $\Sigma = \text{Cov}(X)$ 证明:
- $\Sigma$ 为对称矩阵;
- $\Sigma$ 半正定,记 $\Sigma \geq 0$,即对任意向量 $z \in \mathbb{R}^d$ 有 $z^\top \Sigma z \geq 0$。
解:
设 $X \in \mathbb{R}^d$ 为随机向量,$\mu = \mathbb{E}[X]$,则:
$$\Sigma = \text{Cov}(X) = \mathbb{E}[(X-\mu)(X-\mu)^\top]$$(1) 证明 $\Sigma$ 为对称矩阵:
$$\Sigma^\top = \mathbb{E}[(X-\mu)(X-\mu)^\top]^\top = \mathbb{E}[((X-\mu)(X-\mu)^\top)^\top] = \mathbb{E}[(X-\mu)(X-\mu)^\top] = \Sigma$$因此 $\Sigma$ 是对称矩阵。
(2) 证明 $\Sigma$ 半正定:
对任意 $z \in \mathbb{R}^d$:
$$\begin{aligned} z^\top \Sigma z &= z^\top \mathbb{E}[(X-\mu)(X-\mu)^\top] z \\ &= \mathbb{E}[z^\top(X-\mu)(X-\mu)^\top z] \\ &= \mathbb{E}[(z^\top(X-\mu))^2] \\ &\geq 0 \end{aligned}$$最后一步是因为期望中的项是平方项,必然非负。因此 $\Sigma$ 半正定。
第八题:高斯判别分析的MLE
题目: 对高斯判别分析,已知各变量概率分布为:
$$\begin{aligned} p(y) &= \phi^y(1-\phi)^{1-y} \\ p(x|y=0) &= \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}}\exp\left(-\frac{1}{2}(x-\mu_0)^\top\Sigma^{-1}(x-\mu_0)\right) \\ p(x|y=1) &= \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}}\exp\left(-\frac{1}{2}(x-\mu_1)^\top\Sigma^{-1}(x-\mu_1)\right) \end{aligned}$$证明在极大似然估计下,参数 $\phi$、$\mu_0$、$\mu_1$ 的形式为:
$$\begin{aligned} \phi &= \frac{1}{n}\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=1\} \\ \mu_0 &= \frac{\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=0\}x^{(i)}}{\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=0\}} \\ \mu_1 &= \frac{\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=1\}x^{(i)}}{\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=1\}} \end{aligned}$$解:
对数似然函数为:
$$\log L = \sum_{i=1}^{n}\left[\log p(y^{(i)}) + \log p(x^{(i)}|y^{(i)})\right]$$参数估计的分离性:
对数似然可以分解为两个独立的部分:
$$\log L = \underbrace{\sum_{i=1}^{n}\log p(y^{(i)})}_{\text{第一部分}} + \underbrace{\sum_{i=1}^{n}\log p(x^{(i)}|y^{(i)})}_{\text{第二部分}}$$- 第一部分 $\sum_{i=1}^{n}\log p(y^{(i)})$:只包含参数 $\phi$,用于估计类先验概率 $\phi$
- 第二部分 $\sum_{i=1}^{n}\log p(x^{(i)}|y^{(i)})$:包含参数 $\mu_0, \mu_1, \Sigma$,用于估计类条件均值 $\mu_0, \mu_1$ 和协方差矩阵 $\Sigma$
由于这两部分不包含共同参数,可以分别独立优化。
估计 $\phi$:
$$\log L_\phi = \sum_{i=1}^{n}\log p(y^{(i)}) = \sum_{i=1}^{n}[y^{(i)}\log\phi + (1-y^{(i)})\log(1-\phi)]$$令 $\frac{\partial \log L_\phi}{\partial \phi} = 0$:
$$\sum_{i=1}^{n}\left[\frac{y^{(i)}}{\phi} - \frac{1-y^{(i)}}{1-\phi}\right] = 0$$解得:
$$\phi = \frac{1}{n}\sum_{i=1}^{n}y^{(i)} = \frac{1}{n}\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=1\}$$估计 $\mu_0$:
只考虑 $y=0$ 的样本:
$$\log L_{\mu_0} = \sum_{i:y^{(i)}=0}\left[-\frac{1}{2}(x^{(i)}-\mu_0)^\top\Sigma^{-1}(x^{(i)}-\mu_0) + \text{const}\right]$$令 $\frac{\partial \log L_{\mu_0}}{\partial \mu_0} = 0$:
$$\sum_{i:y^{(i)}=0}\Sigma^{-1}(x^{(i)}-\mu_0) = 0$$解得:
$$\mu_0 = \frac{\sum_{i:y^{(i)}=0}x^{(i)}}{\sum_{i:y^{(i)}=0}1} = \frac{\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=0\}x^{(i)}}{\sum_{i=1}^{n}\mathbb{1}\{y^{(i)}=0\}}$$同理可得 $\mu_1$ 的估计。
第九题:GDA可转化为Logistic回归
题目: 证明GDA可转化为Logistic回归。提示:
- $p(y=1|x) = \frac{p(x|y=1)p(y=1)}{p(x|y=1)p(y=1) + p(x|y=0)p(y=0)}$
- 可记 $r(x) = \frac{p(x|y=1)p(y=1)}{p(x|y=0)p(y=0)}$
- $ p(x|y=0) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}}\exp\left(-\frac{1}{2}(x-\mu_0)^\top\Sigma^{-1}(x-\mu_0)\right)$
- $p(x|y=1) = \frac{1}{(2\pi)^{d/2}|\Sigma|^{1/2}}\exp\left(-\frac{1}{2}(x-\mu_1)^\top\Sigma^{-1}(x-\mu_1)\right)$
- $p(y=1) = \phi$
解:
根据贝叶斯定理:
$$p(y=1|x) = \frac{p(x|y=1)p(y=1)}{p(x|y=1)p(y=1) + p(x|y=0)p(y=0)} = \frac{1}{1 + \frac{p(x|y=0)p(y=0)}{p(x|y=1)p(y=1)}} = \frac{1}{1 + \frac{1}{r(x)}}$$其中:
$$r(x) = \frac{p(x|y=1)p(y=1)}{p(x|y=0)p(y=0)}$$计算 $\log r(x)$:
$$\begin{aligned} \log r(x) &= \log p(x|y=1) + \log p(y=1) - \log p(x|y=0) - \log p(y=0) \\ &= -\frac{1}{2}(x-\mu_1)^\top\Sigma^{-1}(x-\mu_1) + \frac{1}{2}(x-\mu_0)^\top\Sigma^{-1}(x-\mu_0) + \log\frac{\phi}{1-\phi} \end{aligned}$$展开:
$$\begin{aligned} \log r(x) &= -\frac{1}{2}x^\top\Sigma^{-1}x + x^\top\Sigma^{-1}\mu_1 - \frac{1}{2}\mu_1^\top\Sigma^{-1}\mu_1 \\ &\quad + \frac{1}{2}x^\top\Sigma^{-1}x - x^\top\Sigma^{-1}\mu_0 + \frac{1}{2}\mu_0^\top\Sigma^{-1}\mu_0 + \log\frac{\phi}{1-\phi} \\ &= x^\top\Sigma^{-1}(\mu_1 - \mu_0) + \frac{1}{2}(\mu_0^\top\Sigma^{-1}\mu_0 - \mu_1^\top\Sigma^{-1}\mu_1) + \log\frac{\phi}{1-\phi} \\ &= \theta^\top x + \theta_0 \end{aligned}$$其中:
$$\theta = \Sigma^{-1}(\mu_1 - \mu_0), \quad \theta_0 = \frac{1}{2}(\mu_0^\top\Sigma^{-1}\mu_0 - \mu_1^\top\Sigma^{-1}\mu_1) + \log\frac{\phi}{1-\phi}$$因此:
$$p(y=1|x) = \frac{1}{1+e^{-\theta^\top x - \theta_0}} = \frac{1}{1+e^{-\tilde{\theta}^\top \tilde{x}}}$$这正是Logistic回归的形式(其中 $\tilde{x}$ 包含截距项)。
机器学习进阶(20%)
第十题:Kernel Method分析
题目: Kernel method中,若Kernel function $K(x,z) = (x^\top z + c)^2$,推导对应的feature mapping $\phi$,并讨论对于 $n$ 个样本一轮SGD,使用Kernel method和在feature map上的计算效率优化比。
提示:
- 基于feature map的参数更新方法为:$\theta := \theta + \alpha\sum_{i=1}^{n}(y^{(i)} - \theta^\top\phi(x^{(i)}))\phi(x^{(i)})$
- Kernel method的参数更新方法为:$\theta := \theta + \alpha(\tilde{y} - K\theta)$,其中 $K_j = K(x^{(i)}, x^{(j)})$
解:
推导Feature Mapping:
对于 $x, z \in \mathbb{R}^d$,展开核函数:
$$\begin{aligned} K(x,z) &= (x^\top z + c)^2 \\ &= (x^\top z)^2 + 2c(x^\top z) + c^2 \\ &= \sum_{i=1}^{d}\sum_{j=1}^{d} x_i x_j z_i z_j + 2c\sum_{i=1}^{d} x_i z_i + c^2 \end{aligned}$$为了使 $K(x,z) = \phi(x)^\top \phi(z)$,构造特征映射:
$$\phi(x) = (x_1^2, x_2^2, \ldots, x_d^2, \sqrt{2}x_1x_2, \sqrt{2}x_1x_3, \ldots, \sqrt{2}x_{d-1}x_d, \sqrt{2c}x_1, \ldots, \sqrt{2c}x_d, c)$$维度为:$d + \binom{d}{2} + d + 1 = d + \frac{d(d-1)}{2} + d + 1 = \frac{d(d+3)}{2} + 1 = O(d^2)$
计算效率比较:
-
Feature map方法:
- 计算 $\phi(x^{(i)})$:$O(d^2)$ 每个样本
- 内积 $\theta^\top\phi(x^{(i)})$:$O(d^2)$
- 更新 $\theta$:$O(d^2)$
- 总计:$O(nd^2)$ 每轮SGD
-
Kernel method:
- 计算核矩阵 $K$($n \times n$):$O(n^2d)$(每个核计算需要 $O(d)$ 的内积)
- 矩阵向量乘法 $K\theta$:$O(n^2)$
- 参数更新:$O(n)$
- 总计:$O(n^2d)$ 每轮
效率比:
$$\frac{\text{Feature map}}{\text{Kernel method}} = \frac{O(nd^2)}{O(n^2d)} = \frac{d}{n}$$- 当 $n \ll d$ 时(样本少,特征多),Kernel method更高效
- 当 $n \gg d$ 时(样本多,特征少),Feature map方法更高效
第十一题:超平面的函数间隔和几何间隔
题目: 对超平面 $w^\top x + b = 0$,样本 $x^{(i)}$ 到的函数间隔 $\hat{\gamma}^{(i)}$ 与几何间隔 $\gamma^{(i)}$ 满足何关系?直接给出答案即可。
解:
函数间隔定义为:
$$\hat{\gamma}^{(i)} = y^{(i)}(w^\top x^{(i)} + b)$$几何间隔定义为:
$\gamma^{(i)} = \frac{y^{(i)}(w^\top x^{(i)} + b)}{\|w\|} = \frac{\hat{\gamma}^{(i)}}{\|w\|}$
关系:
$\gamma^{(i)} = \frac{\hat{\gamma}^{(i)}}{\|w\|}$
几何间隔是函数间隔除以权重向量的范数,表示点到超平面的真实距离。
第十二题:SVM的Lagrange函数和对偶形式
题目: 已知SVM的优化目标为:
$$ \min_{w,b} \quad \frac{1}{2}\|w\|^2 \qquad (1) $$$$ \text{s.t.} \quad y^{(i)}(w^\top x^{(i)} + b) \geq 1, \quad i=1,\ldots,n $$请构造其Lagrange函数 $\mathcal{L}(w,b,\alpha)$。
已知 $\mathcal{L}(w,b,\alpha)$ 满足Slater条件,因此强对偶成立,问题(1)最终可转化为 $\max_{\alpha;\alpha_i\geq 0}\min_w \mathcal{L}(w,b,\alpha)$,证明该对偶形式问题可进一步转化为:
$$ \max_\alpha W(\alpha) = \max_\alpha \left(\sum_{i=1}^{n}\alpha_i - \frac{1}{2}\sum_{i,j=1}^{n}y^{(i)}y^{(j)}\alpha_i\alpha_j\langle x^{(i)}, x^{(j)}\rangle\right) \qquad (2) $$约束条件:
$$ \alpha_i \geq 0, \quad i=1,\ldots,n $$$$ \sum_{i=1}^{n}\alpha_i y^{(i)} = 0 $$解:
步骤1:构造Lagrange函数
$\mathcal{L}(w,b,\alpha) = \frac{1}{2}\|w\|^2 - \sum_{i=1}^{n}\alpha_i[y^{(i)}(w^\top x^{(i)} + b) - 1]$
其中 $\alpha_i \geq 0$ 为Lagrange乘子。
步骤2:固定 $\alpha$,对 $w$ 求导
$\frac{\partial \mathcal{L}}{\partial w} = w - \sum_{i=1}^{n}\alpha_i y^{(i)} x^{(i)} = 0$
因此:
$w = \sum_{i=1}^{n}\alpha_i y^{(i)} x^{(i)}$
步骤3:固定 $\alpha$,对 $b$ 求导
$\frac{\partial \mathcal{L}}{\partial b} = -\sum_{i=1}^{n}\alpha_i y^{(i)} = 0$
因此:
$\sum_{i=1}^{n}\alpha_i y^{(i)} = 0$
步骤4:代入Lagrange函数
将 $w = \sum_{i=1}^{n}\alpha_i y^{(i)} x^{(i)}$ 代入 $\mathcal{L}$:
$\begin{aligned} \mathcal{L}(w,b,\alpha) &= \frac{1}{2}w^\top w - \sum_{i=1}^{n}\alpha_i y^{(i)} w^\top x^{(i)} - b\sum_{i=1}^{n}\alpha_i y^{(i)} + \sum_{i=1}^{n}\alpha_i \\ &= \frac{1}{2}\left(\sum_{i=1}^{n}\alpha_i y^{(i)} x^{(i)}\right)^\top\left(\sum_{j=1}^{n}\alpha_j y^{(j)} x^{(j)}\right) - \sum_{i=1}^{n}\alpha_i y^{(i)} \left(\sum_{j=1}^{n}\alpha_j y^{(j)} x^{(j)}\right)^\top x^{(i)} + \sum_{i=1}^{n}\alpha_i \\ &= \frac{1}{2}\sum_{i,j=1}^{n}\alpha_i\alpha_j y^{(i)}y^{(j)}\langle x^{(i)}, x^{(j)}\rangle - \sum_{i,j=1}^{n}\alpha_i\alpha_j y^{(i)}y^{(j)}\langle x^{(i)}, x^{(j)}\rangle + \sum_{i=1}^{n}\alpha_i \\ &= \sum_{i=1}^{n}\alpha_i - \frac{1}{2}\sum_{i,j=1}^{n}\alpha_i\alpha_j y^{(i)}y^{(j)}\langle x^{(i)}, x^{(j)}\rangle \end{aligned}$
其中使用了 $\sum_{i=1}^{n}\alpha_i y^{(i)} = 0$,所以 $b$ 项消失。
因此对偶问题为:
$\max_\alpha W(\alpha) = \max_\alpha \left(\sum_{i=1}^{n}\alpha_i - \frac{1}{2}\sum_{i,j=1}^{n}y^{(i)}y^{(j)}\alpha_i\alpha_j\langle x^{(i)}, x^{(j)}\rangle\right)$
约束条件为:
$\begin{aligned} \alpha_i &\geq 0, \quad i=1,\ldots,n \\ \sum_{i=1}^{n}\alpha_i y^{(i)} &= 0 \end{aligned}$
第十三题:线性不可分的SVM与L1正则
题目: 对线性不可分的训练集,SVM对应带L1正则的优化目标是什么?已知对线性可分情况的优化为:
$$ \min_{w,b} \quad \frac{1}{2}\|w\|^2 \qquad (1) $$$$ \text{s.t.} \quad y^{(i)}(w^\top x^{(i)} + b) \geq 1, \quad i=1,\ldots,n $$
解:
对于线性不可分的情况,引入松弛变量 $\xi_i \geq 0$,允许某些样本违反间隔约束。
带L1正则的软间隔SVM优化目标为:
$\begin{aligned} \min_{w,b,\xi} &\quad \frac{1}{2}\|w\|^2 + C\sum_{i=1}^{n}\xi_i \\ \text{s.t.} &\quad y^{(i)}(w^\top x^{(i)} + b) \geq 1 - \xi_i, \quad i=1,\ldots,n \\ &\quad \xi_i \geq 0, \quad i=1,\ldots,n \end{aligned}$
其中:
- $\xi_i$ 是松弛变量,表示样本 $i$ 违反间隔的程度
- $C > 0$ 是惩罚参数,控制间隔最大化与违反程度之间的权衡
- $C\sum_{i=1}^{n}\xi_i$ 是L1正则项(对松弛变量的惩罚)
这个目标函数平衡了两个目标:
- 最大化间隔(通过最小化 $\|w\|^2$)
- 最小化分类错误(通过最小化 $\sum\xi_i$)
第十四题:SVM最优化问题分析
题目: 已知SVM的最终优化目标为:
$W(\alpha) = \sum_{i=1}^{n}\alpha_i - \frac{1}{2}\sum_{i,j=1}^{n}y^{(i)}y^{(j)}\alpha_i\alpha_j\langle x^{(i)}, x^{(j)}\rangle$
假设此时正在优化 $\alpha_1$ 与 $\alpha_2$,并有 $\alpha_1 = (\zeta - \alpha_2y^{(2)})y^{(1)}$。请推导此时 $\alpha_2$ 应当更新的值。
解:
简化目标函数:
在固定其他 $\alpha_i$ ($i \geq 3$) 的情况下,目标函数关于 $\alpha_1, \alpha_2$ 可写为:
$W(\alpha_1, \alpha_2) = \alpha_1 + \alpha_2 + W_0 - \frac{1}{2}[K_{11}\alpha_1^2 + K_{22}\alpha_2^2 + 2K_{12}\alpha_1\alpha_2y^{(1)}y^{(2)}] + \text{线性项}$
其中 $K_{ij} = \langle x^{(i)}, x^{(j)}\rangle$,$W_0$ 是常数项。
利用约束 $\alpha_1 = (\zeta - \alpha_2y^{(2)})y^{(1)}$:
这个约束来自 $\sum_{i=1}^{n}\alpha_i y^{(i)} = 0$,可以改写为:
$\alpha_1 y^{(1)} + \alpha_2 y^{(2)} = -\sum_{i=3}^{n}\alpha_i y^{(i)} = \zeta \quad \text{(常数)}$
将 $\alpha_1 = (\zeta - \alpha_2y^{(2)})y^{(1)}$ 代入目标函数,得到关于 $\alpha_2$ 的单变量优化问题。
对 $\alpha_2$ 求导并令其为0,经过复杂推导(涉及预测误差),得到 $\alpha_2$ 的无约束最优解:
$\alpha_2^{\text{new, unc}} = \alpha_2^{\text{old}} + \frac{y^{(2)}(E_1 - E_2)}{\eta}$
其中:
- $E_i = f(x^{(i)}) - y^{(i)}$ 是预测误差
- $\eta = K_{11} + K_{22} - 2K_{12} = \|x^{(1)} - x^{(2)}\|^2$(特征空间距离)
考虑约束 $0 \leq \alpha_2 \leq C$:
根据约束 $\alpha_1 y^{(1)} + \alpha_2 y^{(2)} = \zeta$:
- 若 $y^{(1)} \neq y^{(2)}$: $L = \max(0, \alpha_2^{\text{old}} - \alpha_1^{\text{old}}), \quad H = \min(C, C + \alpha_2^{\text{old}} - \alpha_1^{\text{old}})$
- 若 $y^{(1)} = y^{(2)}$: $L = \max(0, \alpha_1^{\text{old}} + \alpha_2^{\text{old}} - C), \quad H = \min(C, \alpha_1^{\text{old}} + \alpha_2^{\text{old}})$
最终更新公式:
$\alpha_2^{\text{new}} = \begin{cases} H & \text{if } \alpha_2^{\text{new, unc}} > H \\ \alpha_2^{\text{new, unc}} & \text{if } L \leq \alpha_2^{\text{new, unc}} \leq H \\ L & \text{if } \alpha_2^{\text{new, unc}} < L \end{cases}$
第十五题:信息增益比计算
题目: 计算给定数据集中四个特征的信息增益比。可保留log项,统一底数为2。
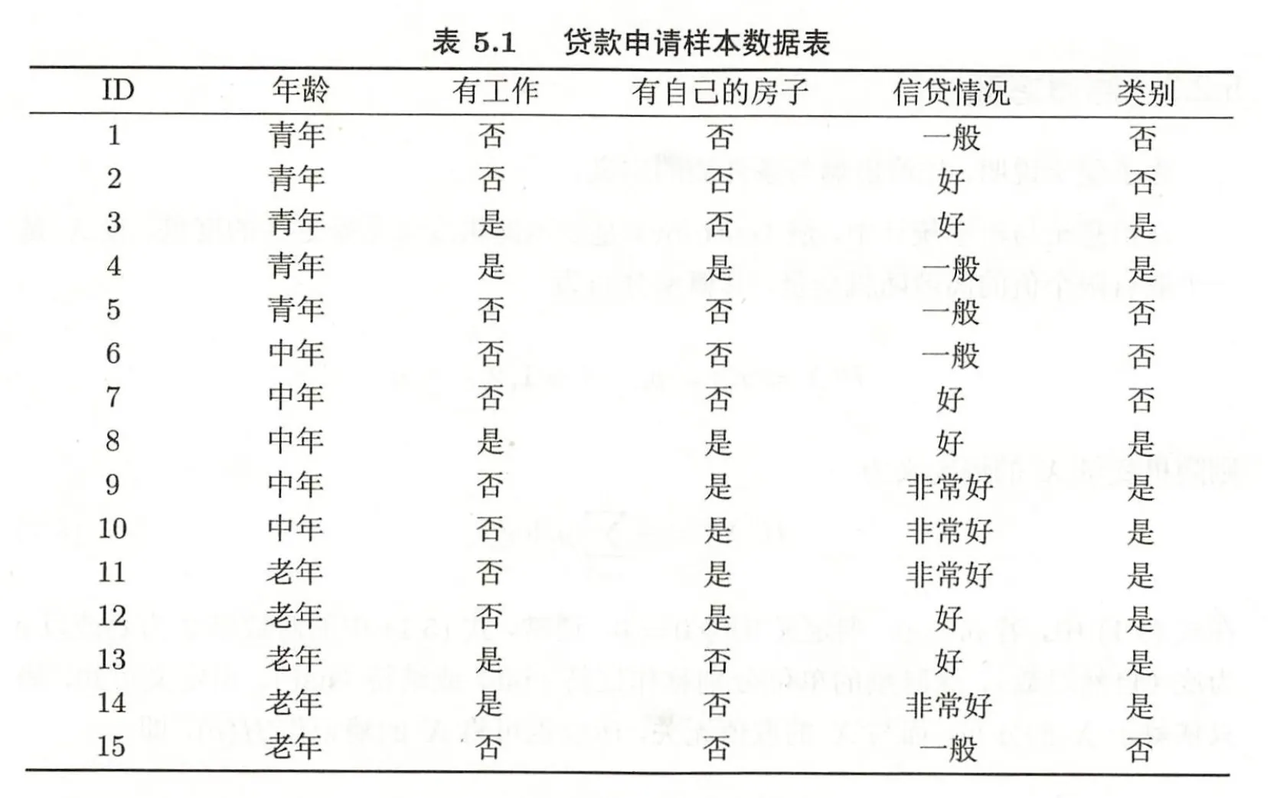
数据集的熵 H(D)
-
公式:
$$H(D) = -\sum_{k=1}^{K} \frac{|C_k|}{|D|} \log_2 \frac{|C_k|}{|D|}$$ -
计算:
$$H(D) = -\frac{6}{15}\log_2\frac{6}{15} - \frac{9}{15}\log_2\frac{9}{15} = 0.971$$
特征1:年龄
数据分布:
- 青年(5个):否=3,是=2
- 中年(5个):否=2,是=3
- 老年(5个):否=1,是=4
各子集的熵
- 青年组熵: $$H(D_1) = -\frac{3}{5}\log_2\frac{3}{5} - \frac{2}{5}\log_2\frac{2}{5} = 0.971$$
- 中年组熵: $$H(D_2) = -\frac{2}{5}\log_2\frac{2}{5} - \frac{3}{5}\log_2\frac{3}{5} = 0.971$$
- 老年组熵: $$H(D_3) = -\frac{1}{5}\log_2\frac{1}{5} - \frac{4}{5}\log_2\frac{4}{5} = 0.722$$
条件熵
-
公式:
$$H(D|\text{年龄}) = \sum_{i=1}^{3} \frac{|D_i|}{|D|} H(D_i)$$ -
计算:
$$ H(D \mid \text{年龄}) = \frac{5}{15}\times 0.971 + \frac{5}{15}\times 0.971 + \frac{5}{15}\times 0.722 = \frac{1}{3}(0.971 + 0.971 + 0.722) = \frac{2.664}{3} = 0.888 $$
信息增益
- 公式: $$\text{Gain}(\text{年龄}) = H(D) - H(D|\text{年龄})$$
- 计算: $$\text{Gain}(\text{年龄}) = 0.971 - 0.888 = 0.083$$
特征熵(分裂信息)
- 公式: $$H_A(\text{年龄}) = -\sum_{i=1}^{3} \frac{|D_i|}{|D|} \log_2 \frac{|D_i|}{|D|}$$
- 计算: $$H_A(\text{年龄}) = -3 \times \frac{5}{15}\log_2\frac{5}{15} = -3 \times \frac{1}{3}\log_2\frac{1}{3}= -\log_2\frac{1}{3} = \log_2 3 = 1.585$$
信息增益比
- 公式: $$\text{Gain\_ratio}(\text{年龄}) = \frac{\text{Gain}(\text{年龄})}{H_A(\text{年龄})}$$
- 计算: $$\text{Gain\_ratio}(\text{年龄}) = \frac{0.083}{1.585} = 0.052$$
特征2:有工作
数据分布:
- 否(10个):否=6,是=4
- 是(5个):否=0,是=5
各子集的熵
- 无工作组熵: $$H(D_1) = -\frac{6}{10}\log_2\frac{6}{10} - \frac{4}{10}\log_2\frac{4}{10} = 0.971$$
- 有工作组熵: $$H(D_2) = -\frac{0}{5}\log_2\frac{0}{5} - \frac{5}{5}\log_2\frac{5}{5} = 0$$
条件熵
- 计算: $$ \begin{aligned} H(D\mid\text{有工作}) &= \frac{10}{15} \times 0.971 + \frac{5}{15} \times 0 \\[4pt] &= 0.647 + 0 \\[4pt] &= 0.647 \end{aligned} $$
信息增益
- 计算: $$\text{Gain}(\text{有工作}) = 0.971 - 0.647 = 0.324$$
特征熵(分裂信息)
- 计算: $$H_A(\text{有工作}) = -\frac{10}{15}\log_2\frac{10}{15} - \frac{5}{15}\log_2\frac{5}{15} = 0.918$$
信息增益比
- 计算: $$\text{Gain\_ratio}(\text{有工作}) = \frac{0.324}{0.918} = 0.353$$
特征3:有自己的房子
数据分布:
- 否(9个):否=6,是=3
- 是(6个):否=0,是=6
各子集的熵
- 无房组熵: $$H(D_1) = -\frac{6}{9}\log_2\frac{6}{9} - \frac{3}{9}\log_2\frac{3}{9} = 0.918$$
- 有房组熵: $$H(D_2) = -\frac{0}{6}\log_2\frac{0}{6} - \frac{6}{6}\log_2\frac{6}{6} = 0$$
条件熵
- 计算: $$ \begin{aligned} H(D\mid\text{有房}) &= \frac{9}{15} \times 0.918 + \frac{6}{15} \times 0 \\[4pt] &= 0.551 + 0 \\[4pt] &= 0.551 \end{aligned} $$
信息增益
- 计算: $$\text{Gain}(\text{有房}) = 0.971 - 0.551 = 0.420$$
特征熵(分裂信息)
- 计算: $$H_A(\text{有房}) = -\frac{9}{15}\log_2\frac{9}{15} - \frac{6}{15}\log_2\frac{6}{15} = 0.971$$
信息增益比
- 计算: $$\text{Gain\_ratio}(\text{有房}) = \frac{0.420}{0.971} = 0.433$$
特征4:信贷情况
数据分布:
- 一般(5个):否=4,是=1
- 好(6个):否=2,是=4
- 非常好(4个):否=0,是=4
各子集的熵
- 一般组熵: $$H(D_1) = -\frac{4}{5}\log_2\frac{4}{5} - \frac{1}{5}\log_2\frac{1}{5} = 0.722$$
- 好组熵: $$H(D_2) = -\frac{2}{6}\log_2\frac{2}{6} - \frac{4}{6}\log_2\frac{4}{6} = 0.918$$
- 非常好组熵: $$H(D_3) = -\frac{0}{4}\log_2\frac{0}{4} - \frac{4}{4}\log_2\frac{4}{4} = 0$$
条件熵
- 计算: $$ \begin{aligned} H(D\mid\text{信贷}) &= \frac{5}{15} \times 0.722 + \frac{6}{15} \times 0.918 + \frac{4}{15} \times 0 \\[4pt] &= 0.241 + 0.367 + 0 \\[4pt] &= 0.608 \end{aligned} $$
信息增益
- 计算: $$\text{Gain}(\text{信贷}) = 0.971 - 0.608 = 0.363$$
特征熵(分裂信息)
- 计算: $$H_A(\text{信贷}) = -\frac{5}{15}\log_2\frac{5}{15} - \frac{6}{15}\log_2\frac{6}{15} - \frac{4}{15}\log_2\frac{4}{15} = 1.577$$
信息增益比
- 计算: $$\text{Gain\_ratio}(\text{信贷}) = \frac{0.363}{1.577} = 0.232$$
结论:有自己的房子的信息增益比最大(0.433),应优先选择该特征进行分裂。
第十六题:XGBoost损失函数二阶泰勒展开
题目: 已知XGBoost优化第t棵树时的损失函数为:
$\mathcal{L}^{(t)} = \sum_{i=1}^{n}l(y_i, \hat{y}*i^{(t-1)} + f_t(x_i)) + \gamma T + \frac{1}{2}\lambda\sum*{j=1}^{T}w_j^2$
请推导 $l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i))$ 在 $l(y_i, \hat{y}_i^{(t-1)})$ 处对于 $f_t(x_i)$ 的二阶泰勒展开。其中,一阶和二阶导数可使用:
$g_i = \frac{\partial l(y_i, \hat{y}_i)}{\partial \hat{y}*i}\Big|*{\hat{y}_i^{(t-1)}}, \quad h_i = \frac{\partial^2 l(y_i, \hat{y}_i)}{\partial \hat{y}*i^2}\Big|*{\hat{y}_i^{(t-1)}}$
在此基础上,推导叶子节点 $j$ 对应的 $w_j^*$ 满足:
$w_j^* = -\frac{\sum_{i \in \mathcal{I}*j}g_i}{\sum*{i \in \mathcal{I}_j}h_i + \lambda}$
其中,$\mathcal{I}_j = \{i \mid q(x_i) = j\}$ 表示属于叶子节点 $j$ 的样本集合。
解:
二阶泰勒展开
在 $\hat{y}_i^{(t-1)}$ 处对 $l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i))$ 关于 $f_t(x_i)$ 进行二阶泰勒展开:
$\begin{aligned} l(y_i, \hat{y}_i^{(t-1)} + f_t(x_i)) &\approx l(y_i, \hat{y}_i^{(t-1)}) + \frac{\partial l(y_i, \hat{y}_i)}{\partial \hat{y}*i}\Big|*{\hat{y}_i^{(t-1)}} \cdot f_t(x_i) \\ &\quad + \frac{1}{2}\frac{\partial^2 l(y_i, \hat{y}_i)}{\partial \hat{y}*i^2}\Big|*{\hat{y}_i^{(t-1)}} \cdot f_t(x_i)^2 \\ &= l(y_i, \hat{y}_i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2}h_i f_t(x_i)^2 \end{aligned}$
因此损失函数变为:
$\mathcal{L}^{(t)} \approx \sum_{i=1}^{n}[l(y_i, \hat{y}*i^{(t-1)}) + g_i f_t(x_i) + \frac{1}{2}h_i f_t(x_i)^2] + \gamma T + \frac{1}{2}\lambda\sum*{j=1}^{T}w_j^2$
去掉常数项 $\sum_{i=1}^{n}l(y_i, \hat{y}_i^{(t-1)})$:
$\tilde{\mathcal{L}}^{(t)} = \sum_{i=1}^{n}[g_i f_t(x_i) + \frac{1}{2}h_i f_t(x_i)^2] + \gamma T + \frac{1}{2}\lambda\sum_{j=1}^{T}w_j^2$
推导叶子权重 $w_j^*$
对于树模型,$f_t(x_i) = w_{q(x_i)}$,其中 $q(x_i)$ 表示样本 $i$ 落在的叶子节点。
将样本按叶子节点分组:
$$ \tilde{\mathcal{L}}^{(t)} = \sum_{j=1}^{T}\left[\left(\sum_{i \in \mathcal{I}*j}g_i\right)w_j + \frac{1}{2}\left(\sum*{i \in \mathcal{I}_j}h_i + \lambda\right)w_j^2\right] + \gamma T $$记 $G_j = \sum_{i \in \mathcal{I}*j}g_i$,$H_j = \sum*{i \in \mathcal{I}_j}h_i$,则:
$$ \tilde{\mathcal{L}}^{(t)} = \sum_{j=1}^{T}\left[G_j w_j + \frac{1}{2}(H_j + \lambda)w_j^2\right] + \gamma T $$对 $w_j$ 求导并令其为0:
$\frac{\partial \tilde{\mathcal{L}}^{(t)}}{\partial w_j} = G_j + (H_j + \lambda)w_j = 0$
解得:
$$ w_j^* = -\frac{G_j}{H_j + \lambda} = -\frac{\sum_{i \in \mathcal{I}*j}g_i}{\sum*{i \in \mathcal{I}_j}h_i + \lambda} $$语言模型 & GPUs(40%)
第十七题 KV Cache 计算
题目: 假设我们要在一台服务器上对一个采用多头注意力(MHA)的 Transformer 模型进行推理。模型参数如下:隐藏层维度 $d = 4096$,层数 $L = 32$,注意力头数 $h = 32$,采用 FP16 半精度存储(每个元素占 2 Bytes)。
- 请给出生成第 $N$ 个 token 时,KV Cache 新增存储占用的计算公式。
- 当 Batch Size $B = 1$,序列长度达到 $N = 1024$ 时,请计算该请求在显存中占用的 KV Cache 总量(单位:MB)。
解:
1. KV Cache 新增存储计算公式
生成第 $N$ 个 token 时,每一层需要存储该 token 的 Key 和 Value 向量。
- 每个 token 的 K 和 V 向量维度均为 $d$
- 总层数为 $L$
- 注意力头数 $h=32$
- 每个元素占 2 Bytes(FP16)
因此,生成第 $N$ 个 token 时,KV Cache 新增存储占用为:
$$\text{新增存储} = 2 \times L \times d \times 2 \text{ Bytes} = 4Ld \text{ Bytes}=512KB$$其中第一个 2 表示 K 和 V 两部分。
2. 序列长度 N=1024 时的总 KV Cache
当序列长度为 $N = 1024$,Batch Size $B = 1$ 时:
$$\begin{aligned} \text{总存储} &= B \times N \times 2 \times L \times d \times 2 \text{ Bytes} \\&= 1 \times 1024 \times 2 \times 32 \times 4096 \times 2 \text{ Bytes} \\&= 1024 \times 2 \times 32 \times 4096 \times 2 \text{ Bytes} \\&= 536{,}870{,}912 \text{ Bytes} \\ &= 512 \text{ MB} \end{aligned}$$第十八题 RoPE 旋转位置编码
题目: 对于位置 $m$ 的查询向量 $q_m$ 和位置 $n$ 的键向量 $k_n$:
- 证明旋转位置编码(RoPE)下变换后的向量 $\tilde{q}_m$ 和 $\tilde{k}_n$ 的点积仅和 $q_m$、$k_n$ 及相对位置 $m - n$ 相关;
- 进一步说明 RoPE 会对 q/k/v 向量中的哪几个进行位置信息注入。
提示: RoPE 通过旋转矩阵 $R_{pos}$ 将位置信息注入向量。
解:
1. RoPE 点积仅与相对位置相关的证明
RoPE 通过旋转矩阵将位置信息编码。对于二维情况,旋转矩阵为:
$$R_\theta = \begin{pmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{pmatrix}$$对于位置 $m$ 和 $n$,变换后的向量为:
$$\tilde{q}_m = R_{m\theta} q_m, \quad \tilde{k}_n = R_{n\theta} k_n$$它们的点积为:
$$ \begin{aligned} \tilde{q}_m^\top \tilde{k}_n &= (R_{m\theta} q_m)^\top (R_{n\theta} k_n) \\ &= q_m^\top R_{m\theta}^\top R_{n\theta} k_n \\ &= q_m^\top R_{(n-m)\theta} k_n \end{aligned} $$因此变换后的向量 $\tilde{q}_m$ 和 $\tilde{k}_n$ 的点积仅和 $q_m$、$k_n$ 及相对位置 $m - n$ 相关
2. RoPE 对哪些向量注入位置信息
RoPE 仅对 Query (q) 和 Key (k) 向量注入位置信息,不对 Value (v) 向量进行位置编码。
原因是注意力机制通过 $\text{softmax}(q^\top k)$ 计算注意力权重,位置信息需要影响这个权重计算,而 Value 向量仅用于加权求和,不需要位置编码。
第十九题 Transformer Block 的 Post-norm 和 Pre-norm
题目: 对于 Transformer Block 的 Post-norm 有:
$$ x_{l+1} = x_l + \text{Sublayer}(x_l) $$$$ y_{l+1} = \text{LN}(x_{l+1}) $$- 请相应给出 Pre-norm 的计算公式;
- 结合梯度分析证明 Post-norm 相比 Pre-norm 更易出现梯度消失或放大,并指出其中的梯度恒等映射通路。
解:
1. Pre-norm 计算公式
Pre-norm 将 LayerNorm 应用在 Sublayer 之前:
$$ x_{l+1} = x_l + \text{Sublayer}(\text{LN}(x_l)) $$2. 梯度分析
Post-norm 的梯度:
对于 Post-norm:$x_{l+1} = \text{LN}(x_l + \text{Sublayer}(x_l))$
反向传播时:
$$\frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_{l+1}} \cdot \frac{\partial \text{LN}}{\partial (x_l + \text{Sublayer}(x_l))} \cdot \left(I + \frac{\partial \text{Sublayer}}{\partial x_l}\right)$$多层传播:从第 $L$ 层到第 0 层:
$$\frac{\partial \mathcal{L}}{\partial x_0} = \frac{\partial \mathcal{L}}{\partial x_L} \prod_{l=0}^{L-1} \left[\frac{\partial \text{LN}}{\partial (\cdot)} \cdot \left(I + \frac{\partial \text{Sublayer}_l}{\partial x_l}\right)\right]$$由于需要经过 $L$ 个 LayerNorm 的导数连乘:
- 若 $\left|\frac{\partial \text{LN}}{\partial (\cdot)}\right| < 1$,梯度指数级衰减(梯度消失)
- 若 $\left|\frac{\partial \text{LN}}{\partial (\cdot)}\right| > 1$,梯度指数级放大(梯度爆炸)
Pre-norm 的梯度:
对于 Pre-norm:$ x_{l+1} = x_l + \text{Sublayer}(\text{LN}(x_l))$
反向传播时:
$$\frac{\partial \mathcal{L}}{\partial x_l} = \frac{\partial \mathcal{L}}{\partial x_{l+1}} \cdot \left(I + \frac{\partial \text{Sublayer}(\text{LN}(x_l))}{\partial x_l}\right)$$多层传播:从第 $L$ 层到第 0 层:
$$\frac{\partial \mathcal{L}}{\partial x_0} = \frac{\partial \mathcal{L}}{\partial x_L} \prod_{l=0}^{L-1} \left(I + \frac{\partial \text{Sublayer}_l(\text{LN}(x_l))}{\partial x_l}\right)$$展开后包含恒等路径:
$$\frac{\partial \mathcal{L}}{\partial x_0} = \frac{\partial \mathcal{L}}{\partial x_L} + \text{其他梯度项}$$关键:$\frac{\partial \mathcal{L}}{\partial x_L}$ 可以直接传播到 $x_0$,不受层数 $L$ 影响。
梯度恒等映射通路:
$\frac{\partial x_{l+1}}{\partial x_l}$ 包含恒等项 $I$,即:
$$\frac{\partial x_{l+1}}{\partial x_l} = I + \frac{\partial \text{Sublayer}(\text{LN}(x_l))}{\partial x_l}$$这个恒等项提供了一条直接的梯度传播路径:
$$x_0 \xleftarrow{I} x_1 \xleftarrow{I} \cdots \xleftarrow{I} x_L$$即使 Sublayer 的梯度很小,梯度仍能通过恒等映射传播,避免梯度消失。
结论:
- Post-norm:梯度需经过 $L$ 个 LayerNorm 导数连乘,容易出现梯度消失或爆炸,且无恒等映射通路
- Pre-norm:存在梯度恒等映射通路(残差连接在 LayerNorm 之外),梯度可直接传播,训练更稳定
第二十题 Gated Attention 的 Output 计算
题目: 已知 MHA 中第 $k$ 层第 $i$ 位置 token 的 output 表征计算如下:
$$o_i^k = \left(\sum_{j=0}^{i} S_{ij}^k \cdot X_j W_V^k\right)W_O^k = \sum_{j=0}^{i} S_{ij}^k \cdot X_j(W_V^k W_O^k)$$请相应给出下图 Gated Attention 中 G1/G2/G3 对应的 output $o_i^k$ 计算方法。
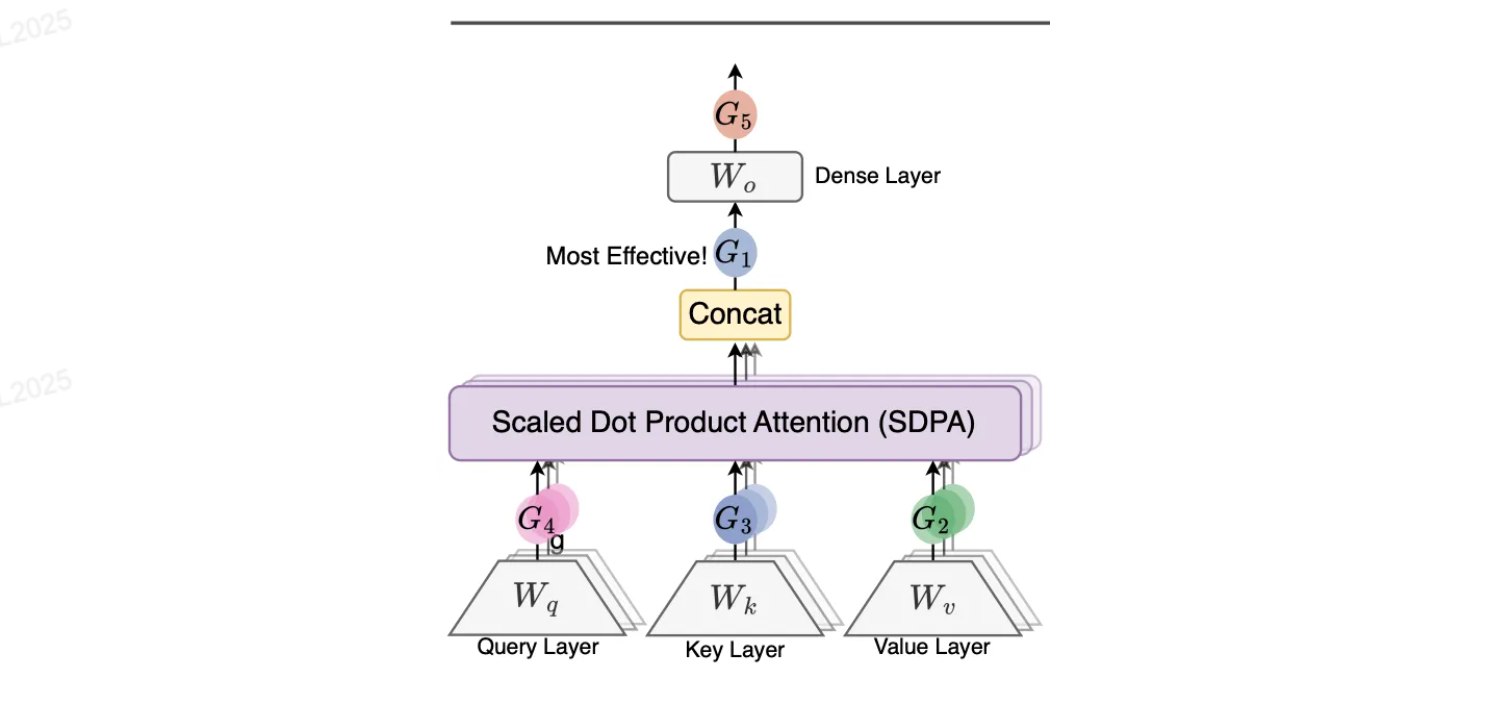
注意:可用 Non-Linearity-Map 算子表示 element-wise gating 机制,即
$$Y' = Y \odot \sigma(XW_\theta) = \text{Non-Linearity-Map}(Y)$$解答:
G1:在聚合后的结果上进行门控(Post-Aggregation Gating)
首先计算标准的注意力聚合结果:
$$ H_i^k = \sum_{j=0}^{i} S_{ij}^k \cdot X_j W_V^k $$对聚合结果应用门控后再进行输出投影:
$$ o_i^k = \text{Non-Linearity-Map}(H_i^k) \cdot W_O^k = \text{Non-Linearity-Map}\left(\sum_{j=0}^{i} S_{ij}^k \cdot X_j W_V^k\right) W_O^k $$G2:在Value上进行门控(Value Gating)
对每个位置的Value表示先应用门控,再进行注意力聚合:
$$ o_i^k = \left(\sum_{j=0}^{i} S_{ij}^k \cdot \text{Non-Linearity-Map}(X_j W_V^k)\right) W_O^k $$G3:在Key上进行门控(Key Gating)
对Key表示应用门控,影响注意力权重的计算:
注意力权重为:
$$ \tilde{S}_{ij}^k = \text{softmax}\left(\frac{Q_i^k \cdot (\text{Non-Linearity-Map} (X_j W_K^k))^T}{\sqrt{d_k}}\right) $$最终输出为:
$$ o_i^k = \left(\sum_{j=0}^{i} \tilde{S}_{ij}^k \cdot X_j W_V^k\right) W_O^k $$第二十一题 GPT-OSS 20B 架构分析
题目: GPT-OSS 20B 架构相比标准 Transformer 有多处改动,请依次文字分析各个改动的具体内容与意义:
- RoPE
- RMSNorm
- GQA
- MoE
- SwiGLU
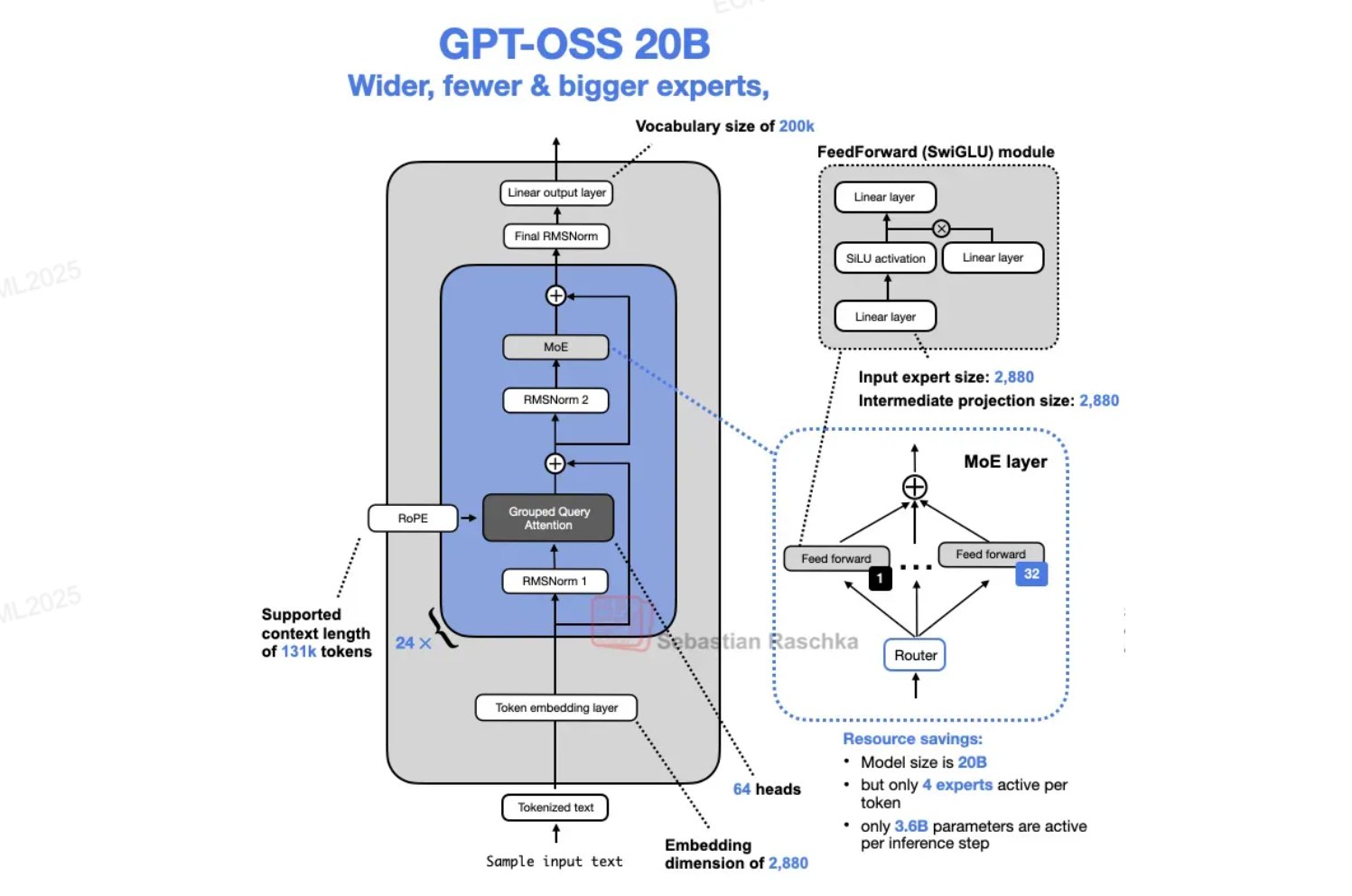
解:
1. RoPE(Rotary Position Embedding,旋转位置编码)
内容: 旋转位置编码,通过旋转矩阵将位置信息注入 Query 和 Key 向量。
意义:
- 相对位置编码:Query 和 Key 的点积仅依赖于相对位置 $m-n$,而非绝对位置
- 外推性好:可以处理训练时未见过的序列长度
- 计算高效:通过旋转操作直接编码位置,无需额外的可学习位置嵌入参数
2. RMSNorm(Root Mean Square Normalization,均方根归一化)
内容: 简化的 LayerNorm,公式为:
$$y = \frac{x}{\sqrt{\frac{1}{d}\sum_{i=1}^{d} x_i^2 + \epsilon}} \cdot \gamma$$不计算均值,只进行缩放归一化。
意义:
- 计算效率高:省去均值计算和中心化操作
- 参数更少:只需 scale 参数 $\gamma$,不需要 shift 参数 $\beta$
- 性能相当:在实践中与 LayerNorm 效果相当或更好
3. GQA(Grouped Query Attention,分组查询注意力)
内容: 将多个 Query head 分组共享同一组 Key 和 Value head。
对比:
- MHA:$n_h$ 个 Query,$n_h$ 对 KV
- GQA:$n_h$ 个 Query,$n_g$ 对 KV($n_g < n_h$)
- MQA:$n_h$ 个 Query,$1$ 对 KV
意义:
- 减少 KV Cache:多个 Query 共享 KV,显著降低显存占用
- 推理加速:减少 KV 读取的内存带宽需求
- 性能折中:介于 MHA 和 MQA 之间,平衡质量与效率
4. MoE(Mixture of Experts,混合专家模型)
内容: 使用路由器(Router/Gate)动态选择激活的专家(Expert FFN),每个 token 只激活 Top-K 个专家。
意义:
- 增加模型容量:总参数量大幅增加(如 Mixtral 8x7B 有 47B 参数)
- 稀疏激活:每个 token 只激活少量专家(如 Top-2),实际计算量接近小模型
- 计算效率:在参数量增加的同时保持推理速度
- 专业化:不同专家学习处理不同类型或领域的输入
5. SwiGLU(Swish-Gated Linear Unit,Swish门控线性单元)
内容: 激活函数,结合 Swish 激活和门控机制:
$$\text{SwiGLU}(x, W_1, W_2, W_3) = (\text{Swish}(xW_1) \odot xW_2) W_3$$其中 $\text{Swish}(x) = x \cdot \sigma(x)$
意义:
- 性能提升:比标准 ReLU/GELU 在多数任务上效果更好
- 门控机制:允许模型动态控制信息流
- 平滑激活:Swish 的平滑性有助于梯度优化
第二十二题 Roofline Model 分析
题目: 结合下列代码和结果,设 repeat=32 时,f 函数在 GPU 上执行时用于数据移动和计算的时间分别为 $T_{\text{move}}$ 和 $T_{\text{comp}}$,并假设此时恰处于 Memory 和计算的平衡点,依次分析:
- repeat=16 时,用于数据移动和计算的时间各是多少,此时 GPU 处于 Memory-bounded or Compute-bounded?
- repeat=64 时,用于数据移动和计算的时间各是多少,此时 GPU 处于 Memory-bounded or Compute-bounded?
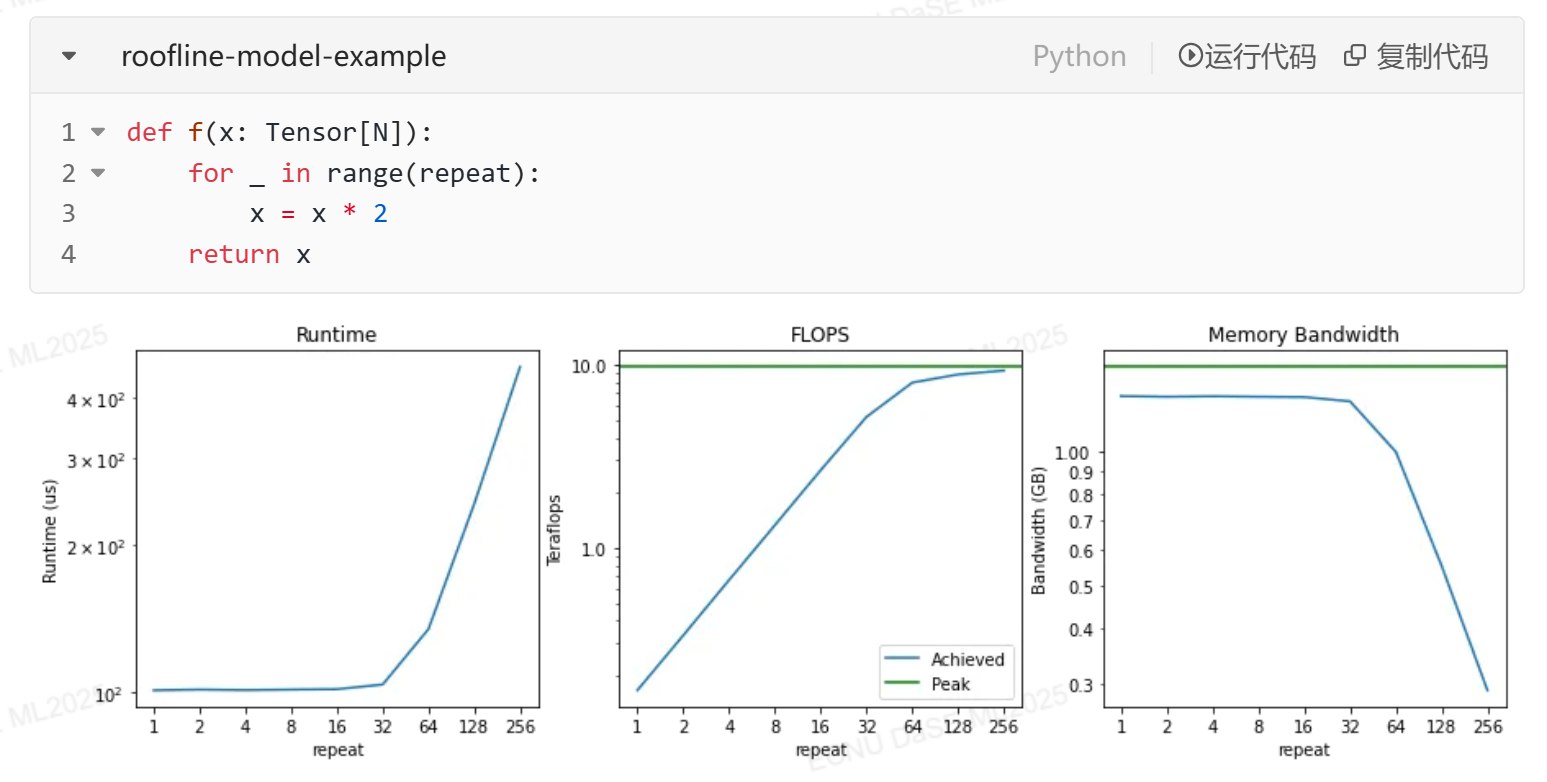
解:
分析
从图中可以看出:
- Runtime 在 repeat=32 之前增长缓慢,之后快速增长
- FLOPS 逐渐增加并趋于平稳
- Memory Bandwidth 在 repeat=32 之前保持高位,之后急剧下降
这表明在 repeat=32 时达到平衡点,此时:
$$T_{\text{move}} = T_{\text{comp}}$$1. repeat=16 时
计算量减半: $T_{\text{comp}}^{(16)} = \frac{1}{2} T_{\text{comp}}$
数据移动量不变(输入输出大小固定): $T_{\text{move}}^{(16)} = T_{\text{move}}$
总时间: $T_{\text{total}}^{(16)} = T_{\text{move}}^{(16)} + T_{\text{comp}}^{(16)} = T_{\text{move}} + \frac{1}{2}T_{\text{comp}} = \frac{3}{2}T_{\text{move}}$
由于 $T_{\text{move}}^{(16)} > T_{\text{comp}}^{(16)}$,GPU 处于 Memory-bounded。
2. repeat=64 时
计算量翻倍: $T_{\text{comp}}^{(64)} = 2T_{\text{comp}}$
数据移动量不变: $T_{\text{move}}^{(64)} = T_{\text{move}}$
总时间: $T_{\text{total}}^{(64)} = T_{\text{move}}^{(64)} + T_{\text{comp}}^{(64)} = T_{\text{move}} + 2T_{\text{comp}} = 3T_{\text{move}}$
由于 $T_{\text{comp}}^{(64)} > T_{\text{move}}^{(64)}$,GPU 处于 Compute-bounded。
第二十三题 Operation Intensity 计算
题目: GPU 的 Operation Intensity 定义为浮点操作数 FLOPS 与数据移动(Bytes)的比值,请计算并对比 LayerNorm 和 RMSNorm 的 Operation Intensity。
注意:d=8192,dtype=bf16,所有数据初始存于全局 DRAM,结果需写回全局 DRAM,且 SRAM 足够存放所有中间计算结果。
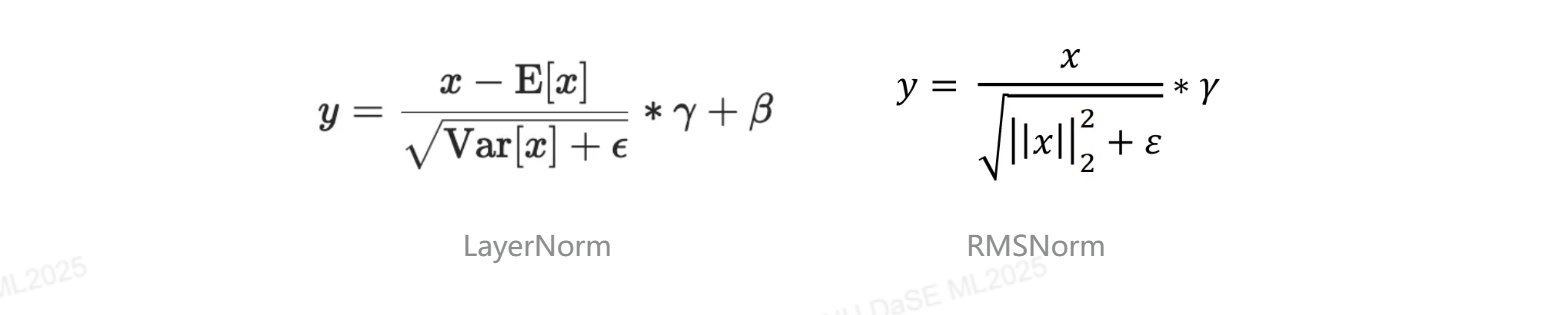
解:
LayerNorm
计算过程:
- 计算均值:$\mu = \frac{1}{d}\sum_{i=1}^d x_i$ → $d$ 次加法,1 次除法 ≈ $d$ FLOPs
- 计算方差:$\sigma^2 = \frac{1}{d}\sum_{i=1}^d (x_i - \mu)^2$ → $d$ 次减法,$d$ 次乘法,$d$ 次加法,1 次除法 ≈ $3d$ FLOPs
- 归一化和缩放:$y_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} \cdot \gamma_i + \beta_i$ →$d$ 次除法,$d$ 次乘法,$d$ 次加法 ≈ $3d$ FLOPs
总计算量: $7d$ FLOPs
数据移动:
- 读取 $x$:$d \times 2$ bytes
- 读取 $\gamma, \beta$:$2d \times 2$ bytes
- 写入 $y$:$d \times 2$ bytes
- 总计:$8d$ bytes
Operation Intensity:
$$\text{OI}_{\text{LN}} = \frac{7d}{8d} = 0.875 \text{ FLOP/Byte}$$RMSNorm
计算过程:
- 计算 RMS:$\text{RMS} = \sqrt{\frac{1}{d}\sum_{i=1}^d x_i^2}$ → $d$ 次乘法,$d$ 次加法,1 次除法,1 次开方 ≈ $2d$ FLOPs
- 归一化和缩放:$y_i = \frac{x_i}{\text{RMS}} \cdot \gamma_i$ → $d$ 次除法,$d$ 次乘法 ≈ $2d$ FLOPs
总计算量: $4d$ FLOPs
数据移动:
- 读取 $x$:$d \times 2$ bytes
- 读取 $\gamma$:$d \times 2$ bytes
- 写入 $y$:$d \times 2$ bytes
- 总计:$6d$ bytes
Operation Intensity:
$$\text{OI}_{\text{RMS}} = \frac{4d}{6d} = \frac{2}{3} \text{ FLOP/Byte}$$对比
LayerNorm 的 OI 为 0.875 FLOP/Byte,RMSNorm 的 OI 为 2/3 FLOP/Byte。两者都很低,属于 Memory-bounded 操作。RMSNorm 虽然计算量更少,但由于数据移动占主导,实际加速效果有限。
第二十四题 A100 Operation Intensity 分析
题目: 以 A100 为例,分析 FP32 和 BF16(TensorCore,考虑 dense 即左边列的 FLOPS)类型在进入 Compute-bounded 时需要的 Operation Intensity 分别是多少。Bandwidth 统一简化为 2TB/s。
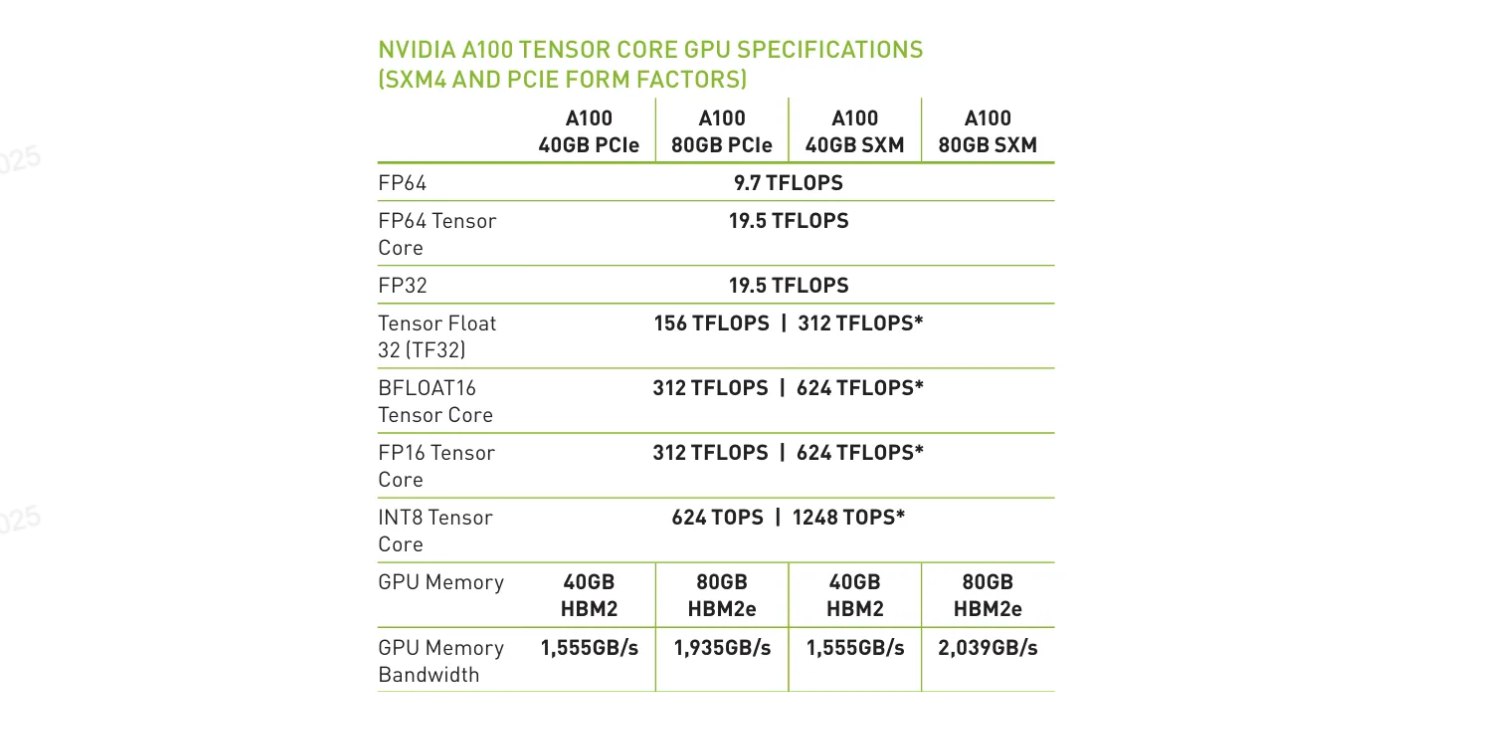
解:
从表格中读取:
- FP32:19.5 TFLOPS
- BF16(TensorCore):312 TFLOPS
- Memory Bandwidth:2TB/s = 2000 GB/s
Compute-bounded 临界点
当计算时间等于数据传输时间时,达到平衡点:
$$\frac{\text{FLOPs}}{\text{Peak FLOPS}} = \frac{\text{Bytes}}{\text{Bandwidth}}$$因此临界 Operation Intensity 为:
$$\text{OI}_{\text{critical}} = \frac{\text{Peak FLOPS}}{\text{Bandwidth}}$$FP32
$$\text{OI}_{\text{FP32}} = \frac{19.5 \text{ TFLOPS}}{2 \text{ TB/s}} = \frac{19.5}{2} = 9.75 \text{ FLOP/Byte}$$BF16 TensorCore
$$\text{OI}_{\text{BF16}} = \frac{312 \text{ TFLOPS}}{2 \text{ TB/s}} = \frac{312}{2} = 156 \text{ FLOP/Byte}$$结论
- 要让 FP32 计算进入 Compute-bounded,Operation Intensity 需要 ≥ 9.75 FLOP/Byte
- 要让 BF16(TensorCore) 计算进入 Compute-bounded,Operation Intensity 需要 ≥ 156 FLOP/Byte
这解释了为什么使用 TensorCore 进行矩阵乘法(OI 通常为 $O(N)$,其中 $N$ 是矩阵维度)更容易达到计算瓶颈,而 LayerNorm/RMSNorm(OI ≈ 1)始终是 Memory-bounded。
强化学习 & Agents(10%+10)
第二十五题 ε-greedy 多臂老虎机问题
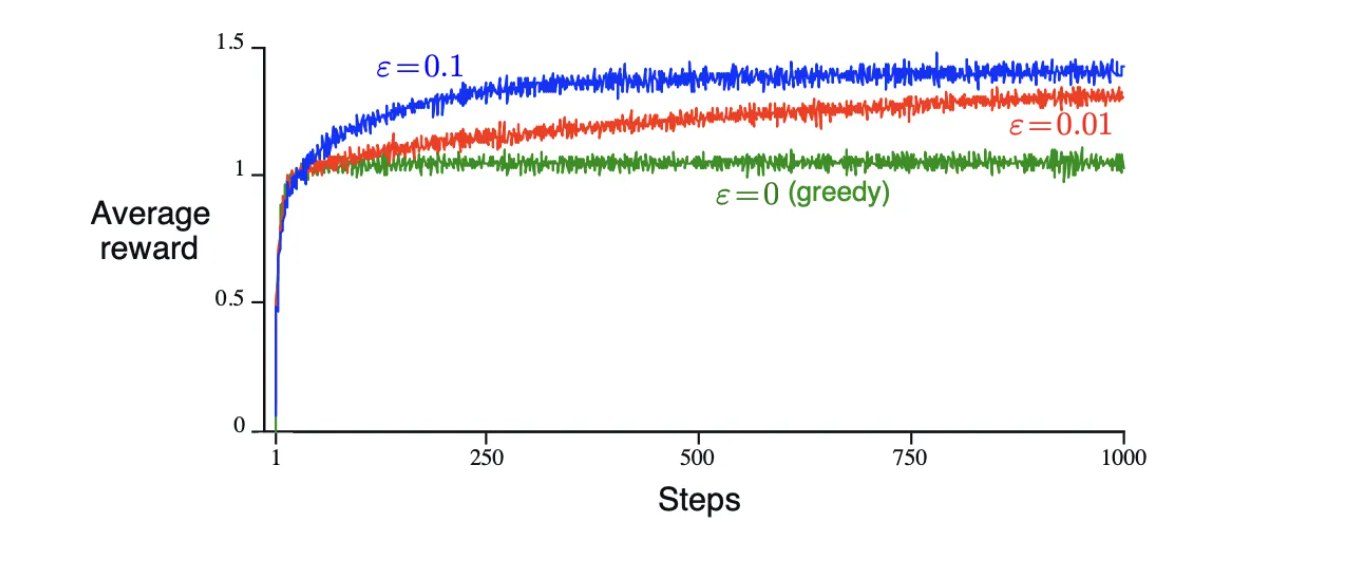
题目: 考虑一多臂老虎机问题(K=10),3 个 ε-greedy 策略下每一时刻可以获得的平均 reward 下图所示。已知该问题中随机以及最有策略下可获得 reward 的期望分别为 1 与 1.55,则:
- 哪个 ε 在游戏后期(steps → +∞)可以获得更高的 average reward。
- 在(steps → +∞)时,这 3 个 ε-greedy 策略每次可获得 reward 的期望各是多少。
解:
1. 后期表现
当 steps → +∞ 时,算法已经充分探索过各个动作,基本掌握了每个臂的期望奖励。此时较小的 ε 值意味着更多地利用(exploitation)已知的最优动作,而较少地进行无效探索(exploration)。ε = 0.1 由于探索概率过高,会频繁选择次优动作,导致平均奖励被拉低。而ε = 0(greedy策略)获得的平均奖励,则是稳定在约 1.0 左右;
因此,ε = 0.01 在后期可以获得更高的 average reward,它在探索和利用之间取得了较好的平衡。
2. 期望分析
ε-greedy 策略的期望 reward 为:
$$\mathbb{E}[R] = (1-\varepsilon) \cdot R_{\text{greedy}} + \varepsilon \cdot R_{\text{random}}$$其中:
- $R_{\text{random}} = 1$(随机策略期望)
- $R_{\text{optimal}} = 1.55$(最优策略期望)
对于 $\varepsilon = 0$(greedy):
由于没有探索,可能陷入局部最优。从图中看收敛到 1.0,说明找到的并非最优臂:
$$\mathbb{E}[R_{\varepsilon=0}] \approx 1.0$$对于 $\varepsilon = 0.01$:
假设经过充分探索后,greedy 部分能找到最优臂:
$$\mathbb{E}[R_{\varepsilon=0.01}] = 0.99 \times 1.55 + 0.01 \times 1 = 1.5345 + 0.01 = 1.5445$$对于 $\varepsilon = 0.1$:
$$\mathbb{E}[R_{\varepsilon=0.1}] = 0.9 \times 1.55 + 0.1 \times 1 = 1.395 + 0.1 = 1.495$$第二十六题 MDP Bellman 方程
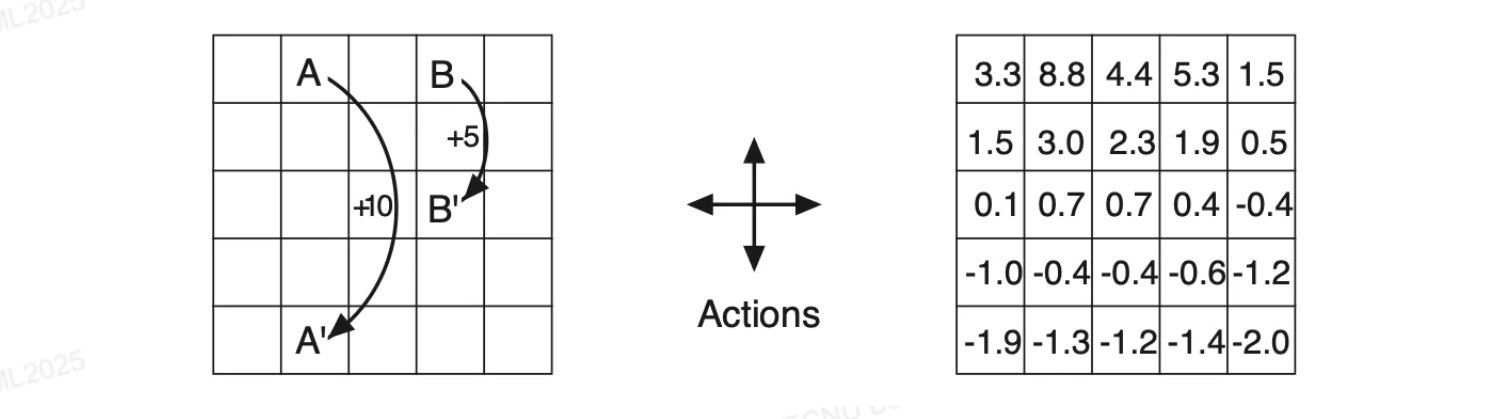
题目: 下图左是一个有限 Markov Decision Process (MDP) 的例子。网格中的单元格对应于环境的状态,在每个单元格中,智能体可以采取四种可能动作:上、下、左、右。这些动作确定性地使智能体在网格上沿相应方向移动一个单元格,并获取 0 的奖励。但有 2 类特殊情况:(1) 如果动作会导致智能体移出网格,则其位置保持不变,但会产生 -1 的奖励;(2) 如果智能体在状态 A 或 B 中,不管采取任意动作都会使智能体传送到 A’或 B’,并获得 +10 或 +5 的奖励。取 discount factor $\gamma = 0.9$。
随机策略对应的 state value 函数如下右图所示,保留 1 位有效数字。记左下状态坐标为 (1, 1),右上状态坐标为 (5, 5),请给出 坐标 (2, 5)、(3, 3)、(4, 5)、(5, 1) 4 个状态对应 value 的 Bellman 迭代公式。
注:上述 4 状态的 value 分别为 8.8、0.7、5.3、-2.0。
解:
Bellman 方程的一般形式为:
$$v(s) = \sum_a \pi(a|s) [r + \gamma v(s')]$$对于随机策略,$\pi(a|s) = 0.25$ 对所有动作 $a \in {\text{上, 下, 左, 右}}$。
坐标系统
根据题意,左下为 (1,1),右上为 (5,5)。状态 A 在 (2,5),A’ 在 (2,1);状态 B 在 (4,5),B’ 在 (4,3)。
(2, 5) - value = 8.8
位置 (2,5) 即时A点,因此从 A 出发会传送到 A’ = (2,1) 并获得 +10。故
$$v(2,5) = 10+0.9v(2,1)$$(3, 3) - value = 0.7
位置 (3,3) 在网格中心。各方向移动:
- 上:到 (3,4)
- 下:到 (3,2)
- 左:到 (2,3)
- 右:到 (4,3)
(4, 5) - value = 5.3
位置 (4,5) 即时B点,因此从 B 出发会传送到 B’ = (4,3) 并获得 +5。故
$$v(4,5) = 5+0.9v(4,3)$$(5, 1) - value = -2.0
位置 (5,1) 在右下角。各方向移动:
- 上:到 (5,2)
- 下:出界 → 保持 (5,1),奖励 -1
- 左:到 (4,1)
- 右:出界 → 保持 (5,1),奖励 -1
第二十七题 MDP 最优策略
题目: 下图左是一个有限 Markov Decision Process (MDP) 的例子(与上题相同)。已知下图右是最优策略对应的 value function,请对应给出各状态的最佳行动策略。
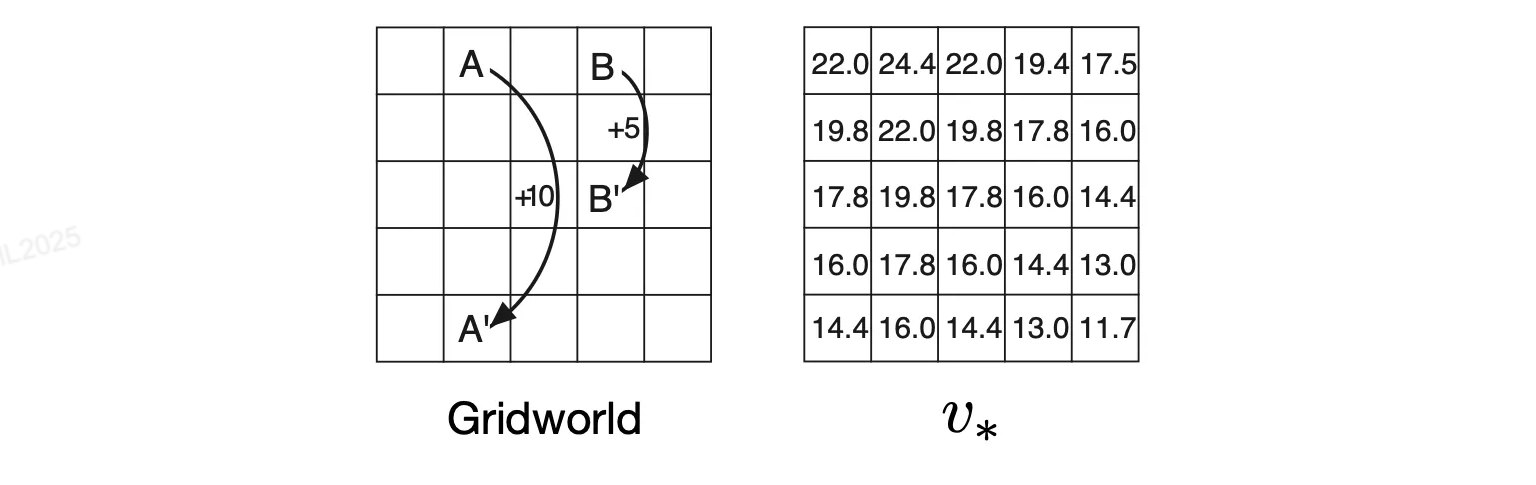
解:
根据给定的Gridworld和最优价值函数 $v_*$,求每个状态的最优行动策略。
对每个状态,选择使期望回报最大的行动:
- 比较相邻状态的价值
- 选择移向更高价值的方向
- 状态A和B有特殊转移(分别+10和+5奖励)
最优策略
$$ \pi_* = \begin{bmatrix} \rightarrow & A & \leftarrow & B & \leftarrow \\ \uparrow/\rightarrow & \uparrow & \uparrow/\leftarrow & \leftarrow & \leftarrow \\ \uparrow/\rightarrow & \uparrow & \uparrow/\leftarrow & \uparrow/\leftarrow & \uparrow/\leftarrow \\ \uparrow/\rightarrow & \uparrow & \uparrow/\leftarrow & \uparrow/\leftarrow & \uparrow/\leftarrow \\ \uparrow/\rightarrow & \uparrow & \uparrow/\leftarrow & \uparrow/\leftarrow & \uparrow/\leftarrow \end{bmatrix} $$说明:
- $\rightarrow, \downarrow, \uparrow, \leftarrow$ 表示最优行动方向
- $A$:触发特殊转移到 $A'$(+10奖励)
- $B$:触发特殊转移到 $B'$(+5奖励)
第二十八题 AI Agent 特性解释 (附加题 10分)
题目: AI Agent 是一类能够感知环境、自主决策并采取行动以实现特定目标的智能系统,并具备自主性、反应性、主动性、社会性以及进化性。请选择其中 3 种性质进行解释,并分别举例一种代表性技术(正式发表于 NeurIPS、ICLR、ICML)介绍其原理。(该题必考)
解:
1. 自主性 (Autonomy)
性质解释 AI Agent 能够在没有外部持续干预的情况下独立运行,自主做出决策并执行任务,无需人工指导每一步操作。
代表性技术:ReAct
- 会议:ICLR 2023
- 论文 ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al.)
核心原理 ReAct 框架通过将推理(Reasoning)和行动(Acting)相结合,使语言模型能够以交替方式生成推理轨迹和任务特定的行动序列:
-
思维-行动-观察循环
- Thought (思考): 模型生成推理步骤,分析当前状态、任务目标和下一步计划
- Action (行动): 执行具体操作(如调用搜索API、使用计算器、访问数据库)
- Observation (观察): 接收环境反馈和执行结果
-
推理增强的行动选择
通过显式的推理轨迹,模型能够:
- 动态分解复杂任务为子目标
- 根据中间结果调整策略
- 处理异常情况和错误
-
提示工程实现 使用 few-shot prompting,提供示例展示 Thought-Action-Observation 模式,引导模型学习这种交互模式。
➡️ 体现的自主性:Agent 无需预定义完整的行动序列,能根据环境反馈自主决策每一步,实现端到端的任务自动化。
2. 反应性 (Reactivity)
性质解释 AI Agent 能够感知环境变化并及时做出响应,从失败中学习,动态调整行为策略以适应变化的情境。
代表性技术:Reflexion
- 会议:NeurIPS 2023
- 论文 Reflexion: Language Agents with Verbal Reinforcement Learning (Shinn et al.)
核心原理 Reflexion 引入了语言化的自我反思机制,使 Agent 能够从试错中快速学习:
- 反思-行动循环
- Actor: 基于当前记忆生成行动轨迹
- Evaluator: 评估行动结果(成功/失败,输出奖励信号)
- Self-Reflection: 当失败时,生成具体的反思文本,分析失败原因
- 语言化的情景记忆
- 将失败经验和反思以自然语言形式存储在短期记忆中
- 在后续尝试中,将相关反思加入提示上下文
- 类似于人类的"从错误中学习"机制
- 迭代改进机制 通过多轮试错-反思循环,Agent 逐步优化策略:
Attempt 1 → Fail → Reflect ("边界条件未处理")
Attempt 2 → 根据反思调整 → Success
➡️ 体现的反应性:Agent 能够快速识别环境反馈(错误信息、失败信号),生成针对性的策略调整,实时适应新情况。
3. 社会性 (Sociality)
性质解释
AI Agent 能够与其他 Agent 进行协作、竞争或沟通,在多智能体环境中通过合作完成单个 Agent 无法完成的复杂任务。
代表性技术:QMIX
- 会议: ICML 2018
- 论文 Monotonic Value Function Factorisation for Deep Multi-Agent Reinforcement Learning (Rashid et al.)
核心原理
QMIX 通过单调价值函数分解解决多智能体协作中的信用分配问题:
1. 集中训练-分散执行 (CTDE) 范式
- 训练阶段:可访问全局状态 $s$ 和所有 Agent 的观测
- 执行阶段:每个 Agent 仅基于局部观测 $o_i$ 独立决策
2. 单调价值函数分解
将全局 Q 函数分解为各 Agent 局部 Q 函数的单调组合:
$$ Q_{\text{tot}}(s, \mathbf{a}) = f_{\text{mix}}(Q_1(o_1, a_1), \ldots, Q_n(o_n, a_n); s) $$约束条件(单调性):
$$ \frac{\partial Q_{\text{tot}}}{\partial Q_i} \geq 0, \quad \forall i $$这保证了:局部贪婪动作($\arg\max Q_i$)的组合等于全局最优动作。
3. 混合网络 (Mixing Network)
- 使用超网络 (hypernetwork) 根据全局状态 $s$ 生成混合网络的权重
- 权重非负性通过绝对值函数保证单调性
- 网络结构:
➡️ 体现的社会性
多个 Agent 无需显式通信即可通过学习形成隐式协作策略,共同最大化团队奖励,展现涌现的群体智能。