第一讲 算法分析
一、算法简介
1. 算法和效率
算法定义:
- 任何良定义的计算过程,该过程取某个值或者值的集合作为输入,并产生某个值或值的集合作为输出
- 把输入转换成输出的计算步骤的一个序列
算法的应用场景:
- 生物基因分析
- 互联网海量数据管理
- 电子商/务
- 高速路由器上的IP包分析(频数统计、Top-k查询、范围查询、中位数、平均数+方差等)
效率分析:
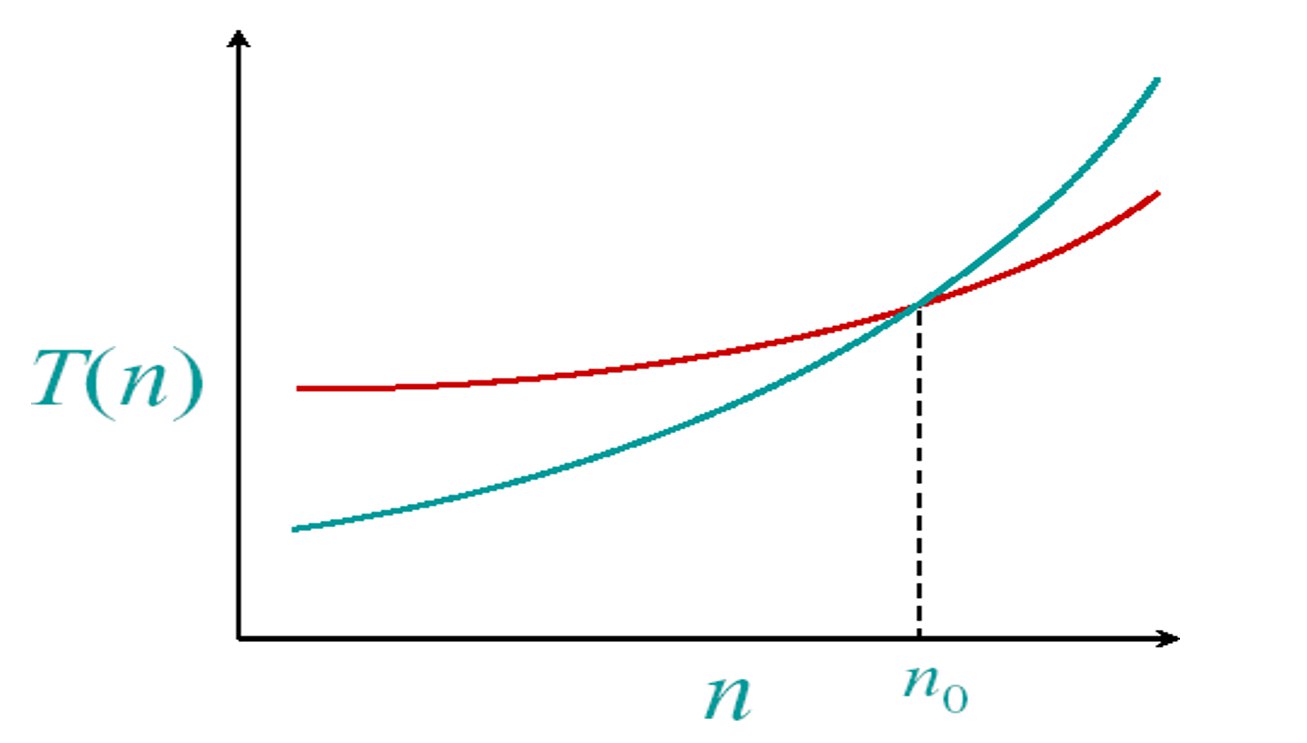
- 求解相同问题的不同算法的效率可能具有显著的差异
- 性能可以用曲线来表达
- 插入排序:$c_1n^2$ vs 归并排序:$c_2n \log n$
- 尽管 $c_1$ 通常小于 $c_2$,但当 $n$ 增长时,最终插入排序的开销更大
案例: 快机器A(100亿条指令/秒)执行插入排序($2n^2$ 条指令)vs 慢机器B(1000万条指令/秒)执行归并排序($50n \log n$ 条指令),当n足够大时,B机器反而更快
渐进性能: 考虑当n足够大时的复杂度,当n足够大时,$\Theta(n^2)$ 算法总是优于 $\Theta(n^3)$ 算法
2. 渐进符号表示
O-记号(“big-Oh”,渐近上界):
- $f(n) = O(g(n))$ if $\exists$ 常数 $c, n_0$,满足 $0 \leq f(n) \leq cg(n), \forall n \geq n_0$
- 案例:$2n^2 = O(n^3)$ ($c=1, n_0=2$)
- 集合形式:$O(g(n)) = \{f(n): \exists \text{ 常数 } c, n_0,\text{满足 } 0 \leq f(n) \leq cg(n), \forall n \geq n_0\}$
Ω-记号(渐进下界):
- $\Omega(g(n)) = \{f(n): \exists \text{ 常数 } c, n_0,\text{使得 } 0 \leq cg(n) \leq f(n), \forall n \geq n_0\}$
Θ-记号(渐进紧确界):
- $\Theta(g(n)) = \{f(n): \exists \text{ 常数 } c_1, c_2, n_0,\text{满足 } 0 \leq c_1g(n) \leq f(n) \leq c_2g(n), \forall n \geq n_0\}$
o-记号(非渐近紧确的上界):
- $o(g(n)) = \{f(n): \text{对任意正常数 } c > 0,\text{存在常数 } n_0,\text{使得对所有 } n \geq n_0,\text{有 } 0 \leq f(n) < cg(n)\}$
ω-记号(非渐近紧确的下界):
- $\omega(g(n)) = \{f(n): \text{对任意正常数 } c > 0,\text{存在常数 } n_0,\text{使得对所有 } n \geq n_0,\text{有 } 0 \leq cg(n) < f(n)\}$
三种分析类型:
- 最坏情况(通常使用): $T(n)$ = 对于任意规模n的输入数据,算法的最大运行时间
- 平均情况(有时使用): $T(n)$ = 对于规模为n的所有输入情况,算法的期望运行时间(假设已知输入数据的统计分布)
- 最佳情况(虚构的): 所有输入系列之中,运行时间最快的情况下的运行时间
思考题1:紧确界Θ和下界Ω、上界O之间的关系如何?
解答:
三者关系可以类比于数学中的等号、大于等于号和小于等于号:
-
紧确界 $\Theta$:$f(n) = \Theta(g(n))$ 意味着 $f(n)$ 的增长率与 $g(n)$ 相同,即 $f(n)$ 被 $g(n)$ 从上下两边同时夹住。当且仅当 $f(n) = O(g(n))$ 且 $f(n) = \Omega(g(n))$ 时,$f(n) = \Theta(g(n))$。
-
上界 $O$:$f(n) = O(g(n))$ 意味着 $f(n)$ 的增长率不快于 $g(n)$,$g(n)$ 是 $f(n)$ 的渐近上界。
-
下界 $\Omega$:$f(n) = \Omega(g(n))$ 意味着 $f(n)$ 的增长率不慢于 $g(n)$,$g(n)$ 是 $f(n)$ 的渐近下界。
关系总结:
$$\Theta(g(n)) = O(g(n)) \cap \Omega(g(n))$$这说明紧确界是上界和下界的交集,表示函数的精确增长率。
3. 算法设计基本方法
分治策略:
- 将原始问题拆分成若干个相似的(规模更小)子问题
- 递归求解子问题
- 组合子问题的解,以产生最终答案
动态规划:
- 通常用于解决最优化问题,通过做出一组选择来达到最优解
- 在做出每个选择的同时,通常会生成与原问题形式相同的子问题
- 关键在于保存每个此类子问题的解,当其重复出现时即可避免重复求解
- 有时可以将指数时间的算法转换为多项式时间的算法
贪心算法:
- 基本思路是使用局部最优解来求得全局最优解
- 但是,贪心算法并不总是针对所有问题获得最优解
- 关键是需要知道如何正确区分适用场景
思考题2:快速排序算法的渐进复杂度应该如何表示?
解答:
快速排序的复杂度表示取决于分析的角度:
-
最坏情况:$O(n^2)$ - 当每次划分都极度不平衡时(如数组已排序或逆序),每次只能减少一个元素,导致递归深度为 $n$。
-
平均情况:$\Theta(n \log n)$ - 在随机输入或随机化快速排序中,平均情况下划分比较均衡,递归树深度为 $O(\log n)$。
-
最佳情况:$\Theta(n \log n)$ - 每次划分都完全平衡时,递归树深度为 $\log n$。
实践中的表示: 快速排序通常被描述为平均时间复杂度 $\Theta(n \log n)$,最坏情况 $O(n^2)$。通过随机化技术(随机选择主元),可以使最坏情况的概率极低,因此实际应用中快速排序表现优异。
思考题3:请各说出两种算法,分别是根据分治策略、动态规划、贪心算法设计得来的。
解答:
分治策略算法:
- 归并排序(Merge Sort):将数组分成两半,递归排序后合并。时间复杂度 $\Theta(n \log n)$。
- 快速排序(Quick Sort):选择主元划分数组,递归排序左右两部分。平均时间复杂度 $\Theta(n \log n)$。
动态规划算法:
- 最长公共子序列(LCS):通过保存子问题的解(二维表格)避免重复计算。时间复杂度 $O(mn)$。
- 背包问题(Knapsack Problem):使用表格记录不同容量和物品数量下的最优解。时间复杂度 $O(nW)$,其中 $n$ 是物品数,$W$ 是背包容量。
贪心算法:
- Huffman编码:根据字符频率构建最优前缀编码树,每次选择频率最小的两个节点合并。
- Dijkstra最短路径算法:每次选择距离源点最近的未访问节点,更新其邻居的距离。时间复杂度 $O((V+E) \log V)$(使用优先队列)。
4. 摊还分析
应用场景:
- 用含n个操作的序列 $(o_1, o_2, \ldots, o_n)$ 维护某数据结构
- 操作代价:单次操作的代价可能会很大(例如 $\Theta(n)$),最坏情况下的代价 = $\max c(o_i)$
- 总代价:$\sum_{i=1}^{n} c_i$,总代价未必就是 $n \times$ (最坏情况下的单次操作代价)
- 摊还代价:在上述场景下如何做更紧的分析?(总代价$/n$)
三种典型技术:
-
聚合分析: 计算所有操作的总和开销,再除以操作个数,就是平均开销
-
核算法: 赋予一个操作的费用,称为它的摊还代价。当一个操作的摊还代价超出其实际代价时,差额部分存入数据结构中的特定对象,存入的差额称为信用。对于后续操作中摊还代价小于实际代价的情况,信用可以用于支付差额。需要确保操作序列的总摊还代价是序列总真实代价的上界。
-
势能法: 将势能与整个数据结构相关联,而不是特定对象相关联。将势能释放即可用于支付未来操作的代价。公式:摊余成本 = 真实开销 + 新势能 - 旧势能
二、相似度搜索
1. 相似性搜索简介
问题定义:
给定一个查询对象(query object),在大规模图像集合中定位相似的图像。
核心思想:
- 将图像从图像空间(image space)转换到特征空间(feature space)
- 每张图像可以表示为 $d$ 维特征向量
- 在特征空间中寻找离查询对象最近的点,即其最近邻居(nearest neighbour, NN)
距离度量:
在 $d$ 维特征空间中,两点 $p = (p_1, p_2, \ldots, p_d)$ 和 $q = (q_1, q_2, \ldots, q_d)$ 之间的距离常用欧氏距离:
$$d(p, q) = \sqrt{\sum_{i=1}^{d} (p_i - q_i)^2}$$最近邻搜索(NN Search):
给定查询点 $q$ 和数据集 $S$,找到 $p \in S$ 使得:
$$p = \arg\min_{x \in S} d(q, x)$$其中,NN-dist 表示查询点到最近邻的距离。
2. 一维空间索引方法
(1) 二叉搜索树(Binary Search Tree, BST)
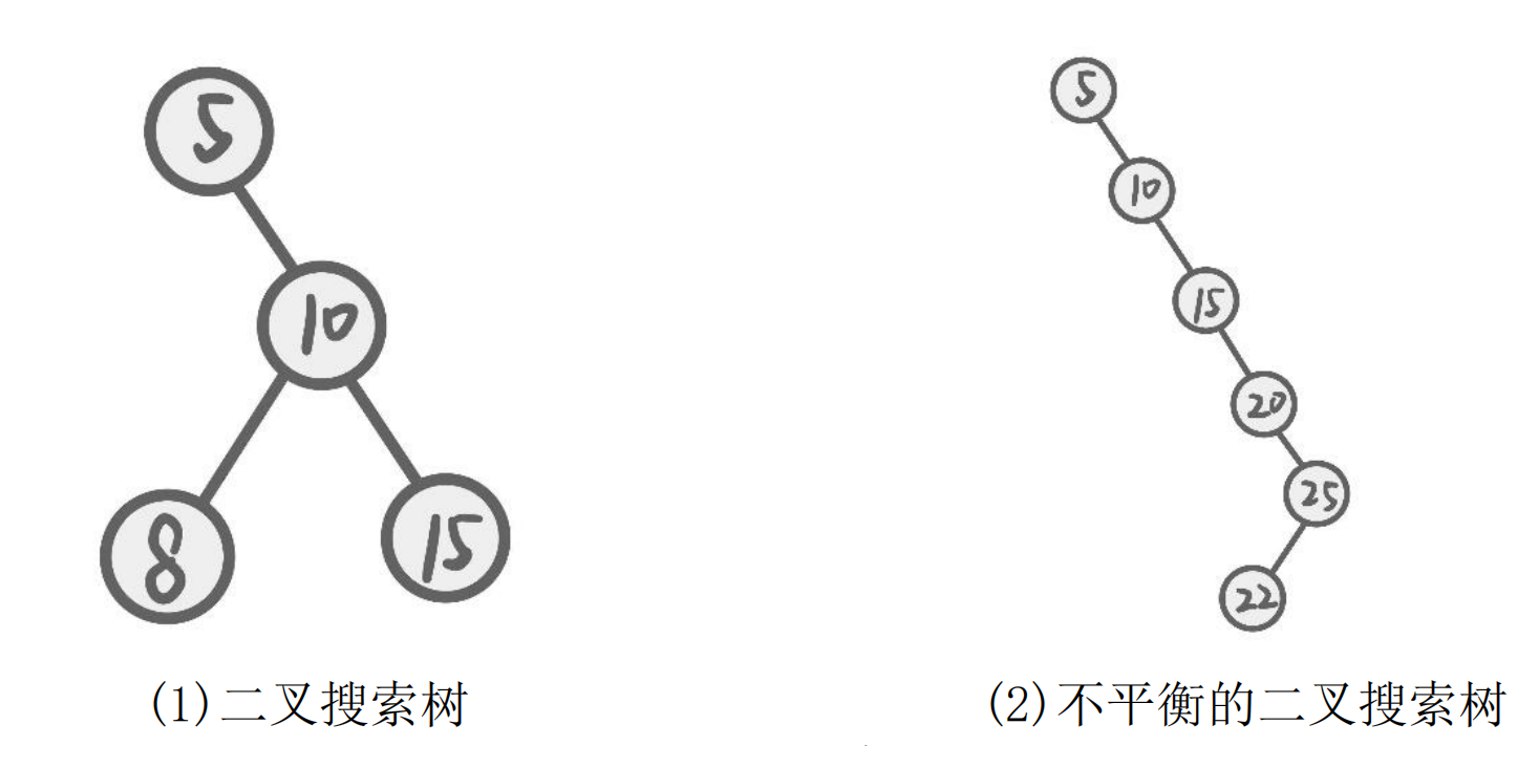
特点:
- 左子树节点值 < 根节点值 < 右子树节点值
- 搜索时间复杂度:平均 $O(\log n)$,最坏 $O(n)$(退化为链表)
不平衡的二叉搜索树:
- 当插入顺序不当时,树会退化成链表结构
- 例如:依次插入 5, 10, 15, 20, 25, 22 会形成右偏树
- 搜索效率降低到 $O(n)$
(2) 红黑树(Red-Black Tree)
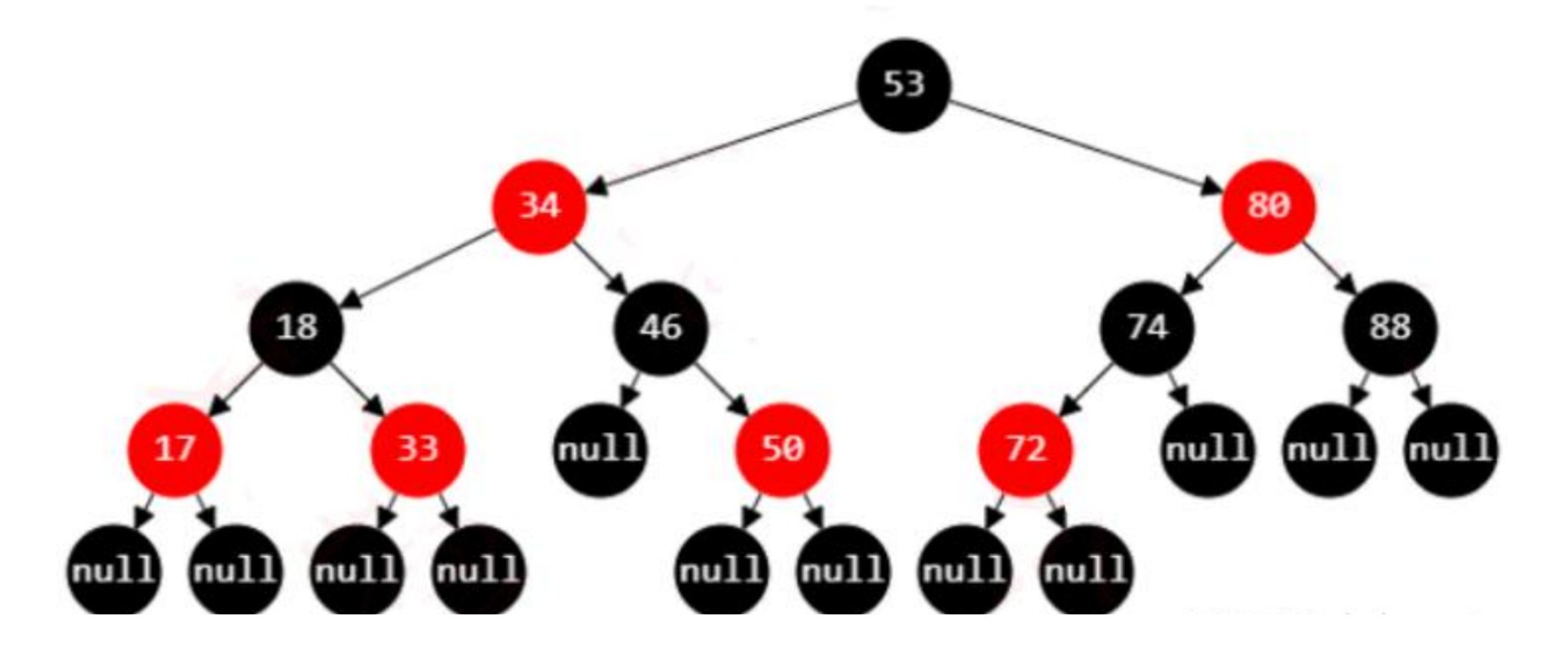
定义: 一种自平衡的二叉搜索树,通过节点染色(红色/黑色)和旋转操作保持平衡。
性质:
- 每个节点是红色或黑色
- 根节点是黑色
- 所有叶子节点(NIL/null)是黑色
- 红色节点的两个子节点都是黑色(不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点
性能:
- 搜索、插入、删除时间复杂度:$O(\log n)$
- 保证最长路径不超过最短路径的2倍
(3) B树(B-Tree)
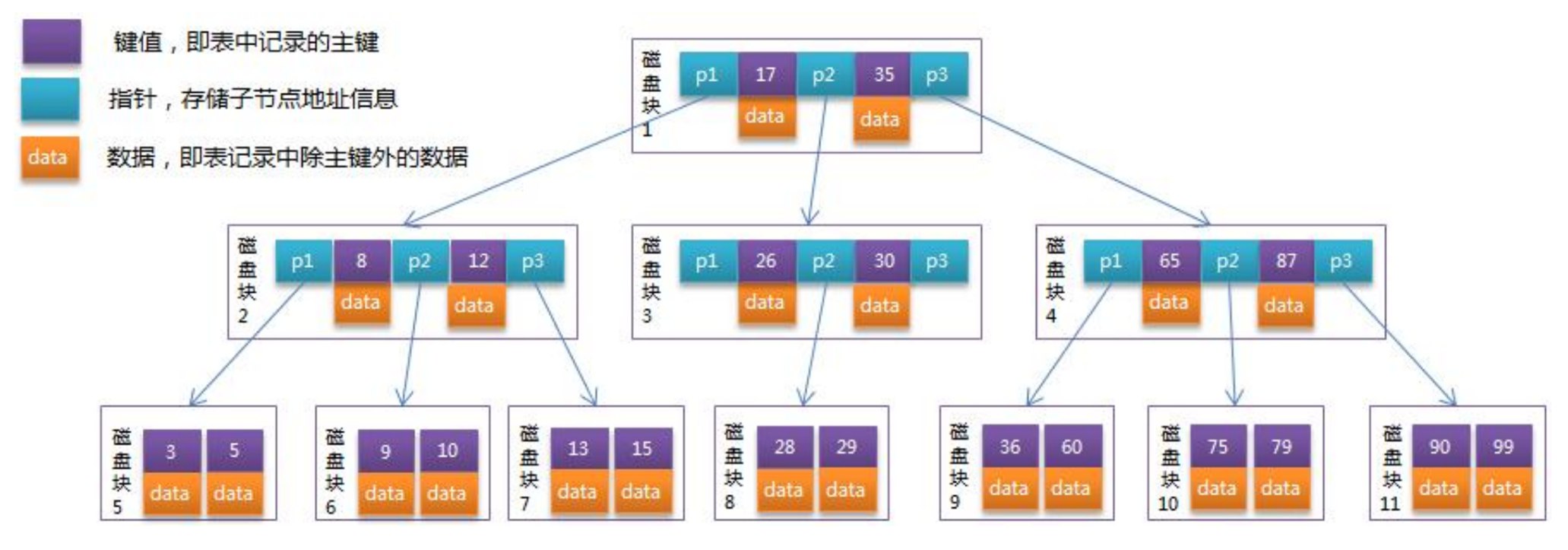
特点:
- 多路平衡搜索树,适合磁盘存储
- 每个节点可以有多个键值和子节点
- 所有叶子节点在同一层
结构组成:
- 键值(key):即索引中记录的主键
- 指针(pointer):存储子节点地址的信息
- 数据(data):即索引记录中除主键外的数据
性能:
- 搜索、插入、删除时间复杂度:$O(\log_m n)$,其中 $m$ 是节点的最大子节点数
- 减少磁盘I/O次数
(4) B+树(B+ Tree)
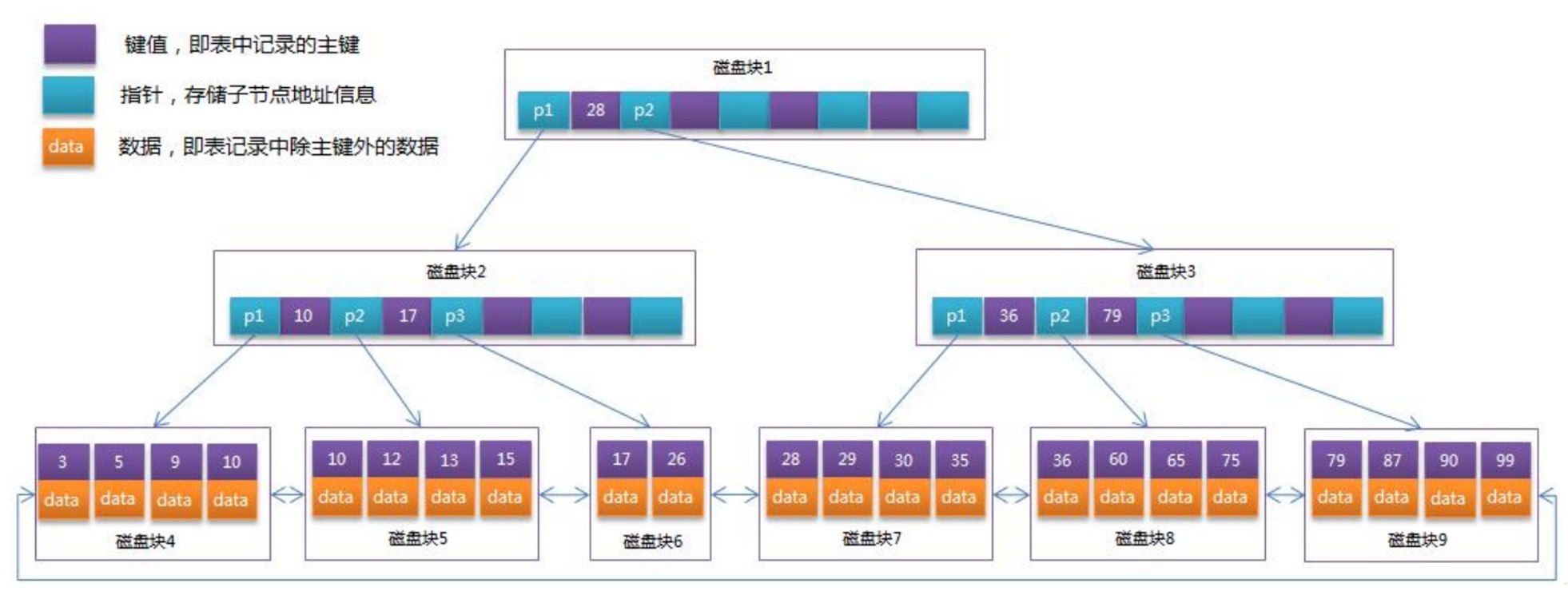
特点:
- B树的变体,数据库索引的常用结构
- 所有数据都存储在叶子节点
- 非叶子节点只存储键值和指针,不存储数据
- 叶子节点之间通过指针连接,形成有序链表
优势:
- 更高的扇出(fan-out),减少树的高度
- 叶子节点的链表结构便于范围查询
- 非叶子节点不存储数据,可以在内存中缓存更多索引项
性能:
- 搜索时间复杂度:$O(\log_m n)$
- 范围查询效率:$O(\log_m n + k)$,其中 $k$ 是返回的记录数
3. 多维空间索引方法
(1) R树(R-Tree)
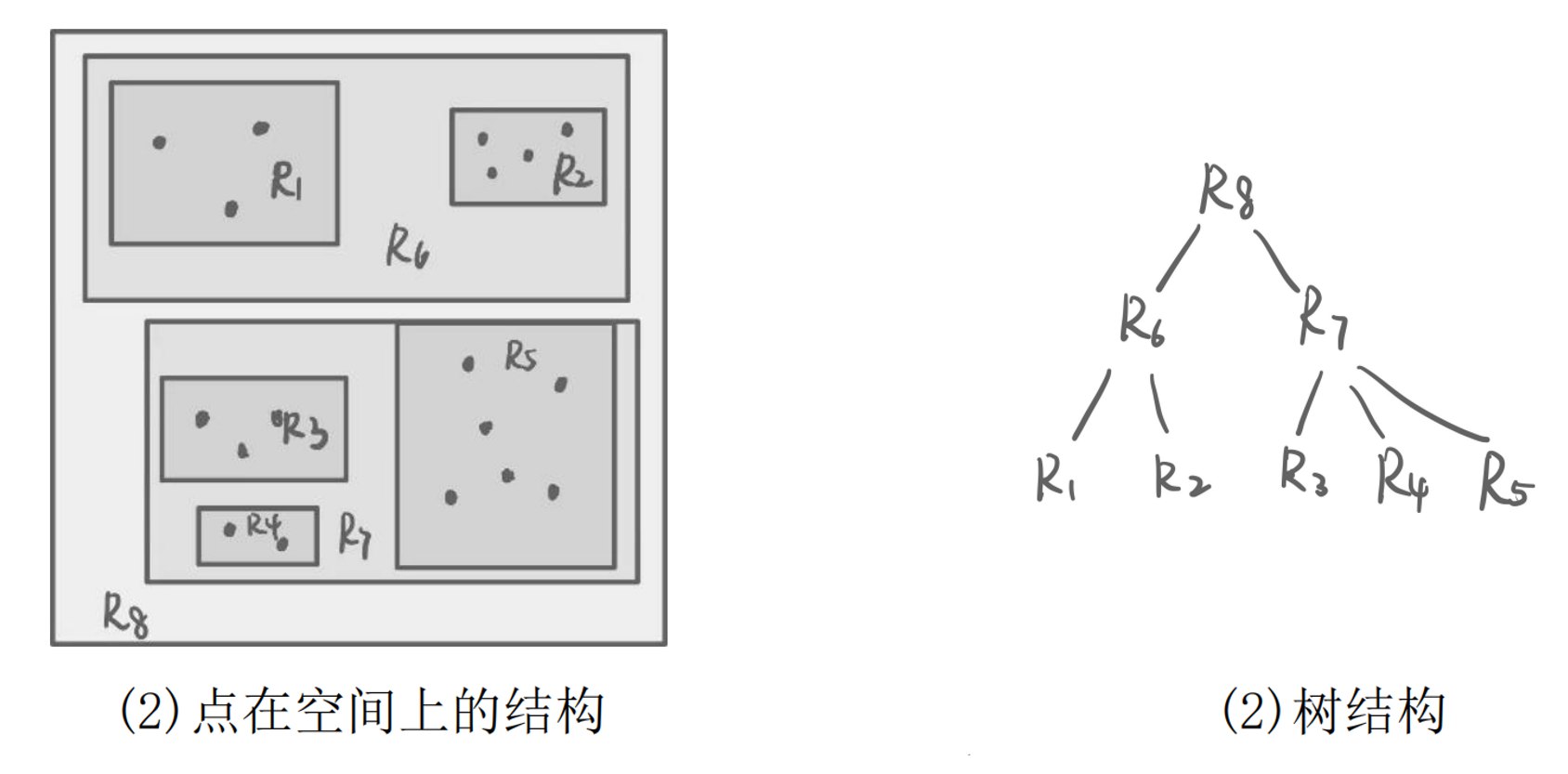
定义: R树是一种用于空间数据索引的树状数据结构,特别适合处理多维空间对象(如矩形、多边形等)。
核心思想:
- 用**最小边界矩形(MBR, Minimum Bounding Rectangle)**近似表示空间对象
- 构建层次化的MBR树结构
- 父节点的MBR包含其所有子节点的MBR
结构特点:
- 叶子节点:存储实际的空间对象及其MBR
- 非叶子节点:存储子节点的MBR
- 同一层的MBR可能重叠
应用场景:
- 地理信息系统(GIS)
- 计算机辅助设计(CAD)
- 空间数据库
(2) 空间填充曲线(Space-Filling Curves)
基本思想: 通过连续曲线遍历多维空间中的所有点,将多维空间映射到一维空间,从而可以使用一维索引方法。
1. Z曲线(Z-order Curve / Morton Curve)
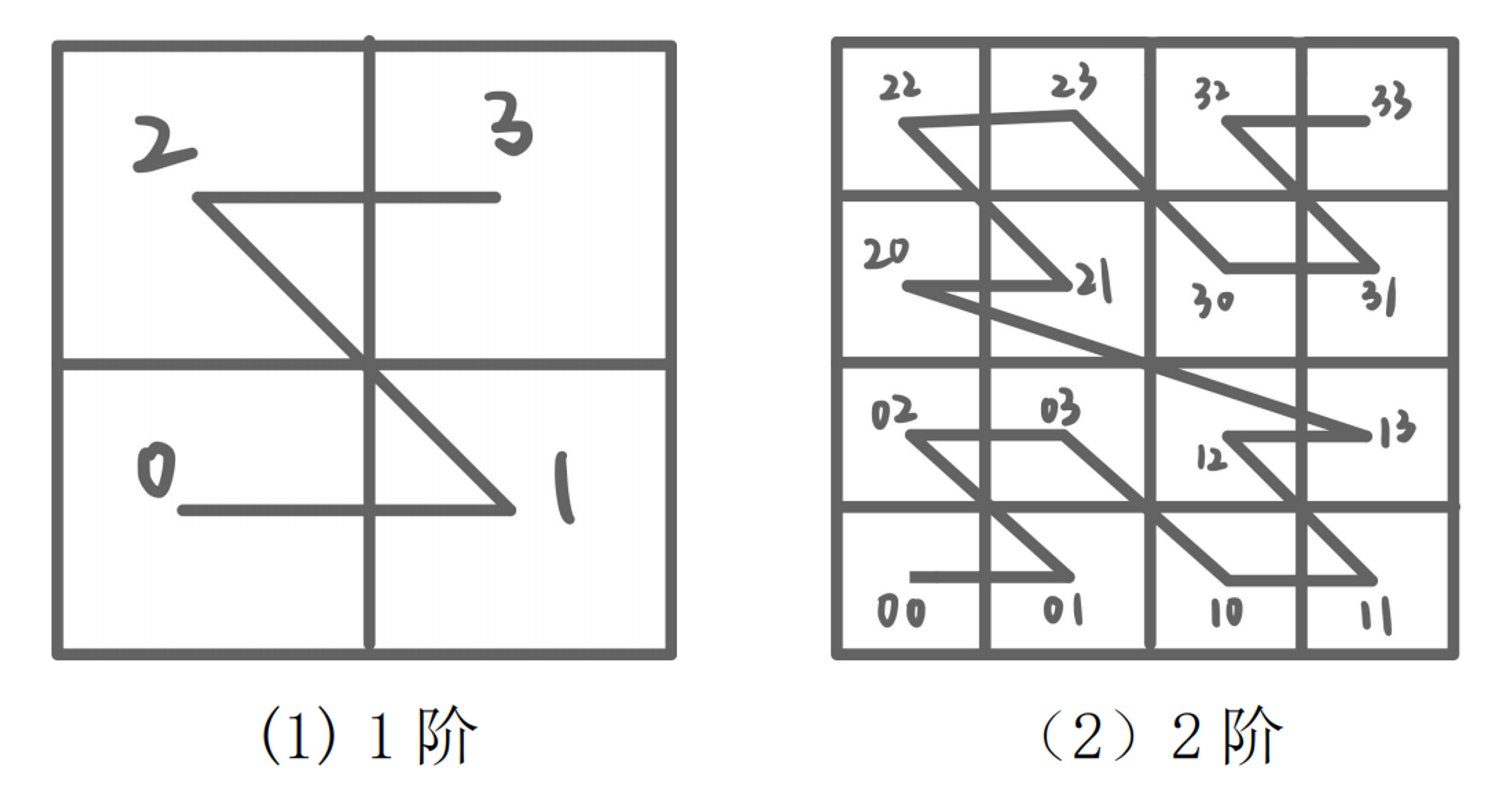
特点:
- 也称为Morton码
- 通过交叉组合坐标的二进制位来编码
- 编码方式:对于二维点 $(x, y)$,交替取 $x$ 和 $y$ 的二进制位
编码示例(2维):
1阶Z曲线($2 \times 2$ 网格)
- 编号顺序: 0 → 1 → 2 → 3
- 形状: Z字形
2阶Z曲线($4 \times 4$ 网格):
- 编号: 00 → 01 → 02 → 03 → … → 30 → 31 → 32 → 33 (二阶其实就是又多了一个符号位,对4个$2 \times 2$的网格进行再次编号$0,1,2,3$)
- 每个$2 \times 2$子区域内部按Z字形连接
优点:
- 编码简单,计算效率高
- 空间局部性较好
缺点:
- 曲线不连续,存在跳跃
- 局部性保持不如Hilbert曲线
2. Hilbert曲线(Hilbert Curve)
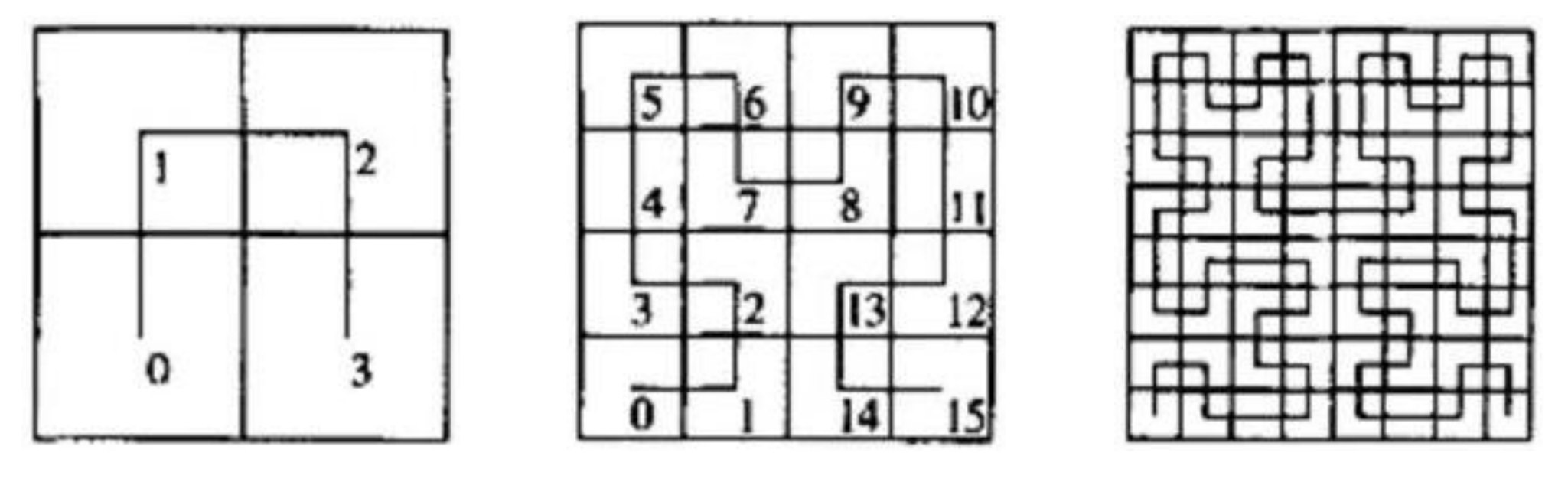
特点:
- 连续的分形曲线
- 更好地保持空间局部性
- 相邻的曲线位置对应相邻的空间位置
递归构造:
- 1阶Hilbert曲线:连接$2 \times 2$网格中的4个点
- $n$阶Hilbert曲线:将空间分为4个象限,每个象限是上一阶的曲线,起点经过**顺时针旋转$90^\circ$**后连接起来
优点:
- 更好的聚类性:空间上接近的点在曲线上也接近
- 曲线连续,无跳跃
缺点:
- 编码计算相对复杂
- 生成算法复杂度较高
性能比较:
| 特性 | Z曲线 | Hilbert曲线 |
|---|---|---|
| 计算复杂度 | 低 | 中 |
| 空间局部性 | 较好 | 优秀 |
| 连续性 | 不连续 | 连续 |
| 聚类效果 | 一般 | 优秀 |
4. 四叉树索引(Quadtree Index)
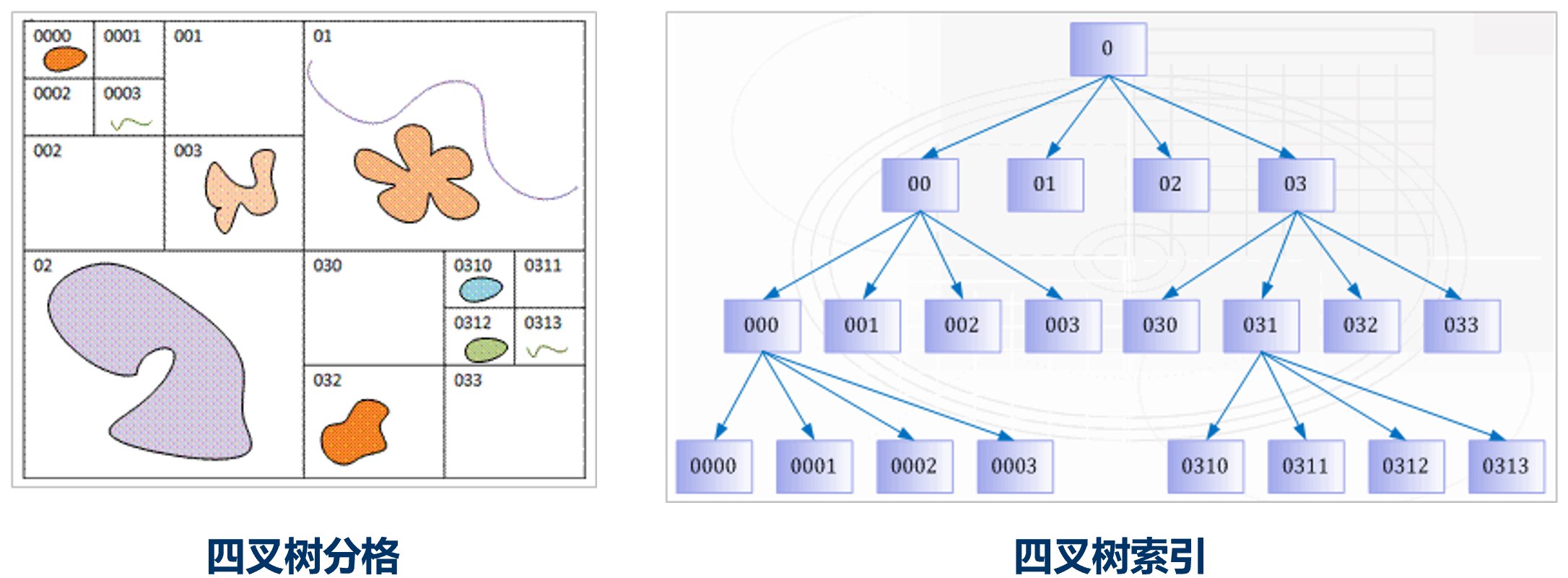
(1) 定义与构造方法
核心思想: 递归地将二维空间分割成四个相等的象限,直到每个区域满足特定条件。
构造方法:
- 将整个数据空间分割成四个相等的矩形,分别对应:
- 西北(NW, Northwest)
- 东北(NE, Northeast)
- 西南(SW, Southwest)
- 东南(SE, Southeast)
- 若每个象限内包含的要素不超过给定的**桶量(bucket size)**则停止
- 否则对超过桶量的矩形按照同样的方法进行划分
- 直到桶量满足要求或者不再减少为止,最终形成一颗有层次的四叉树
(2) 优缺点分析
优点:
- 一定程度上实现了地理要素真正被网格分割
- 保证了桶内要素不超过某个量,提高了检索效率
缺点:
- 对于海量数据,四叉树的深度会很深,影响查询效率
- 可扩展性不如网格索引:
- 当扩大区域时,需要重新划分空间区域,重建四叉树
- 当增加或删除一个对象,可能导致深度加一或减一
- 叶节点也有可能重新定位
5. 网格索引(Grid Index)
(1) 基本思想
将研究区域用横竖线划分成大小相等或不等的网格,每个网格可视为一个桶(bucket)。
索引构建:
- 将空间划分为大小相等或不等的网格
- 记录落入每一个网格区域内的空间实体编号
- 建立网格号到对象列表的映射(倒排索引)
查询过程:
- 先计算出查询对象所在网格
- 再在该网格中快速查询所选空间实体
(2) 倒排索引示例
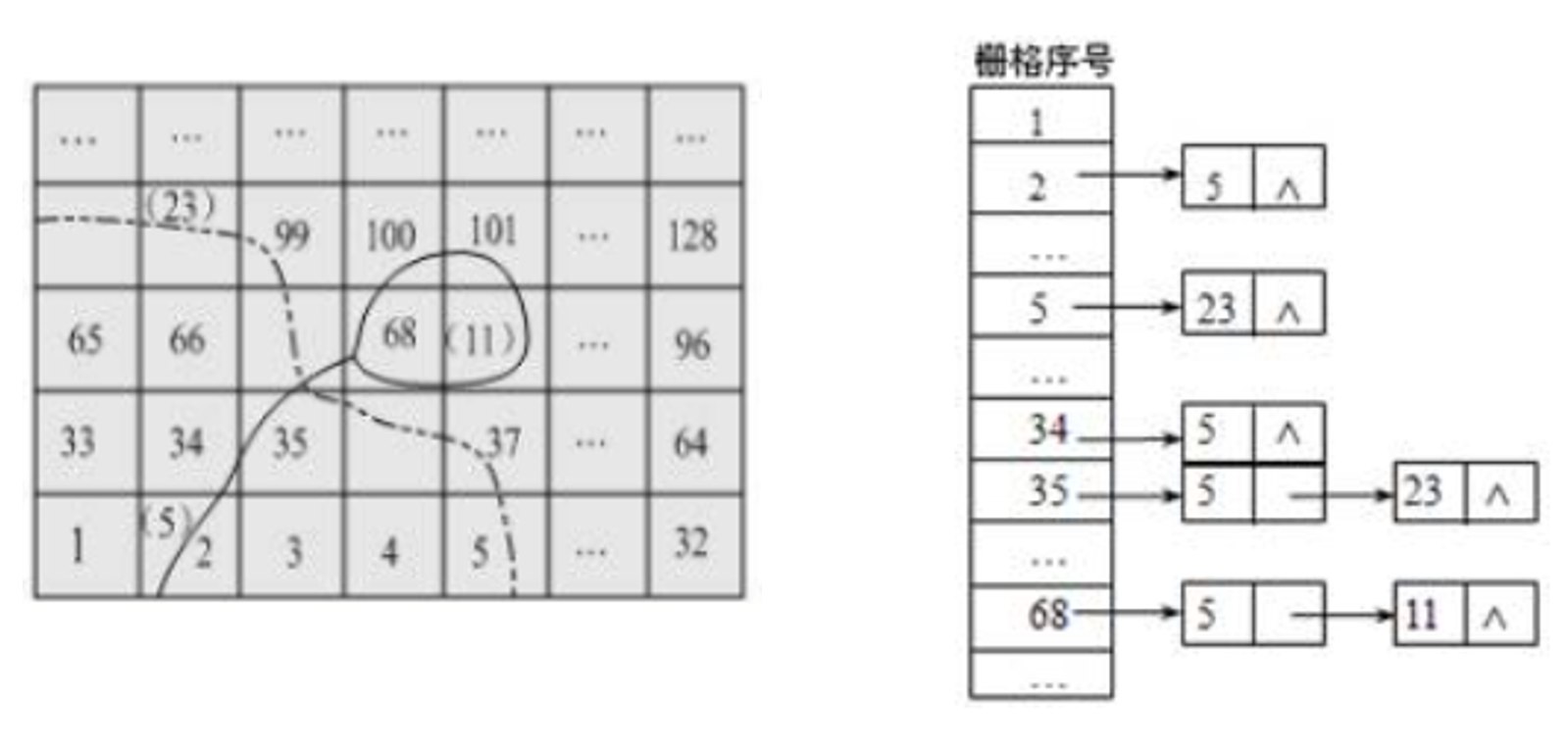
案例: 有三个制图物体:一条河流,一个湖泊,一条省界,关键字分别是 5, 11 和 23。
对象-网格映射
- 河流(ID=5)穿过的栅格:2, 34, 35, 67, 68
- 湖泊(ID=11)覆盖的栅格:68, 69, 100, 101
- 省界(ID=23)通过的栅格:5, 37, 36, 35, 67, 99, 98, 97
查询示例
- 查询网格68:返回 [5, 11](河流和湖泊)
- 查询网格35:返回 [5, 23](河流和省界)
(3) 优缺点分析
优点
- 简单:实现容易,概念直观
- 易于实现:数据结构简单,编码量少
缺点:网格大小影响检索性能
三、高维空间的相似性搜索
1. 高维空间的特性
(1) 维度灾难问题
问题引入: 在各维度上划分原始空间,生成若干个子空间,再将各点划至各子空间内。
-
低维空间(2维或3维):容易理解,且较为合理
-
高维空间
(例如100维):
- 将会产生 $2^{100} = 10^{30}$ 个子空间
- 几乎所有子空间都是空的
(2) 超立方体特性
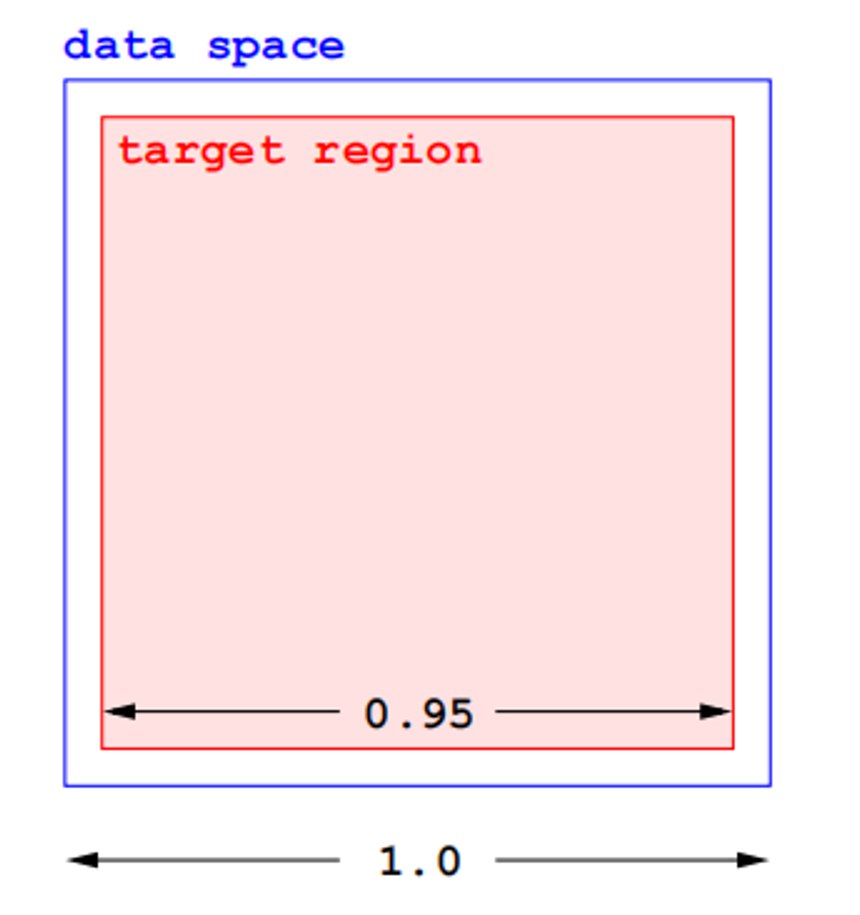
考虑超立方体,其边长为 0.95。
2维情况:
- 任意点在此子空间内的概率:$0.95^2 ≈ 0.90$
100维情况:
- 任意点在此子空间内的概率:$0.95^{100} ≈ 0.0059$
结论: 随着维度增加,点落在中心区域的概率急剧下降。
(3) 超球体特性
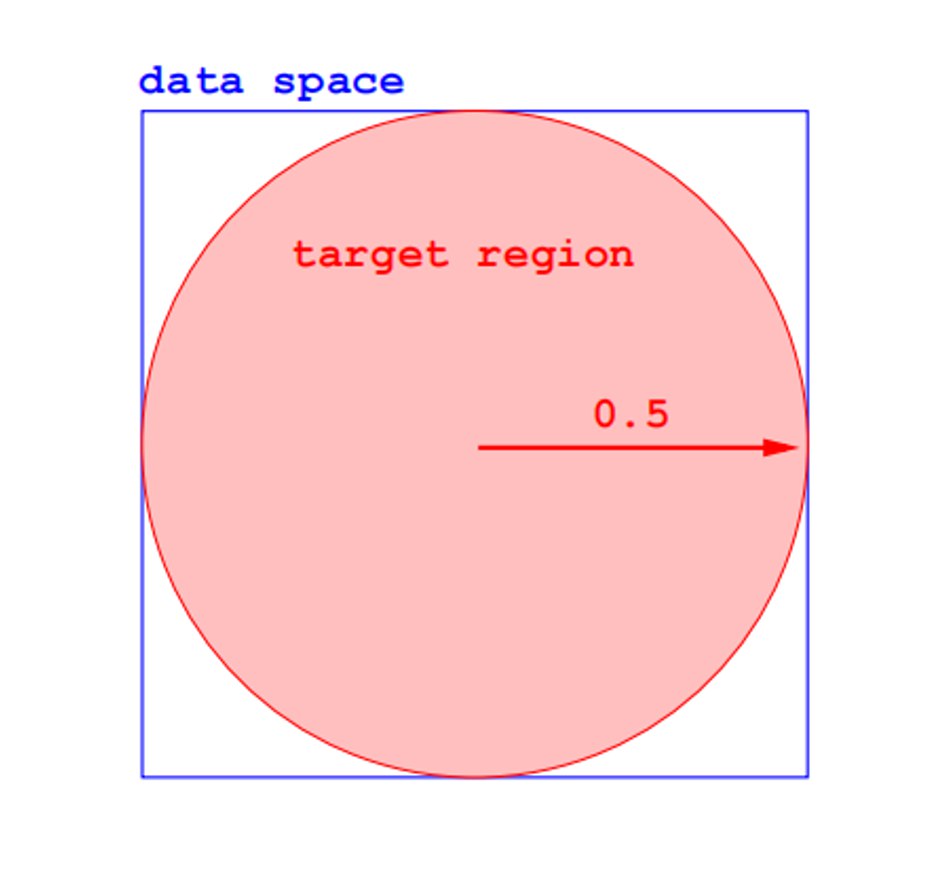
考虑最大的超球(内切于单位立方体)。
2维空间:
- 超球的体积为 $\pi/4 = 0.785$
40维空间:
- 超球的体积为 $3.278 × 10^{-21}$
关键发现:
- 显然,主要空间都在边边角角上
- 至少需要 $3 × 10^{20}$ 个点,才可期望在超球内部至少有一个点
2. 访问概率
(1) 问题定义
核心问题: 给定任一查询,某个特定区域必定会被检索到的概率是多少?
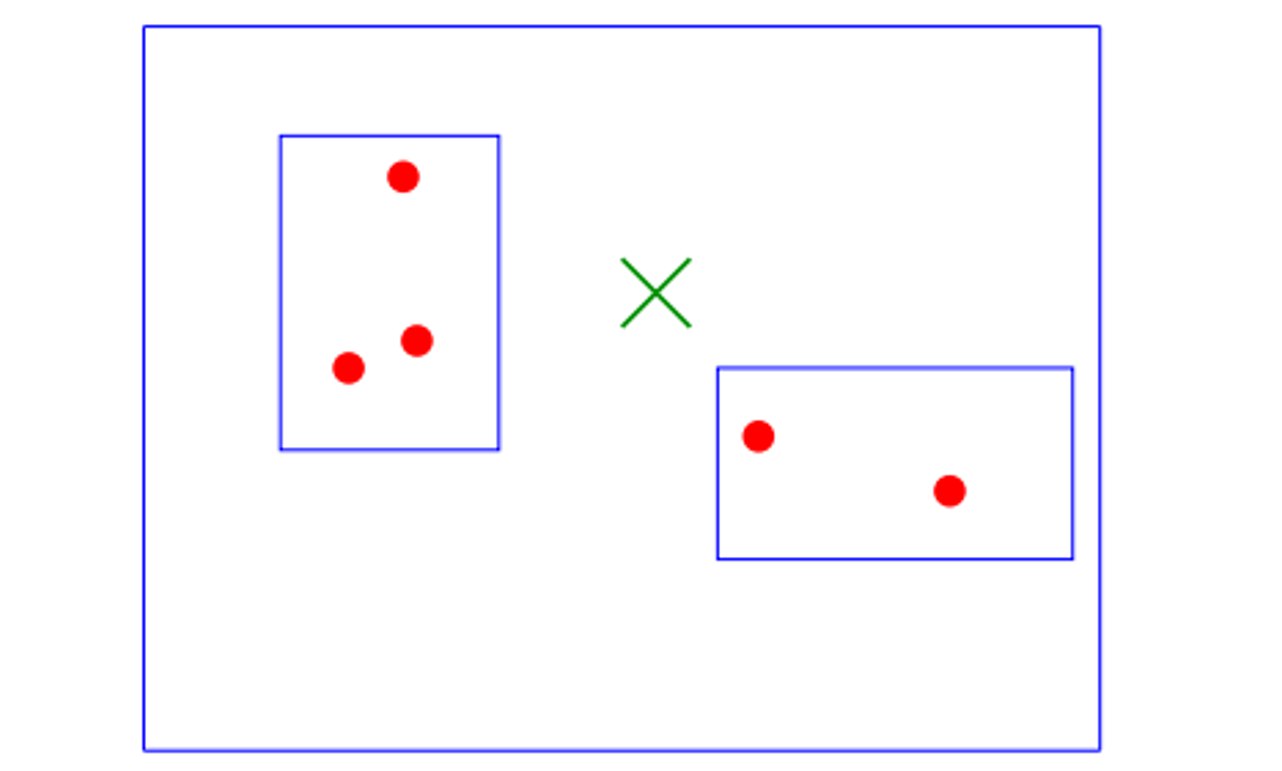
(2) 访问规则
重要性质: 如果右边的区域先被访问,左边的也必须被访问到。这意味着在高维空间中,查询半径内的区域访问具有传递性。
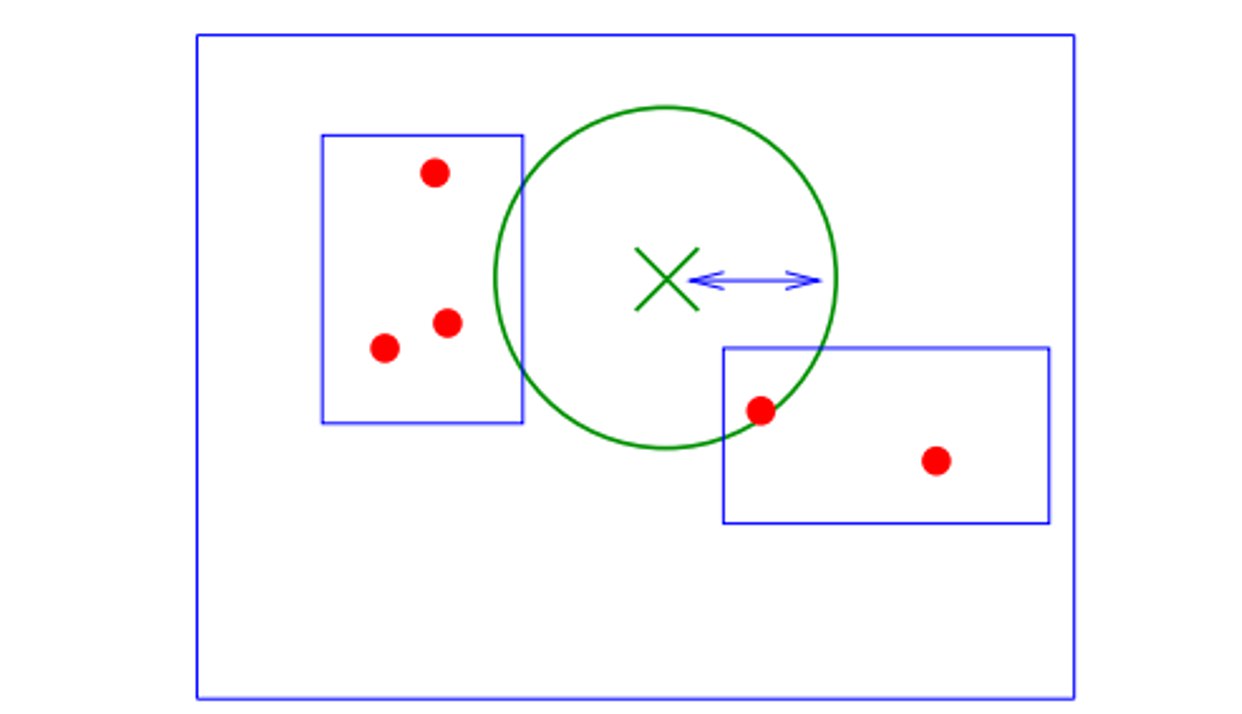
(3) 实验结果
不同区域形状的访问概率:
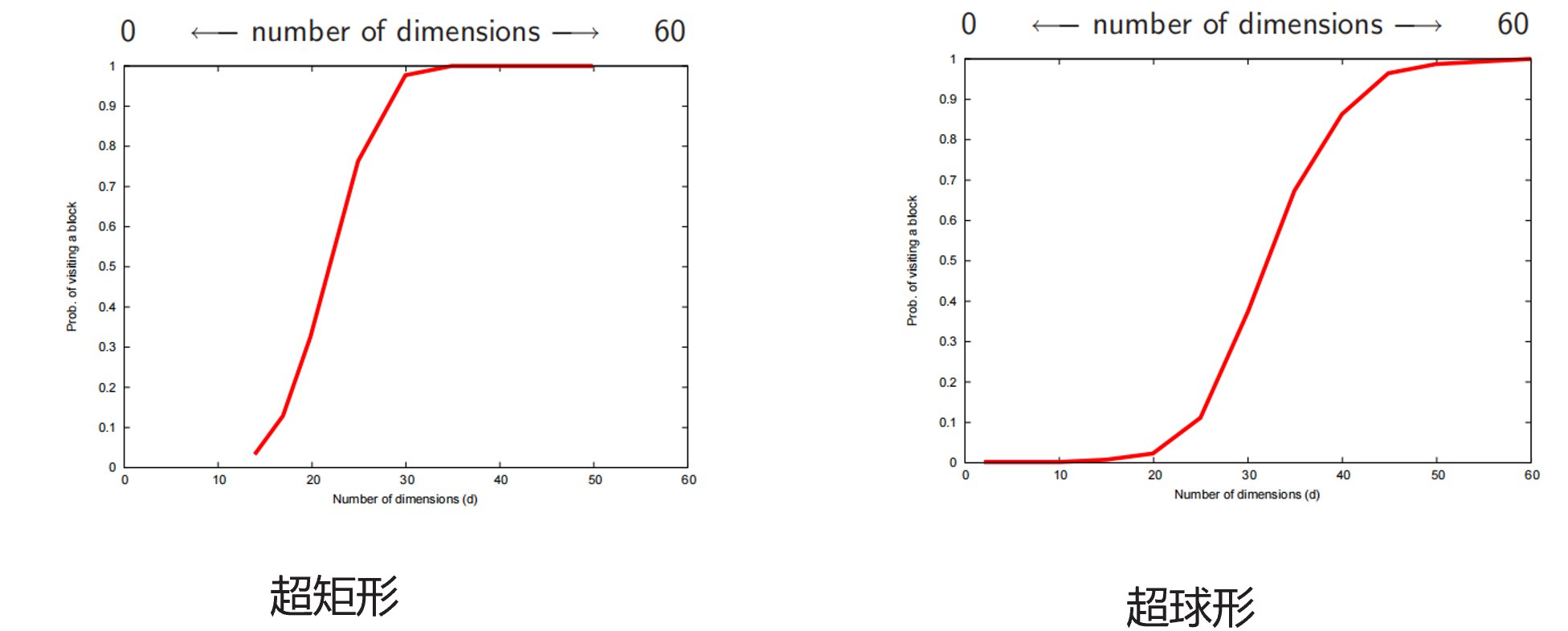
结论: 在维度增加到30-50维时,每个区域被访问到的概率极高。
含义: 在高维空间中,传统的空间划分索引方法失效,因为几乎所有区域都需要被访问。
3. 签名文件(Signature Files)
(1) 设计思路
核心理念:
- 原始数据规模大、处理难度高
- 针对原始数据对象分别构建小规模的签名数据
- 这些数据能够以过滤器的角色支持谓词查询
(2) 工作流程
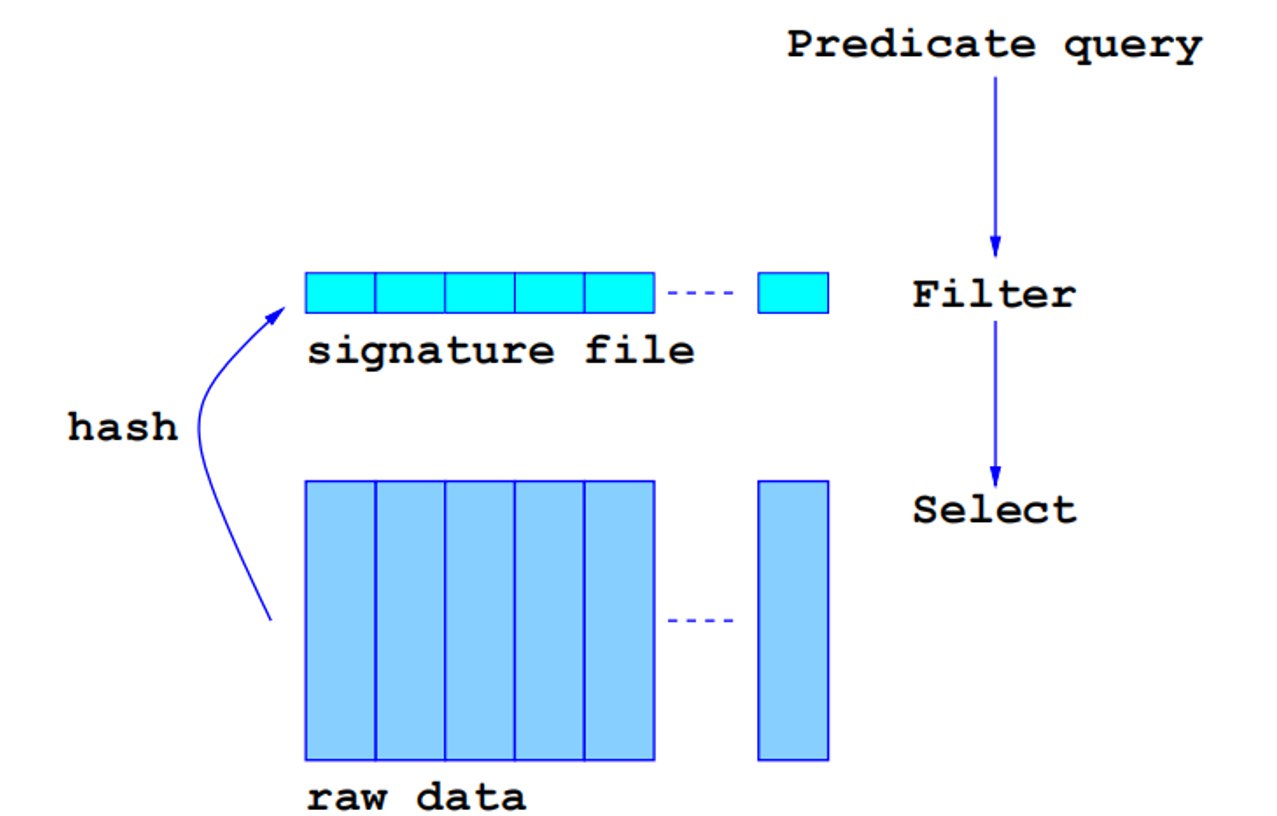
处理步骤:
- 使用哈希函数将原始数据映射为签名
- 签名文件作为第一层过滤器
- 只有通过过滤的数据才访问原始数据
优势:
- 签名文件体积小,可以快速扫描
- 减少对原始数据的访问次数
- 适合作为预处理层
4. 向量近似文件(VA-File)
(1) 算法概述
来源: VLDB 1998
基本思想:
- 通过 **approximation(近似)**方式创建 VA-File 作为 Filter
- 先过滤大部分不可能的候选点
- 只对可能的候选点计算精确距离
(2) 数据结构
空间划分:
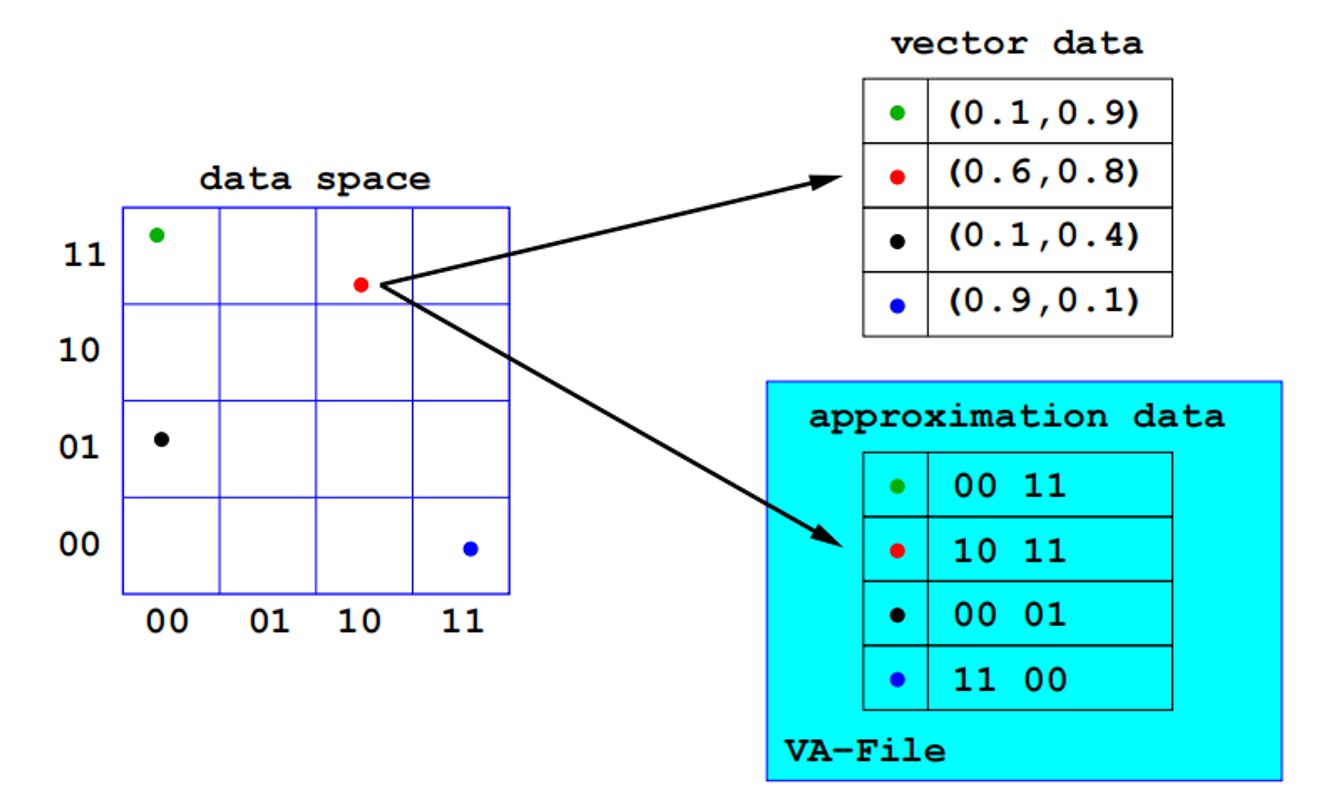
编码方式:
- 将每个维度划分成若干个区间(例如用2比特表示4个区间:00, 01, 10, 11)
- 每个点用所在网格的编码表示
- 例如:点(0.1, 0.9) → 编码 “00 11”
示例:
| 向量数据 | VA-File编码 |
|---|---|
| (0.1, 0.9) | 00 11 |
| (0.6, 0.8) | 10 11 |
| (0.1, 0.4) | 00 01 |
| (0.9, 0.1) | 11 00 |
(3) 最小和最大边界

关键概念:
- minBnd(最小边界):查询点到网格的最小可能距离
- maxBnd(最大边界):查询点到网格的最大可能距离
重要性质: 各栅格的边界之间的距离可以预先计算!
两阶段算法
-
第1阶段:过滤
- 针对每一点计算 minBnd 和 maxBnd 值
- 消除无法成为最近邻居的那些点
- 过滤一些点的minBnd小于已知最近邻的maxBnd值
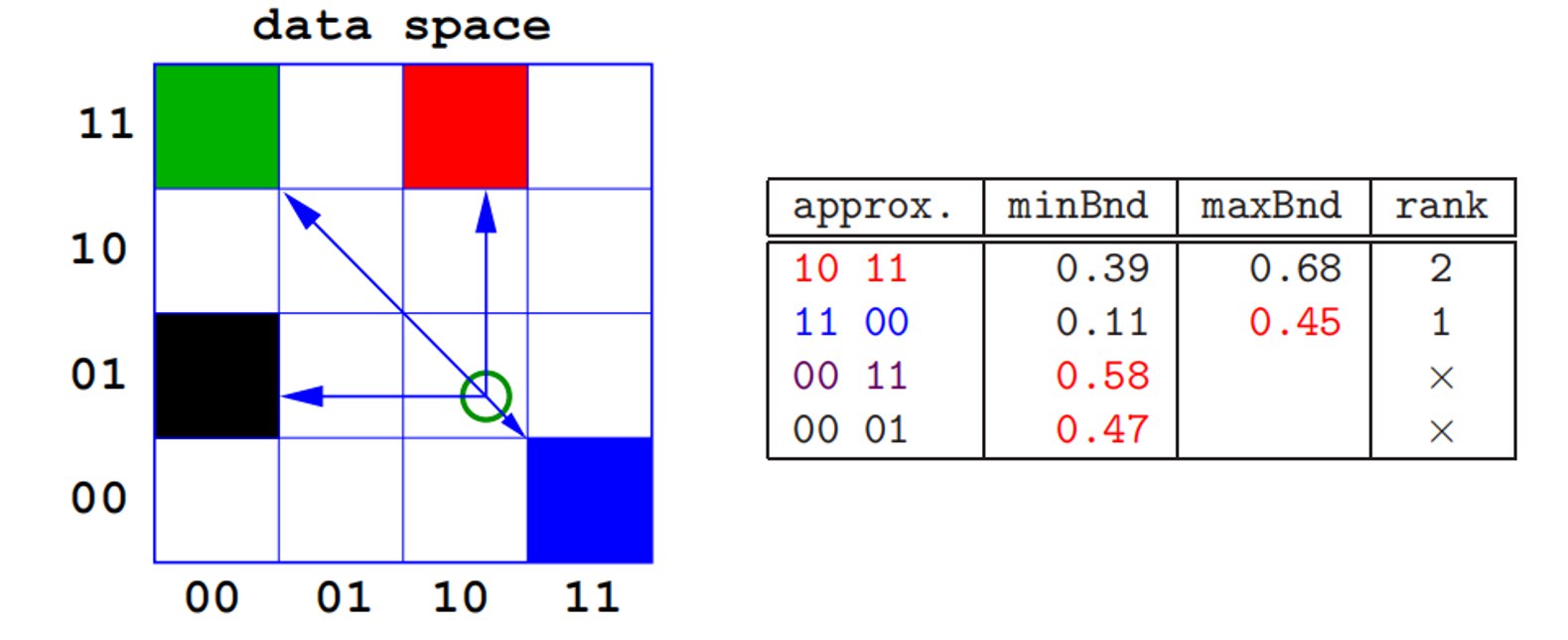
approx. minBnd maxBnd rank 10 11 0.39 0.68 2 11 00 0.11 0.45 1 00 11 0.58 - × 00 01 0.47 - × -
第2阶段:精炼
- 根据 minBnd 以递增顺序访问各向量
- 计算真实的距离
- 当 minBnd 超出已知的最近邻居时,终止
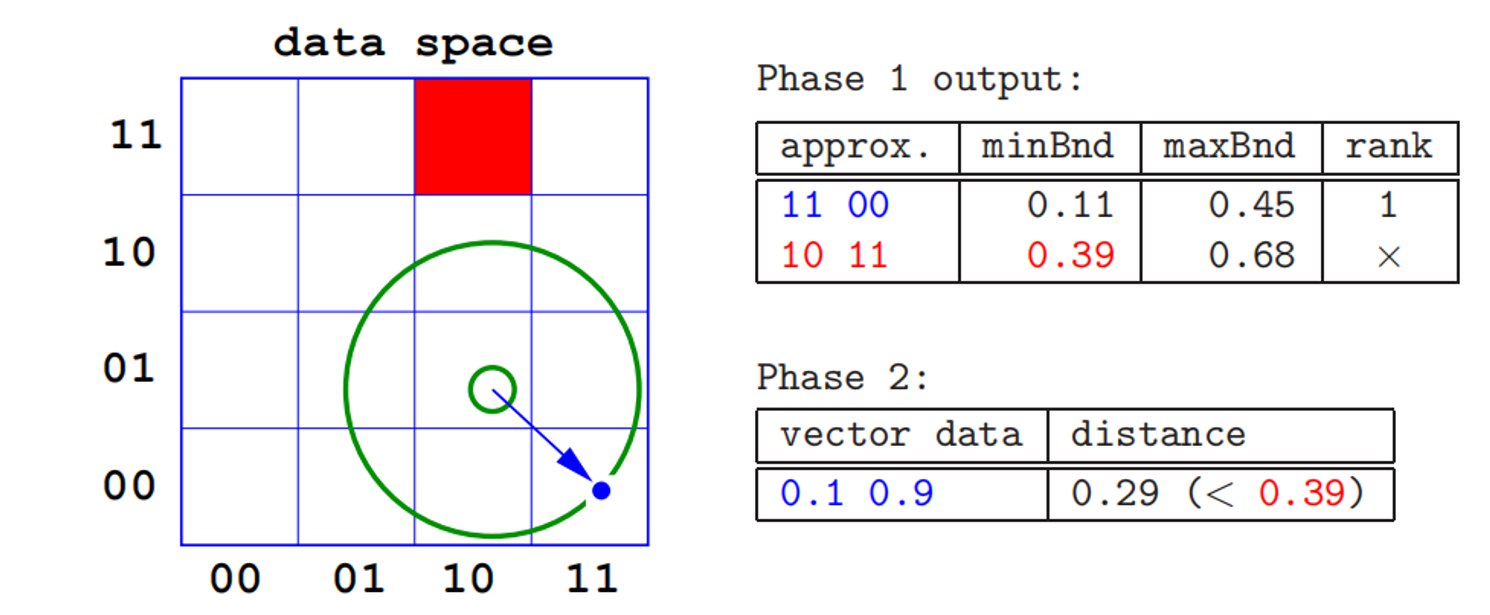
(4) 性能分析
块选择率随维度变化
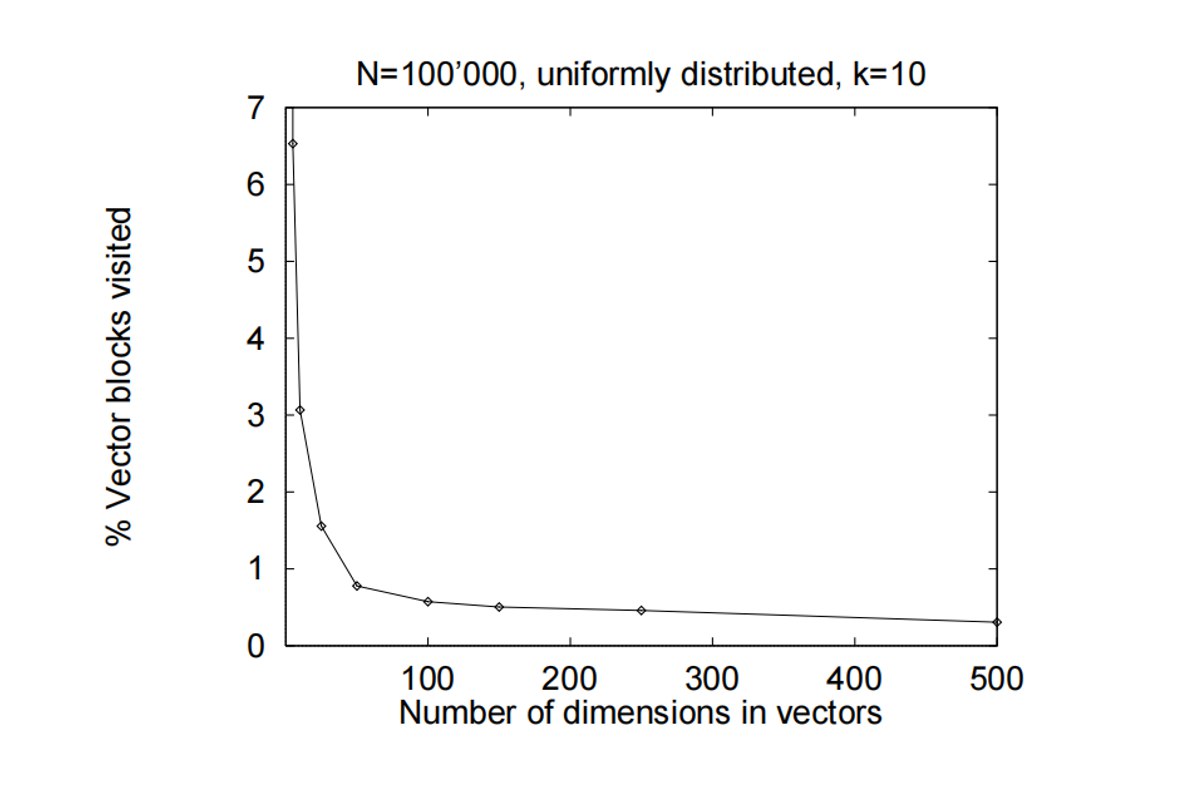
实验条件:N=100,000,均匀分布,k=10
观察
- 低维(<10维):需要访问约3%的向量块
- 中维(10-30维):访问率下降到约0.5%
- 高维(>30维):访问率稳定在约0.3%
与树结构对比、模拟数据(N=50,000,k=10)、图像数据(N=50,000,k=10)、**运行时间对比:**详见PPT
5. 深入理解:Contrast
(1) 定义
Contrast 描述最近邻居与最远邻居之间的差异性高低:
$$\text{contrast} = \frac{D_{\max} - D_{\min}}{D_{\min}}$$(2) 维度影响
- 当维度数量增多时,通常 contrast 值会降低
- 这意味着在高维空间中,所有点到查询点的距离趋于相似
(3) 距离分布
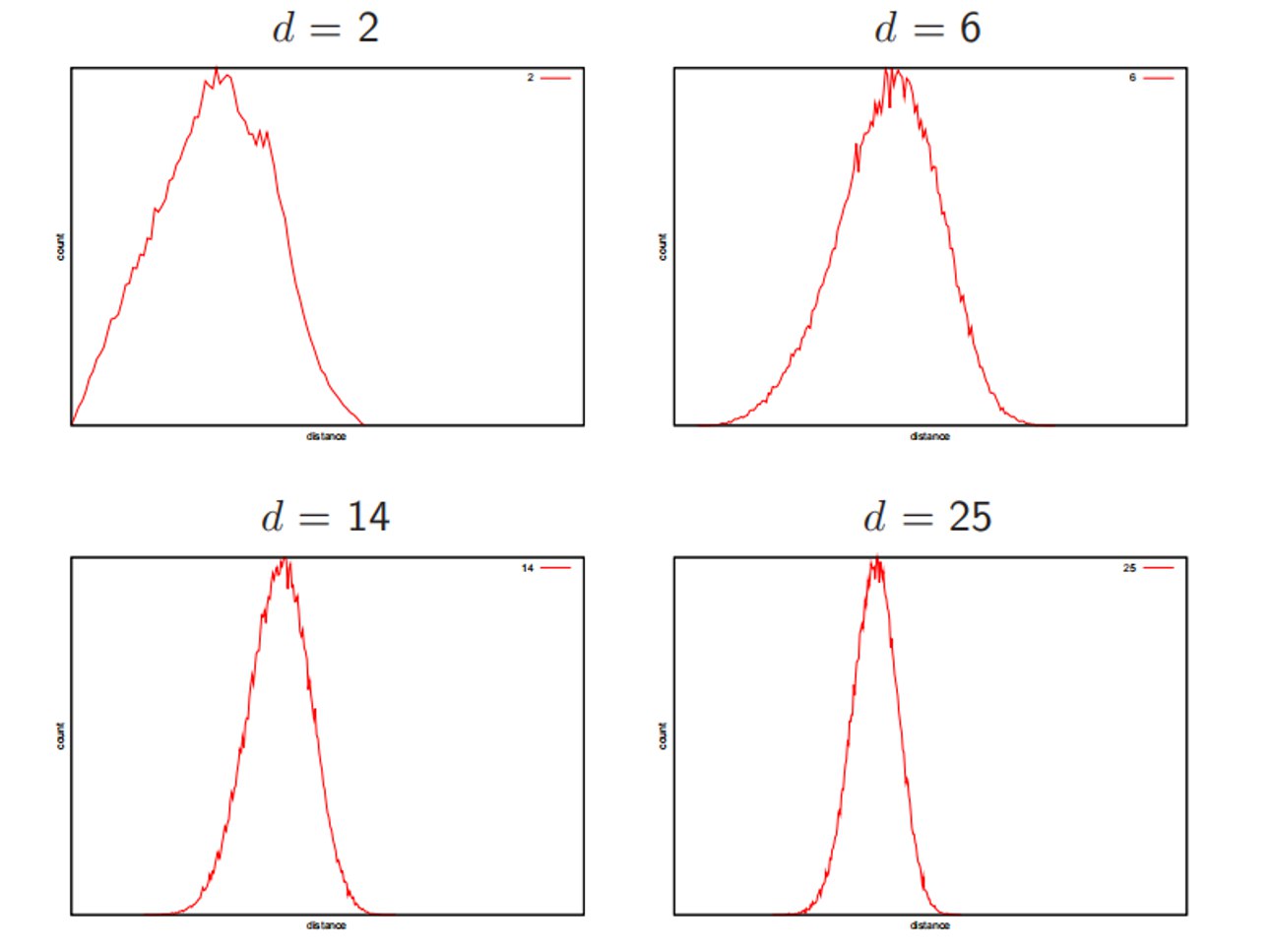
观察: 对于任意点来说,到其他各个点的距离的分布情况随维度变化。
不同维度的距离分布:
- d=2:分布较平缓,有明显的近邻和远邻区分
- d=6:分布变得更集中
- d=14:分布形状变得"尖锐"
- d=25:分布极度集中,几乎所有点距离都接近平均值
结论: 显然,当维度越高时,整体形状会越"尖锐"。
(4) 几何直观
从另一个视角看:
- 在低维空间,查询点周围的点分布有明显的距离差异
- 在高维空间,所有点似乎都在同一个"超球面"上
- 这使得"最近邻“的概念变得模糊
第二讲 尾不等式
一、尾不等式分析概要
1. 问题引入
背景:
很多情况下,精确计算一个随机事件的概率是很困难的。
案例: 一个服从参数分别为 1,000 和 1/3 的二项分布随机变量 X,计算尾概率 Pr[X < 100]。
解决思路:
- 当精确计算比较困难时,利用近似方法求得概率的近似值不失为一种理想的选择
- 但近似方法又会涉及到另一个问题:近似值偏离真实值到底有多大?
问题引入1:抛硬币问题
假设抛一枚均匀的硬币,抛得正面和反面朝上的概率都为0.5,而且每次抛币与前次结果无关。
- 直觉理解:直觉上来说,抛的次数越多正面朝上的频率越接近于0.5;当抛硬币的次数达到一定次数后,正面朝上的频率非常接近于0.5,波动很小
- 核心问题:抛多少次才能以95%的概率保证正面朝上的频率和真实概率间的差距小于某个阈值(比如0.125)呢?
问题引入2:蒙特卡罗方法
用蒙特卡罗方法(Monte Carlo方法)近似计算π的方法,如果随机打点 1,000,000次能保证以95%的概率近似π到2位、3位…小数吗?
注: 蒙特卡罗法也称统计模拟法、统计试验法。是把概率现象作为研究对象的数值模拟方法。是按抽样调查法求取统计值来推定未知特性量的计算方法。
2. 求解尾概率不等式的基本方法
求解一个问题的尾概率的方法通常可以分为两大类:
(1) 定积分、查表法
- 适用场景:当明确知道问题所对应的概率密度函数时
- 方法:可以采用定积分的方式,把尾概率所对应的区域累积起来;简单来说,可以通过查表法(概率教科书后面的表格)或者使用R/Matlab等软件来做
- 案例:标准正态分布表可以查询不同区间的概率值
(2) 尾概率不等式法
- 适用场景:当无法确切知道对应的概率密度函数的时候
- 常见的尾概率不等式包括:Markov不等式、Chebyshev不等式、Chernoff不等式
二、三个常见的尾不等式
1. Markov不等式
定义:
令 \(X\) 为样本空间上的非负随机变量,对任意正实数 $a>0$,有
证明:
定义事件
$$ A = \{\omega \in \Omega \mid X(\omega) \ge a\}. $$随机变量的期望为
$$ E(X) = \sum_{\omega \in \Omega} X(\omega) P(\omega). $$将求和按事件 \(A\) 与其补集拆分: $$ E(X) = \sum_{\omega \in A} X(\omega) P(\omega)
- \sum_{\omega \notin A} X(\omega) P(\omega). $$
由于当 \($\omega \in A$\) 时有 \($X(\omega) \ge a$\),因此
$$ \sum_{\omega \in A} X(\omega) P(\omega) \ge a \sum_{\omega \in A} P(\omega) = a \cdot P(A). $$从而得到
$$ E(X) \ge a \cdot P(A). $$即
$$ P(A) = P(X \ge a) \le \frac{E(X)}{a}. $$案例分析:
令随机变量 $X$ 表示抛 $n$ 次均匀硬币时正面向上的次数,运用 Markov 不等式估计
$$ P\!\left(X > \frac{3n}{4}\right) $$的概率上界。
-
解:
$$ E(X) = np = \frac{n}{2}. $$
每次抛硬币是一次独立的 Bernoulli 实验,成功概率为 $p=\tfrac12$,因此根据 Markov 不等式,
$$ P\!\left(X > \frac{3n}{4}\right) \le \frac{E[X]}{3n/4} = \frac{n/2}{3n/4} = \frac{2}{3}. $$ -
分析:
直觉上,随着抛硬币次数 \(n\) 的增加,正面朝上的频率应趋近于 \(1/2\),
因而频率大于 \(3/4\) 的概率应当减小。
但 Markov 不等式给出的上界与 \(n\) 无关,
说明 Markov 不等式给出的尾概率上界较为松。
2. Chebyshev 不等式
定义:
令 $X$为定义在样本空间 $\Omega$ 上的随机变量,$E(X)$ 与 $Var(X)$ 分别表示 $X$ 的期望和方差。则对任意正实数 \(r>0\),有
证明思路:
注意到
$$ P\!\left(|X - E(X)| \ge r\right) = P\!\left((X - E(X))^2 \ge r^2\right). $$又由于
$$ E\!\left((X - E(X))^2\right) = Var(X), $$对随机变量 \((X - E(X))^2\) 应用 Markov 不等式,得到
$$ P\!\left((X - E(X))^2 \ge r^2\right) \le \frac{E\!\left((X - E(X))^2\right)}{r^2} = \frac{Var(X)}{r^2}. $$因此,Chebyshev 不等式成立。
案例分析:
令随机变量 \(X\) 表示抛 \(n\) 次均匀硬币时正面向上的次数,利用 Chebyshev 不等式估计
$$ P\!\left(X > \frac{3n}{4}\right) $$的概率上界。
-
解:
$$ E(X) = np, \qquad Var(X) = np(1-p), $$
已知其中 $p=\tfrac12$。有
$$ P\!\left(X > \frac{3n}{4}\right) = P\!\left(\frac{X}{n} > \frac{3}{4}\right) = P\!\left(\frac{X}{n} - \frac{1}{2} > \frac{1}{4}\right) $$
$$ < P\!\left(\left|\frac{X}{n} - \frac{1}{2}\right| > \frac{1}{4}\right) \le \frac{16\,np(1-p)}{n^2} = \frac{4}{n}. $$ -
结论:
当 $n=80 时,该概率小于 $5%$。
这说明 Chebyshev 不等式给出的界比 Markov 不等式更紧。
3. Chernoff 不等式
基本概念:
- 独立 Bernoulli 试验:
令 $X_1, X_2, \dots, X_n$ 为 $n$ 个相互独立的随机变量,$P(X_i = 1) = p,P(X_i = 0) = 1-p$。
定义
$$ X = \sum_{i=1}^n X_i $$则 \(X\) 服从二项分布。
- Poisson 试验:
令 $X_1, X_2, \dots, X_n$ 为 $n$ 个相互独立的随机变量,$P(X_i = 1) = p_i,P(X_i = 0) = 1-p_i$。
定义
$$ X = \sum_{i=1}^n X_i $$易知 Bernoulli 试验是 Poisson 试验的特例。
Chernoff 不等式(简化版):
若 $X_i$ 为 $n$ 个相互独立的 Bernoulli 随机变量,且 $P(X_i = 1) = p_i$。
定义
$$ X = \sum_{i=1}^n X_i, \qquad \mu = \sum_{i=1}^n p_i $$则对任意 $\delta \in (0,1)$,有
$$ P\!\left(X < (1-\delta)\mu\right) < \exp\!\left(-\frac{\mu\delta^2}{2}\right) $$以及
$$ P\!\left(X > (1+\delta)\mu\right) < \exp\!\left(-\frac{\mu\delta^2}{4}\right) $$Chernoff 不等式(精确版):
$$ P\!\left(X < (1-\delta)\mu\right) < \left(\frac{e^{-\delta}}{(1-\delta)^{1-\delta}}\right)^{\mu} $$$$ P\!\left(X > (1+\delta)\mu\right) < \left(\frac{e^{\delta}}{(1+\delta)^{1+\delta}}\right)^{\mu} $$证明思路:
仅证明第一个不等式。对任意 $t>0$,有
$$ P\!\left(X < (1-\delta)\mu\right) = P\!\left(e^{-tX} > e^{-t(1-\delta)\mu}\right) $$由 Markov 不等式,
$$ P\!\left(e^{-tX} > e^{-t(1-\delta)\mu}\right) < \frac{E(e^{-tX})}{e^{-t(1-\delta)\mu}} = \frac{\prod_{i=1}^n E(e^{-tX_i})}{e^{-t(1-\delta)\mu}} $$注意到不等式 \(1-x < e^{-x}\),有
$$ E(e^{-tX_i}) = p_i e^{-t} + (1-p_i) = 1 - p_i(1-e^{-t}) < e^{p_i(e^{-t}-1)} $$因此
$$ \prod_{i=1}^n E(e^{-tX_i}) < \prod_{i=1}^n e^{p_i(e^{-t}-1)} = e^{\mu(e^{-t}-1)} $$从而
$$ P\!\left(X < (1-\delta)\mu\right) < \frac{e^{\mu(e^{-t}-1)}}{e^{-t(1-\delta)\mu}} = e^{\mu(e^{-t}+t-t\delta-1)} $$上界关于 $t$ 取最小值。对
$$ \mu(e^{-t}+t-t\delta-1) $$求导并令其为 0,可得
$$ t = \ln \frac{1}{1-\delta} $$代入即可得到结论。
应用案例:
案例 1:球队胜率
某球队赢每场比赛的概率为 $1/3$,各场比赛相互独立。求在 $n$ 场比赛中赢得一半以上比赛的概率上界。
-
分析:
定义
$$ X_i = \begin{cases} 1, & \text{获胜} \\ 0, & \text{失败} \end{cases} $$令
$$ Y = \sum X_i, \qquad \mu = E(Y) = \frac{n}{3}, \qquad \delta = \frac{1}{2} $$应用 Chernoff 不等式,
$$ P(Y > (1+0.5)\mu) < \exp\!\left(-\frac{\mu\delta^2}{4}\right) = \exp\!\left(-\frac{n}{48}\right) $$ -
结论:
$n=40$时概率不高于 $0.43$ $n=100$ 时概率不高于 $0.12$。
精确版本下分别为 $0.23$、$0.027$
案例 1(补充)
某球队赢每场比赛的概率为 $3/4$,各场比赛相互独立。求在 $n$ 场比赛中输掉一半以上比赛的概率上界。
-
分析:
$$ \mu = E(Y) = \frac{3n}{4}, \qquad \delta = \frac{1}{3} $$$$ P(Y < n/2) = P(Y < (1-\tfrac13)\mu) < \exp\!\left(-\frac{\mu\delta^2}{2}\right) = \exp\!\left(-\frac{n}{24}\right) $$ -
结论:
$n=40$ 时概率小于 $0.19$;
$n=100$ 时概率小于 $0.015$。
案例 2:球和箱子
将 $n$ 个球均匀、独立地放入 $n$ 个箱子中。令 $Y_1$ 表示第一个箱子中的球数,求 $m$使得
$$ P(Y_1 > m) \le \frac{1}{n^2} $$-
分析:
$$ p_i = \frac{1}{n}, \qquad \mu = 1 $$$$ P(X > (1+\delta)\mu) < \exp\!\left(-\frac{\mu\delta^2}{4}\right) = \frac{1}{n^2} $$取对数得
$$ \frac{\delta^2}{4} = 2\ln n \quad \Rightarrow \quad \delta = \sqrt{8\ln n} $$
案例 3:集合平衡(Set Balancing)
考虑一个 $n \times m$ 的 0–1 矩阵 $A$,寻找向量
$$ b \in \{-1,+1\}^m $$使得 $\|Ab\|_\infty $ 尽可能小。
-
算法设计:
$$ b_i = \begin{cases} -1, & \text{概率 } 1/2 \\ +1, & \text{概率 } 1/2 \end{cases} $$ -
分析结论:
$$ P\!\left(\|Ab\|_\infty > 2\sqrt{2m\ln n}\right) \le \frac{2}{n} $$
案例 4:抛硬币(Chernoff 版本)
令 \(X\) 为抛 \(n\) 次均匀硬币正面向上的次数。
-
解:
$$ E(X) = \frac{n}{2} $$$$ P\!\left(X > \frac{3n}{4}\right) = P\!\left(X > (1+\tfrac12)E(X)\right) < \exp\!\left(-\frac{n}{32}\right) $$ -
结果:
- $n=50:0.21$
- $n=80:0.08$
- $n=300:0.000085$
4. 尾概率不等式的实际使用
关于尾概率不等式的实际使用,其实是要回答三类问题。这里的原因在于总共有三个控制参数:一个是次数$n$,一个是偏移期望的程度$δ$,另一个是最终的置信度参数。总是可以固定两个参数,求另外一个参数的情况。
问题类型:
- 其一:已知采样次数和偏移的程度,求解置信度
- 其二:已知采样次数和置信度,求解偏移的程度
- 其三:已知置信度和偏移的程度,求解采样次数
第一类问题示例:
例如:投掷了硬币1000次,总的期望值是500,则当 $δ=0.2$ 的时候,即是在询问正面朝上的总次数超过了 $(1+0.2)×500=600$ 的概率。
- 已知:$n=1000,μ=1/2,δ=0.2$,求解置信度
- 根据Chernoff不等式:$$P[X > (1+\delta)n\mu] < \exp(-n\mu\delta^2/4)$$即:$P[X > 600] < \exp(-5) = 0.0067$
第二类问题示例:
例如:总共投掷了1000次,总的期望值是500,则当想要知道正面朝上的概率不低于95%时,能够确保的正面朝上的次数是几次。
- 已知:$n=1000,μ=1/2$,置信度为$0.05$,求解偏移程度
- 根据Chernoff不等式,$P[X > (1+\delta)n\mu] < \exp(-n\mu\delta^2/4)$
- 令 $\exp(-n\mu\delta^2/4) = 0.05$,则:$δ=0.15,(1+0.15)×500=575$
- 则能够以95%的概率确保的正面朝上的次数为575次
第三类问题示例:
至少需要投掷几次硬币,才可确保正面朝上的比率在0.6以下的概率不低于95%。
- 分析:$μ=1/2;(1+δ)μ=0.6 ⇒ δ=0.2$
- 根据Chernoff不等式:$P[X > (1+\delta)n\mu] < \exp(-n\mu\delta^2/4)$
- 可以得到:$\exp(-0.04n\mu/4) < 0.05$
- 求解以上式子,得到:$n > 599.1$
- 所以至少需要投掷600次硬币才能保证正面朝上的比率在0.6以下的概率不低于95%
三、计数问题
1. Morris算法
问题背景与动机:
- 场景描述:某电子商城想记录某本畅销书的销售量
- 传统方法:用一个整数变量来描述,初始化为0,每卖出一本则加1
- 问题分析:用二进制表示数n需要 $\lceil \log_2 n \rceil$ 位,即计算机需要 $\lceil \log_2 n \rceil$ 位存储整数n。当n值比较大时,存储开销会很大,可否降低开销?
Morris算法原理:
核心思想是只需要 $\lceil \log_2 \log_2 n \rceil$ 位就可以近似表示一个大整数。
算法描述:
Morris算法
Input: 事件流F
Output: 指定事件的计数 C
1 初始化计数器X=0
2 while 事件流F未结束 do
3 if 指定事件发生 then
4 以 1/2^X 的概率更新 X=X+1
5 C=2^X-1
6 return C
两个核心操作:
- 更新操作:当指定事件发生时,以 $1/2^X$ 的概率更新X的值为X+1;以 $1-1/2^X$ 的概率保持X的值不变
- 估计计数结果:返回近似估计值 $C = 2^X - 1$
Morris算法示例:
| 事件流 | 真实计数 | 抽样概率 | X的值 | 计数估计值 |
|---|---|---|---|---|
| 0 | 1 | 0 | 0 | |
| 1 | 1 | 1/2 | 1 | 1 |
| 1 | 2 | 1/2 | 1 | 1 |
| 1 | 3 | 1/4 | 2 | 3 |
| 1 | 4 | 1/4 | 2 | 3 |
| 1 | 5 | 1/4 | 2 | 3 |
| 1 | 6 | 1/4 | 2 | 3 |
| 1 | 7 | 1/8 | 3 | 7 |
| 1 | 8 | 1/8 | 3 | 7 |
Morris算法理论分析:
定理:令事件真实计数为N,$X_N$ 是Morris算法维护的计数器,则其输出的估计值 $2^{X_N}-1$ 是真实计数N的无偏估计。
证明过程:
注意到当 $X_{N-1} = j$ 时,$X_N = j+1$ 的概率为 $2^{-j}$,而保持 $X_N = j$ 的概率为 $1-2^{-j}$,因此
$$ E(2^{X_N}) = E(E(2^{X_N}\mid X_{N-1}=j)) $$$$ = \sum_{j \geq 1} P(X_{N-1}=j)\,E(2^{X_N}\mid X_{N-1}=j) $$条件期望 $E(2^{X_N}\mid X_{N-1}=j)$ 计算如下:
$$ E(2^{X_N}\mid X_{N-1}=j) = 2^{j+1}\cdot 2^{-j} + 2^j \cdot (1-2^{-j}) $$$$ = 2^j + 1 $$运用数学归纳法证明最终结果:
- 当 $N=1$ 时,$X_N = 1$,因此 $E(2^1-1) = 1$,结论成立。
- 假设当 $N=k$ 时,$E(2^{X_k}-1) = k$ 成立。
- 当 $N=k+1$ 时,
因此当 $N=k+1$ 时,$E(2^{X_{k+1}}-1) = k+1$ 也成立。
方差分析:
$$ Var(2^{X_N}) = E((2^{X_N})^2) - (E(2^{X_N}))^2 $$$$ = E(2^{2X_N}) - (N+1)^2 $$通过递推可以得到:
$$ E(2^{2X_N}) = \frac{3N(N+1)}{2} + 1 $$所以:
$$ Var(2^{X_N}) \approx \frac{1}{2} N^2 $$2. Morris+算法
问题分析与改进思路:
- Morris算法的劣势:虽然Morris算法给出了真实计数的无偏估计,但随着计数N的增加,该估计的方差以二次多项式的形式在增加
- 统计学重要结论:令 $X_1, X_2, ..., X_n$ 为n个独立同分布的样本,且对任意 $1 \leq i \leq n$ 有 $E(X_i) = \mu$ 和 $Var(X_i) = \sigma^2$,那么样本均值的期望与方差分别为$$E(\sum X_i / n) = \mu$$ $$Var(\sum X_i / n) = \sigma^2 / n$$
- 结论:通过多次估计取平均可以获取波动更小的计数的无偏估计
Morris+算法描述:
核心思想:对事件计数的每次更新维护n个计数,当事件流结束时,计算这n个计数的平均值,会得到波动更小的真实计数的无偏估计。
Morris+算法
输入:事件流F, δ和ε
输出:指定事件计数C
01 n = ⌈1/δε²⌉
02 初始化计数数组 X[1…n]=0
03 while 事件流F未结束 do
04 if 指定事件发生 then
05 for i=1 to n do
06 以1/2^Xi的概率更新Xi=Xi+1
07 for i=1 to n do
08 C=C+2^Xi-1
09 C=C/n
10 return C
Morris+算法分析:
根据方差的性质,相对于Morris算法,Morris+算法返回的计数估计值的方差减小到了 $O(N^2/n)$。
根据Chebyshev不等式,
$$P(|\hat{N} - N| > \varepsilon N) < \frac{Var(\hat{N})}{\varepsilon^2 N^2}$$由于 $Var(\hat{N}) = O(N^2/n)$,因此:
$$P(|\hat{N} - N| > \varepsilon N) < \frac{O(N^2/n)}{\varepsilon^2 N^2} \approx \frac{1}{n\varepsilon^2}$$令 $\frac{1}{n\varepsilon^2} < \delta$,即 $n = O(1/\delta\varepsilon^2)$ 时,$P(|\hat{N} - N| > \varepsilon N) < \delta$
这表明事件计数的估计值是偏离真实值N大于εN的概率小于δ。此时,称 $\hat{N}$ 为N的 (ε,δ)近似估计。
复杂度分析:
- 空间复杂度:总共有 $O(1/\delta\varepsilon^2)$ 个计数器,每个计数器占用 $O(\log\log n)$ 位。因此,空间复杂度是:$O(\log\log n / \delta\varepsilon^2)$
- 时间复杂度(Per-tuple processing cost):每处理一个元素,需要循环 $O(1/\delta\varepsilon^2)$ 次,因此开销是 $O(1/\delta\varepsilon^2)$
3. Morris++算法
拔河(Tug-of-War)思想:
当目标概率是δ时,可以将实例数从 $1/\delta$ 降至 $\log(1/\delta)$。
- 核心思路:运行 t 个Morris+实例,每个实例的失败概率为 1/3,即:$$P(|\hat{N} - N| > \varepsilon N) < \frac{1}{2k\varepsilon^2} = \frac{1}{3}$$注:每个Morris+运行了k个Morris实例,且 $k = O(1/\varepsilon^2)$。然后,输出所有 t 个Morris+实例的中位数估计值。
- 关键观察:失败的 Morris+ 实例的预期数量不超过$t/3$。如果中位数估计值出错,则表明至少一半Morris+ 实例失败了,表示失败实例的数量至少偏离期望值达到 $t/6$。(原因:$t/3 + t/6 = t/2$)
Morris++算法描述:
Morris++算法
输入:事件流F, δ和ε
输出:指定事件计数C
01 n = ⌈ln1/δ⌉, m = ⌈1/ε²⌉
02 初始化数组X[1…n, 1…m]=0, C[1…n]=0
03 while 事件流F未结束 do
04 if 指定事件发生 then
05 for i=1 to n do
06 for j=1 to m do
07 以1/2^Xij的概率更新Xij=Xij+1
08 for i=1 to n do
09 for j=1 to m
10 Ci=Ci+(2^Xij-1)
11 Ci = Ci/n
12 C=C[1…n]的中位数
13 return C
Morris++算法分析:
定义:
$$Y_i = \begin{cases} 1, & \text{if } |\frac{1}{k}\sum_{j=1}^{k} \hat{n}_{ij} - n| > \varepsilon N \ 0, & \text{Otherwise} \end{cases}$$由于 $k = O(1/\varepsilon^2)$,可知:$P(Y_i=1) < 1/3$
由于 $\mu = E(\sum Y_i) = t/3$,通过Chernoff不等式,可知
$$P(\sum Y_i > t/2) \leq P(\sum Y_i > (1+1/2)\mu)$$$$\leq \exp(-\mu(1/2)^2/4) < \exp(-t/48) < \delta$$因此:可知:$t = O(\log 1/\delta)$
最终结论:可以用 $O(\log(1/\delta)/\varepsilon^2)$ 个Morris实例的复杂度来得到 (ε, δ) 近似的算法。
进一步分析:
- 总体思路:利用tug-of-war方法降低了空间复杂度
- 综合运用了Chebyshev不等式和Chernoff不等式:
- 在调用Chebyshev不等式时,目的是将失败概率降低到常数量级(例如1/3)
- 在调用Chernoff不等式时,才将失败概率降低到任意一个给定阈值
- 思考:第一步的失败概率如果是1/4,或者1/2,是否也可行?
第三讲 数据流
一、数据流模型
1. 数据流的定义与特点
什么是数据流?
数据流具有以下四个核心特征:
- 数据总量被假设为无限的
- 数据到达速率极快
- 数据到达次序不受应用所约束
- 每一个数据都只能够被看一次
应用场景:
- 高速路由器上的 IP 包分析
- 传感器网络
- 实时监控系统
- 网络流量分析
2. 数据流模型分类
(1)按照数据特征分类
时间序列模型:
- 每个数据项 $a_i = A[i]$,按照 $i$ 增加的顺序出现,相当于时间序列。
收银机模型(Cash Register Model):
- 假设 $A[i]$ 表示在时刻 $t$ 数据流中第 $i$ 个数据项的数值。
- 对新到达的数据项 $a_t = (j, c_t)$(其中 $c_t > 0$)进行更新:
十字转盘模型(Turnstile Model):
- 假设 $A[i]$ 表示在时刻 $t$ 数据流中第 $i$ 个数据项的数值。
- 对新到达的数据项 $a_t = (j, c_t)$(其中 $c_t$ 可正可负)进行更新:
(2)按照数据处理范围分类
界标模型(Landmark Model):
- 考虑从特定时间点 $t$ 到当前时间点 $d$ 之间的所有数据。
- 范围是 $[t, d-1]$。
滑动窗口模型(Sliding Window Model):
- 令 $W$ 为窗口大小,仅考虑最近 $W$ 个元素。
- 范围是 $[\max(0, d-W), d-1]$。
衰减窗口模型(Decay Window Model):
- 范围是 $[0, d-1]$,但是各个元素的重要程度不同。
- 新元素比旧元素更重要。
3. 数据流算法的要求与挑战
要求:
- 实时性:实时、连续地输出查询结果。
- 低空间复杂度:$O(\text{poly}(\log N, \log M))$
- $N$ 是数据流的长度
- $M$ 是数据流元组的范围
- 近似查询结果:结果值的误差较小,更多内存带来更高精确度。
- 适应性:数据流变化频繁,动态调整参数。
近似算法定义:
考虑输入数据流 $\sigma$,误差参数 $\varepsilon$,概率参数 $\delta$,近似输出 $A(\sigma)$,精确结果 $E(\sigma)$。
- ε-近似算法(相对值版本):$|A(\sigma) - E(\sigma)| < \varepsilon$
- (ε,δ)-近似算法(相对值版本):$\Pr[|A(\sigma) - E(\sigma)| < \varepsilon E(\sigma)] > 1 - \delta$
- ε-近似算法(绝对值版本):$|A(\sigma) - E(\sigma)| < \varepsilon$
- (ε,δ)-近似算法(绝对值版本):$\Pr[|A(\sigma) - E(\sigma)| < \varepsilon] > 1 - \delta$
二、频繁元素-确定性算法
1. 问题定义
频繁元素问题:
给定数据流,求出所有频数占总数 $s$ 以上的元素(例如频数 > 0.1%)。
应用场景:高速路由器上的IP包分析
- Top-k 个最频繁的元素
- 找到所有频率 > 0.1% 的元素
- 元素的频数是多少?
- 范围查询的总频数
- 平均数 + 方差
- 中位数
- 多少个元素具有非零的频数
2. Lossy Counting 算法
(1)基本思想
步骤1:将整个数据流划分为多个"窗口”
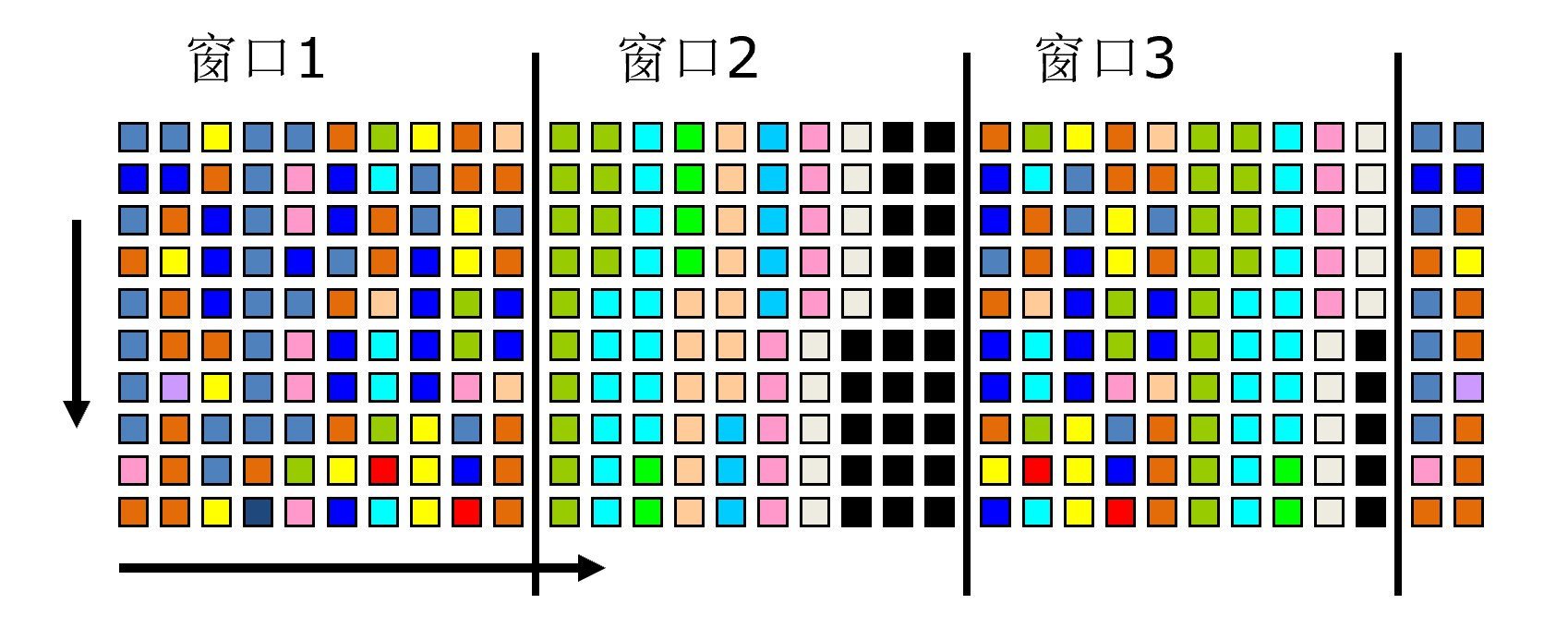
- 窗口的大小 = $1/\varepsilon$
步骤2:维护计数器
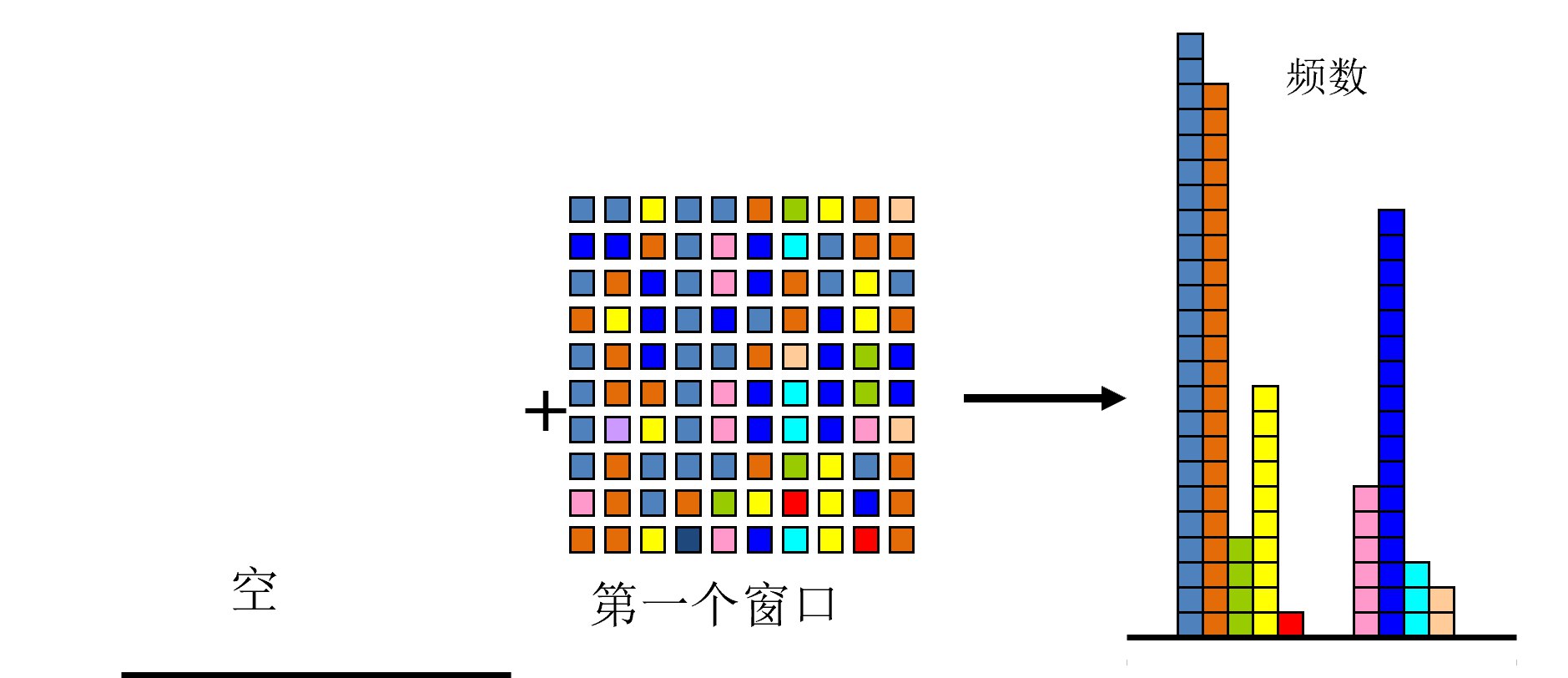
- 对每个到达的元素,如果已有计数器则加1
- 如果没有计数器,创建新的计数器
步骤3:窗口右移
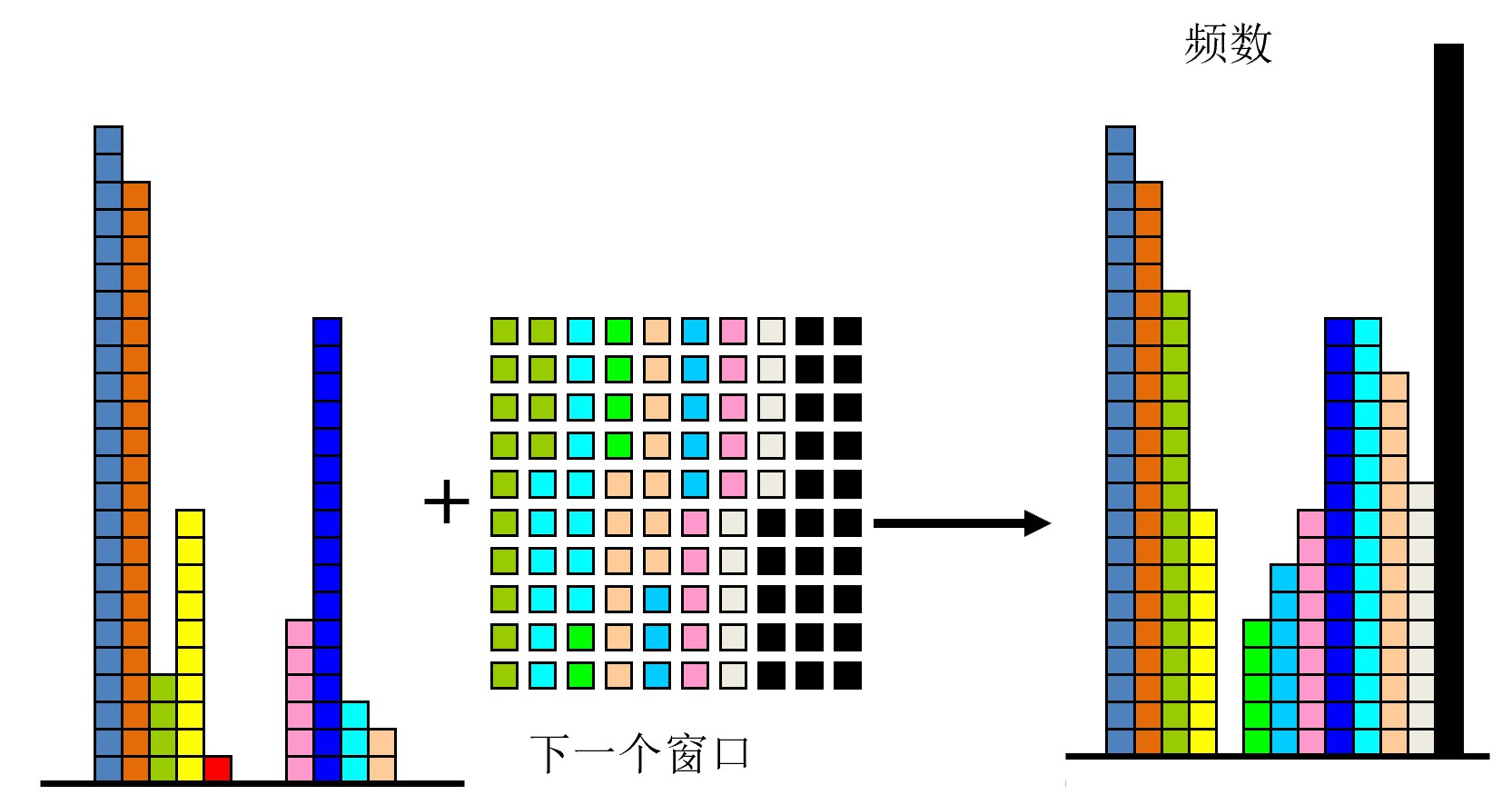
将窗口向右滑动,继续更新统计:
- 窗口滑动:窗口向右移动一个位置
- 更新计数器:
- 新进入窗口的元素(彩色方块):对应计数器+1
- 移出窗口的元素:对应计数器-1
- 删除值为0的计数器
- 增量更新:基于上一个窗口的直方图,只更新变化的部分
- 继续绘制:得到新的直方图,显示当前窗口的频数分布
(2)误差分析
如果当前数据流的大小 = $N$,并且各个窗口大小 = $1/\varepsilon$,那么:
- 窗口个数 = $\varepsilon N$
- 频数误差 ≤ $\varepsilon N$
经验法则: 设定 $\varepsilon = 10% \times s$
例如:给定支持门槛 $s = 1%$,设定误差频数 $\varepsilon = 0.1%$
(3)输出结果
- 每个元素的估计值会大于 $sN - \varepsilon N$
- 最坏情况下需要:$1/\varepsilon \log(\varepsilon N)$ 个计数器
近似保证:
- 被低估的频数最多不超过 $\varepsilon N$
- 没有 false negative 情况发生(符合条件的都选择出来)
- 有 false positives 情况发生,但是这些不符合的元素的频数至少是:$sN - \varepsilon N$
3. Misra-Gries 算法
(1)算法描述
核心思想:
对到达的元素 $a_m$,如果已经为其创建了计数器,便将相应的计数器加1;如果没有相应的计数器,且计数器的个数少于 $k$(意味着内存中还有足够的空间创建新的计数器),则为该元素分配一个新的计数器,并置为1;如果当前计数器的个数为 $k$(意味着内存中没有足够的空间创建新的计数器),则把所有的计数器减1,然后删除值为0的计数器。
算法伪代码:
输入:数据流 σ = <a₁,a₂,...,aₘ>, aᵢ∈[n], 正整数 k
输出:数据流 σ 中的频繁元素集合 F
01 F = ∅;
02 while 数据流 σ 非空 do
03 数据流 σ 中第i个元素到达;
04 if aᵢ∈keys(F) then
05 Fᵢ = Fᵢ + 1;
06 else
07 if |keys(F)| < k-1 then
08 Fᵢ = 1;
09 else
10 for aⱼ∈keys(F) do
11 Fⱼ = Fⱼ - 1;
12 if Fⱼ = 0 then
13 从F中移除aⱼ;
14 return 频数估计数组F;
(2)案例
假设 $k=3$,给定一个输入流:$\langle a,b,a,c,d,e,a,d \rangle$,利用 Misra-Greis 算法求解该数据流中的频繁元素。
| 输入 | 操作 | 结果 |
|---|---|---|
| a | 插入 | $F = {(a, 1)}$ |
| b | 插入 | $F = {(a, 1), (b, 1)}$ |
| a | 更新 | $F = {(a, 2), (b, 1)}$ |
| c | 插入 | $F = {(a, 2), (b, 1), (c, 1)}$ |
| d | 删除 | $F = {(a, 1)}$ |
| e | 插入后删除 | 插入:$F = {(a, 1), (d, 1),(e,1)}$ 删除:$F=()$ |
| a | 更新 | $F = {(a, 1)}$ |
| d | 更新 | $F = {(a, 1), (d, 1)}$ |
(3)性能分析
令 $m$ 是流中所有元素的频数之和,$m'$ 是当前所有计数器之和。对于元素 $a$,估计频数 $\hat{f}_a$ 与真实值 $f_a$ 之间满足:
$$f_a - \frac{m - m'}{k} < \hat{f}_a < f_a$$结论:
- Misra-Gries 算法对元素出现频率的估计总是偏低的
- $k$ 越大(即计数器的集合越大),频率的估计误差越小
- 最终结果能够保证没有假阴性(false negative),即不会漏掉实际频率高于 $m/k$ 的元素
- 但可能会出现假阳性(false positive),混入实际频率低于 $m/k$ 的元素
4. SpaceSaving 算法
(1)基本思想
SpaceSaving 算法构建在 Misra-Gries 算法的基础上,借鉴了 Lossy Counting 的合并思路。
处理规则:
- 如果元素在集合中,将其对应的计数器自增
- 如果元素不在集合中且集合未满,就将元素加入集合,计数器设为1
- 如果元素不在集合中且集合已满,将集合内计数器值最小的元素移除,将新元素插入到它的位置,并且在原计数值的基础上自增(这里维护计数值最小的元素可以用传统的堆)
(2)性能分析
- 所有计数器的和一定等于数据流的总元素数 $m$(因为不需要做减法,只需要自增)
- 那些没有被移除过的元素的计数值是准确的
- 集合中最小的计数值 $\min$ 一定不会大于 $m/k = \varepsilon m$
- 能够保证找出所有频率大于 $\varepsilon m$ 的元素
- 元素出现频率的估计误差同样在 $\varepsilon m$ 的范围内,不过会偏高
优势:
- 只需要 $O(k)$ 的空间
- 除了第三种情况的处理方式不一样外,与 Misra-Gries 算法类似
缺点:
- Space Saving 算法也有假阳性的问题,特别是在非频繁项集中位于流的末尾时
三、频繁元素-随机算法
1. 简单抽样算法
(1)核心思想
对于到达的元素 $a_i$,以概率 $p = M/m$ 对该元素的频数加1。其中:
- $M$ 表示抽样后的数据流大小
- $m$ 表示原数据流大小
(2)算法描述
输入:数据流 σ = <a₁,a₂,...,aₘ>, 抽样概率 p
输出:元素频数数组 f
1 f = 0;
2 while 元素 aᵢ 到达 do
3 产生 [0,1] 之间的一个服从均匀分布的随机变量 r
4 if r < p then
5 更新 cᵢ = cᵢ + 1;
6 f̂ᵢ = cᵢ/p;
7 return f
两个操作:
- 更新操作:当元素 $a_i$ 到达时,以 $p$ 的概率更新 $c_i$ 的值;以 $1-p$ 的概率保持 $c_i$ 的值不变
- 估计元素频数:返回元素频数数组,其中每个元素的频数为 $c_i/p$
(3)案例
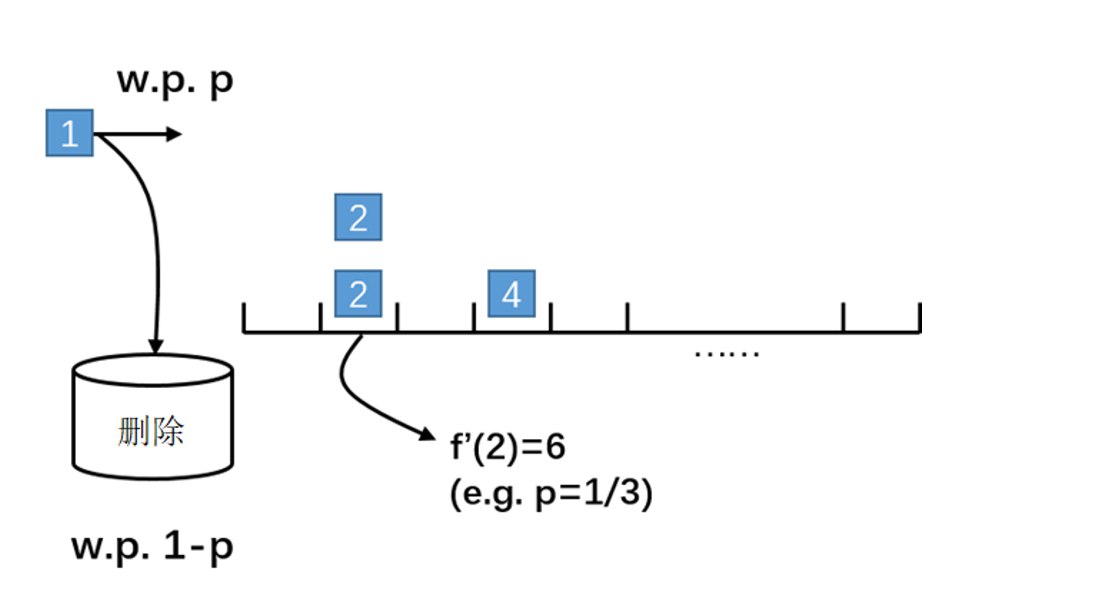
给定一个数据流:$\langle 2,2,1,2,2,4,5,4,4,2 \rangle$,经过简单抽样后,各元素的频数分别为 $c_1=0, c_2=2, c_4=1, c_5=0$。(案例当中的p值为$1/3$)
元素2的频数被估计为:$f'(2) = c_2/p = 2/(1/3) = 6$
(4)性能分析
简单抽样算法成为 $(ε,δ)$-近似算法的空间需求是 $O(m\log(1/\delta)/\varepsilon^2)$,其中:
- $m$ 为原数据流大小
- $\varepsilon$ 是误差因子
- $\delta$ 是控制误差在一定范围的尾概率上界
2. 基础计数算法(Basic Count Sketch)
(1)算法思想
- 维护一个计数数组 $C$ 和两个哈希函数 $h$、$g$
- 哈希函数 $h$ 将 $n$ 个元素均匀地映射到 $k$ 个位置
- 哈希函数 $g$ 将 $n$ 个元素映射为 $-1$ 或者 $+1$
- 对于一个新到达的元素,将其位置上的计数加1或减1
- 对于查询元素 $a$,估计出的频数为 $g(a)C[h(a)]$
(2)算法描述
输入:数据流,查询元素 a
输出:元素 a 出现的频数
1 初始化:C[1...k] ← 0, k = 3/ε²;
2 选择哈希函数 h:[n]→[k]
3 选择哈希函数 g:[n]→{-1,1}
4 处理:(j, c),其中 c=1;
5 while 有数据到达 do
6 C[h(j)] ← C[h(j)] + c·g(j);
7 return f̂ₐ = g(a)C[h(a)];
(3)案例
假设输入数据流为:$\langle a,b,c,a,b,a \rangle$,计数器个数为3,那么不用进行哈希就可以得到各元素的频数,即:$f_a=3, f_b=2, f_c=1$。但是如果只有2个计数器,并且 $h(a)=h(b) \neq h(c)$,试计算各元素的频数。
对于 $a, b, c$ 三个元素,有8种可能的哈希函数 $g$,使得 ${a,b,c} \to {-1,+1}$。
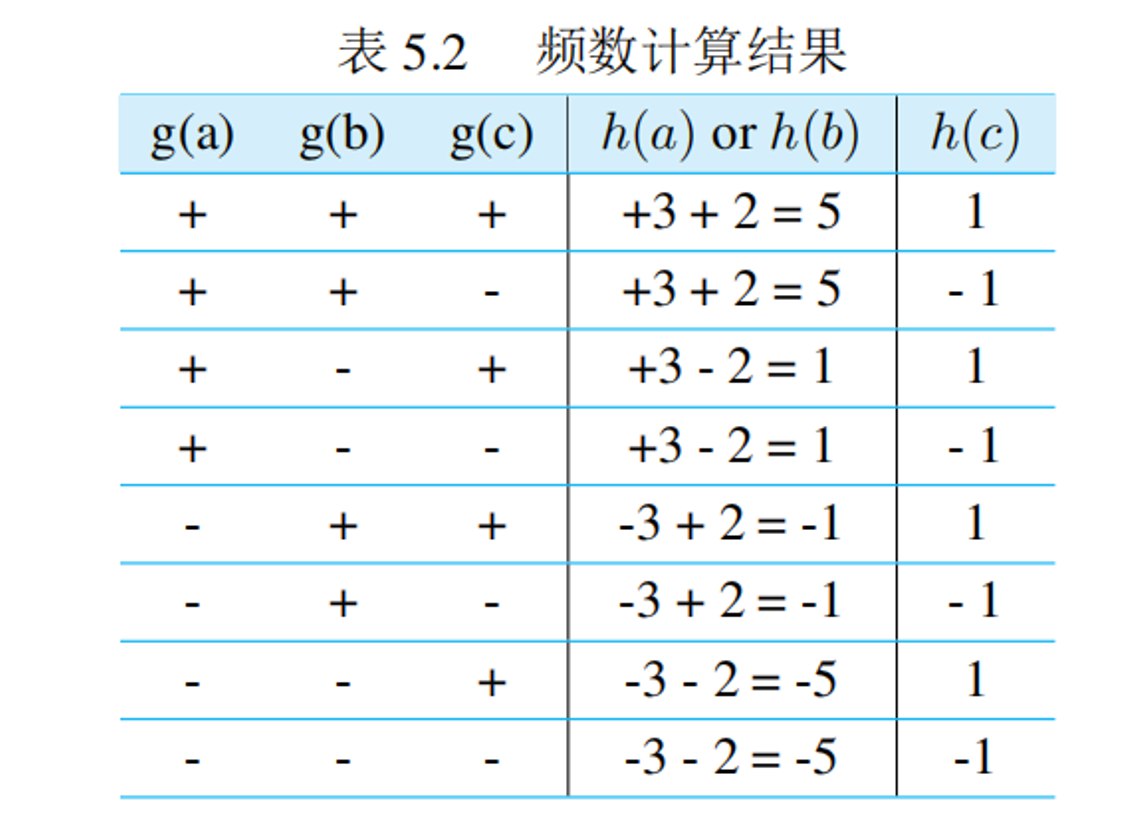
通过对所有可能的 $g$ 函数取平均,得到:
$$f_a = \frac{(5+5+1+1) - (-5-5-1-1)}{8} = 3$$$$f_b = \frac{(5+5-1-1) - (-5-5+1+1)}{8} = 2$$$$f_c = \frac{(1+1+1+1) - (-1-1-1-1)}{8} = 1$$(4)性能分析
- 频数估计值的期望与实际频数相等
- 理由:除了待估计的元素 $a$ 的 $g(a)$ 值是已知的,其他所有元素的 $g(\cdot)$ 值都是未知的。这些元素的期望值 $E(g(\cdot))$ 都等于0
- 方差值:$\text{Var}(\hat{f}(a)) = |f_{-a}|_2^2/k$
- 观察:当 $k$ 值增大的时候,存储计数组的空间增大,方差随之缩小
- 调用 Chebyshev 不等式,得:
- 因此,需要 $k = O(1/\varepsilon^2\delta)$ 使得 $\hat{f}_a$ 偏离真实值超过 $\varepsilon |f|_2$ 是小于 $\delta$
- 本算法的空间需求是 $k = O(1/\varepsilon^2\delta)$,与数据流大小无关,因此,适合数据流场景
3. 计数算法(Count Sketch)
(1)算法思想
通过运用 Tug of War 技术,Count Sketch 算法的复杂度降低到 $O(\frac{\log(1/\delta)}{\varepsilon^2})$。
(2)算法描述
输入:数据流,查询元素 a
输出:元素 a 出现的频数
1 初始化:C[1...k] ← 0, k=3/ε², t=O(log(1/δ));
2 选择 t 个哈希函数 h₁, ..., hₜ: [n]→[k]
3 选择 t 个哈希函数 g₁, ..., gₜ: [n]→{-1,1}
4 处理:(j, c),其中 c=1;
5 while 有数据到达 do
6 for i=1 to t do
7 C[i][hᵢ(j)] ← C[i][hᵢ(j)] + c·gᵢ(j);
8 return f̂ₐ = median₁≤ᵢ≤ₜ gᵢ(a)C[i][hᵢ(a)];
(3)性能分析
- 这表明 Count Sketch 算法的精度只与算法的精度参数 $\varepsilon$ 和 $\delta$ 有关,与数据流规模的大小无关
- 因此,Count Sketch 算法可以很好地解决数据流中元素的频数估计问题
4. Count-min 算法
(1)基本思想
- 一个全局计数器 $N$,表示元素的总频数
- 一个二维计数器数组 $S[m][h]$
- $h$ 个哈希函数:$H_1, H_2, \ldots, H_h$
- 映射规则:$[1..M] \to [1..m]$
- 对于任一元素 $k$,其关联计数器被表示为:
(2)更新操作
当元素 $i$ 到达时:
$$ N \leftarrow N + 1 $$$$ \forall j \in [1..h]: \quad S[H_j(i)][j] \leftarrow S[H_j(i)][j] + 1 $$(3)查询操作
估计元素 $a$ 的频数:
$$ \hat{f}_a = \min_{1 \leq j \leq h} S[H_j(a)][j] $$(4)完整示例
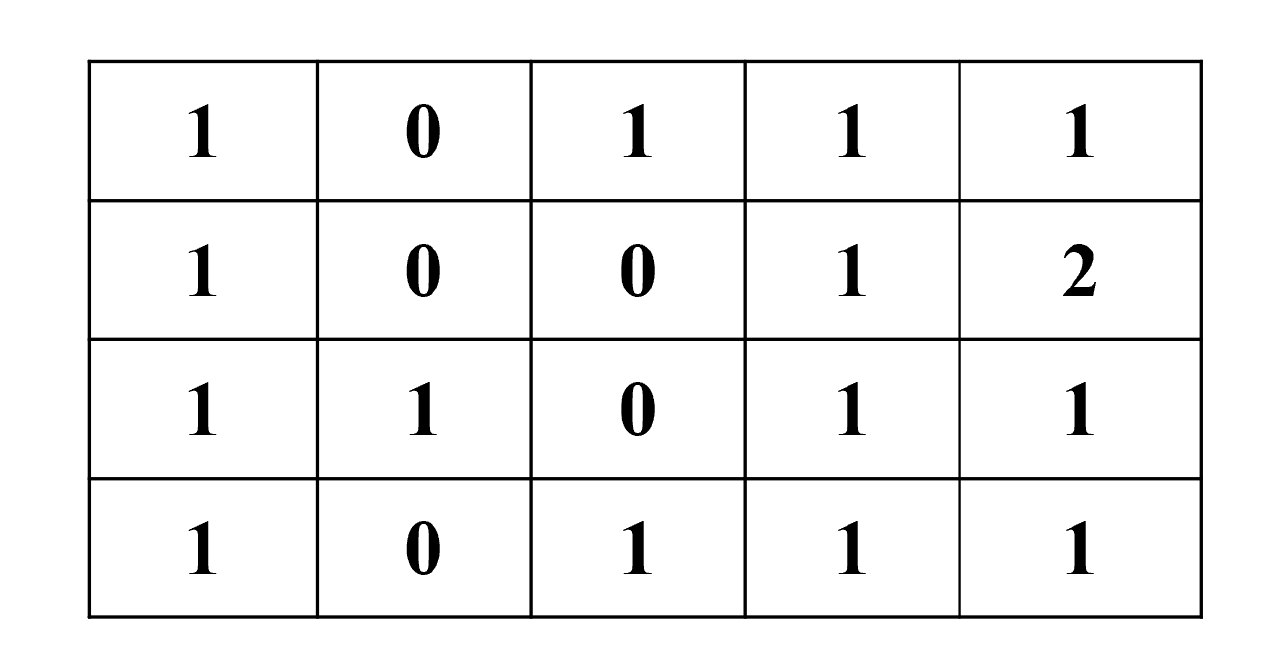
问题设置:
- 假设 $M = 16$
- 数据流:Time: ……, 5, 6, …;Item: ……, 9, -6, …
- 哈希表 $S[5][4]$(5列4行)
- 关联计数器:
- Item 6: $\langle S[4][1], S[4][2], S[0][3], S[3][4] \rangle$
- Item 9: $\langle S[4][1], S[3][2], S[0][3], S[4][4] \rangle$
步骤1:在时间点4的状态
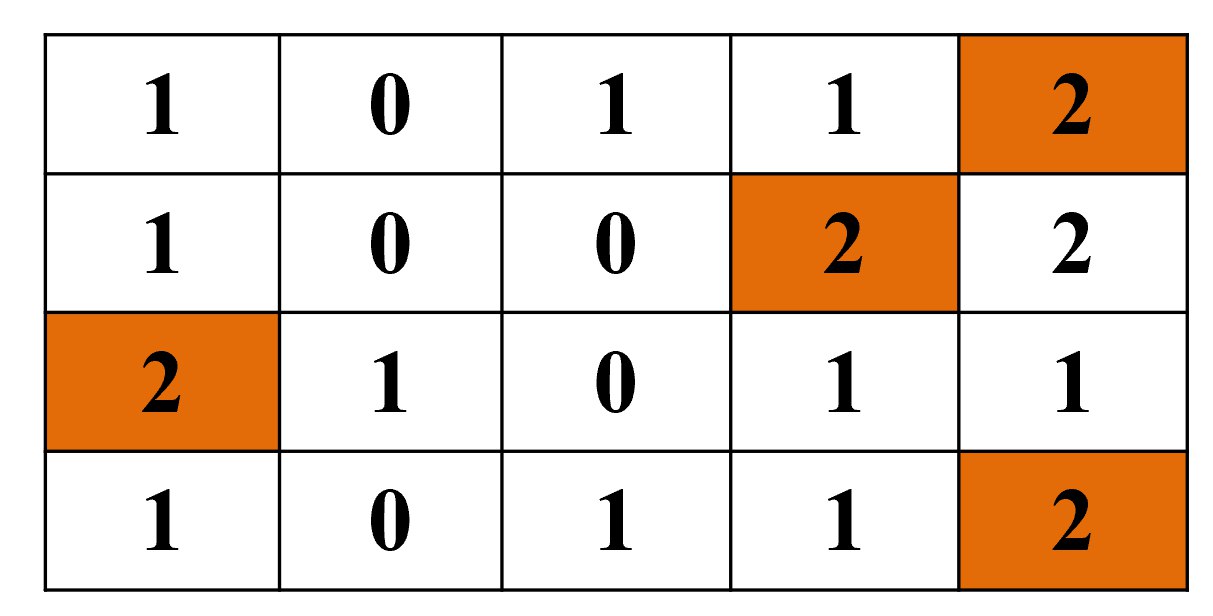
步骤2:在时间点5执行 Insert(9) 操作
根据Item 9的哈希映射 $\langle S[4][1], S[4][2], S[0][3], S[3][4] \rangle$,更新对应位置(橙色标记):
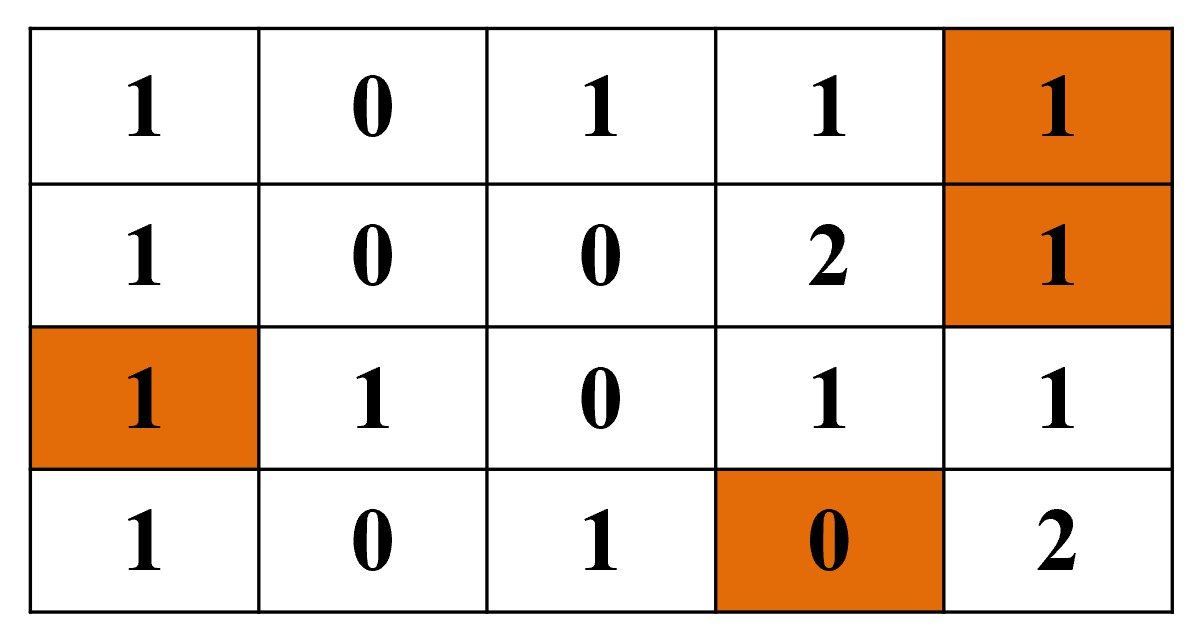
步骤3:在时间点6执行 delete(6) 操作
根据Item 6的哈希映射 $\langle S[4][1], S[3][2], S[0][3], S[4][4] \rangle$,更新对应位置(橙色标记):
步骤4:最后,在时间点38的状态
经过多次操作后的最终状态:
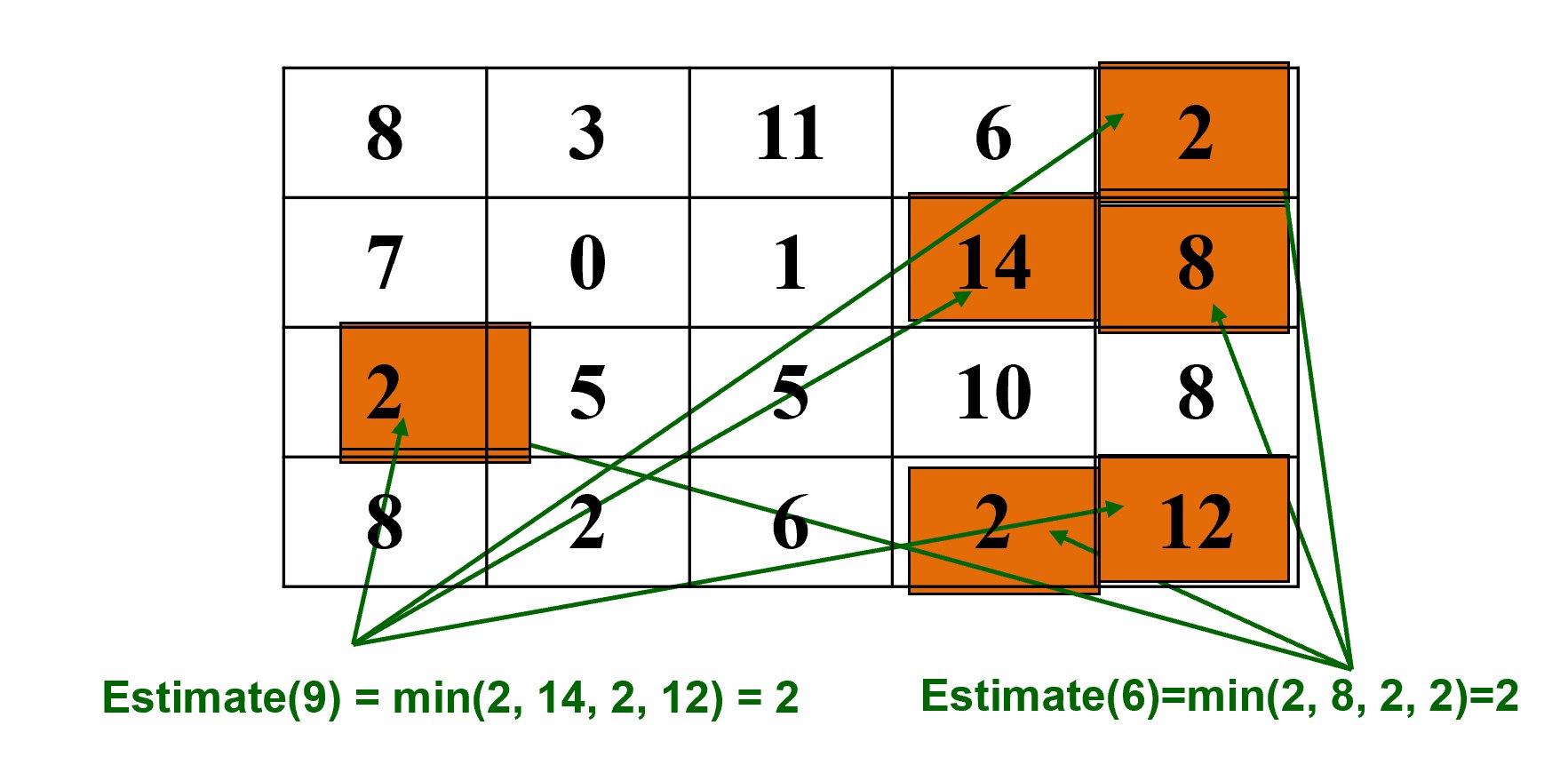
查询结果:
$$ \text{Estimate}(9) = \min(2, 14, 2, 12) = 2 $$$$ \text{Estimate}(6) = \min(2, 8, 2, 2) = 2 $$算法示意图:
对于元素 $i_t$,通过 $h$ 个哈希函数 $h_1, h_2, \ldots, h_d$ 映射到二维数组的不同行,每个映射位置的计数器增加 $c_t$:
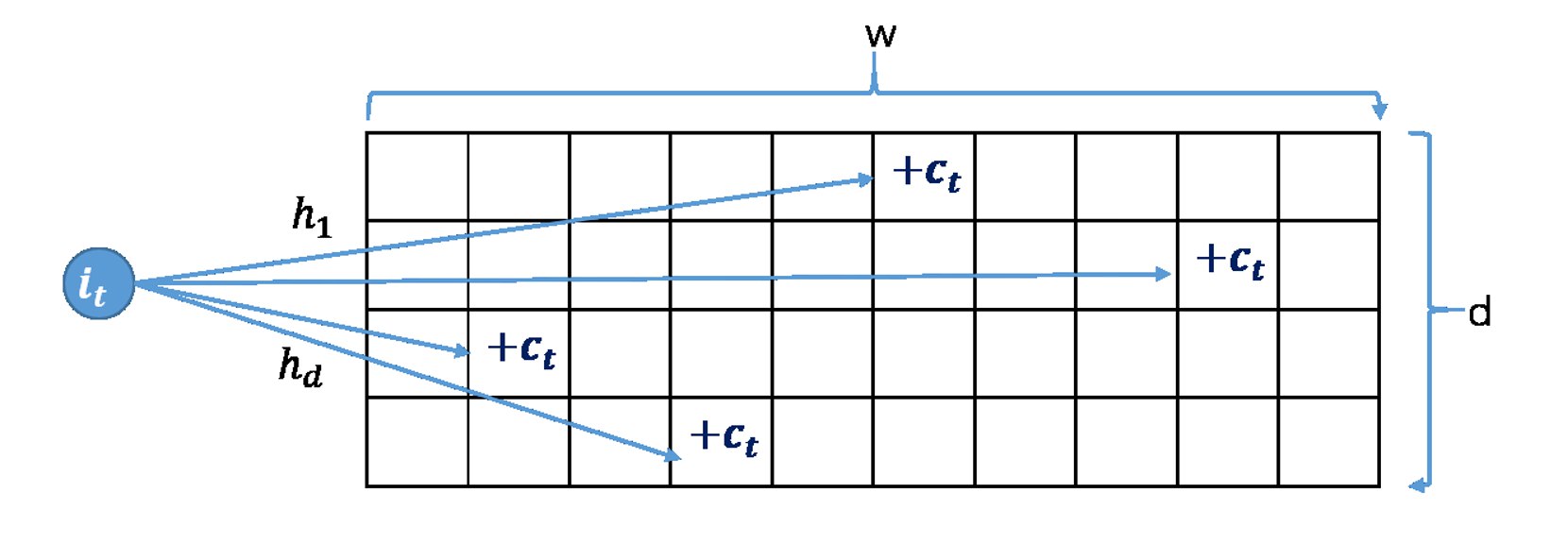
(5)性能分析
理论证明:
先考虑任一行 $i$:
- 对于每个项 $S[i][j]$ 来说,分摊到的其他所有元素的频数总额(总误差)不超过 $|f_{-a}|_1$
- 显然,期望频数为 $|f_{-a}|_1/k$
直接调用 Markov 不等式,得:
$$ P[X_i \geq \varepsilon |f|_1] \leq P[X_i \geq \varepsilon |f_{-a}|_1] \leq \frac{|f_{-a}|_1}{k\varepsilon |f_{-a}|_1} = \frac{1}{k\varepsilon} $$由于总共有 $d$ 行,返回的是最小值。这意味着,这个最小值超过阈值的概率不超过:
$$ \left(\frac{1}{k\varepsilon}\right)^d $$结论:
本方法的空间复杂度为:
$$ O\left(\frac{\log(1/\delta)}{\varepsilon}\right) $$四、滑动窗口模型
1. 统计数据流问题定义
滑动窗口模型:
- 令 $W$ 为窗口大小,仅考虑最近 $W$ 个元素
- 窗口范围是 $[\max(0, d-W), d-1]$
应用场景:
- 统计数据流上的"1"比特位的数量
- 滑动窗口下的最大值问题
- 滑动窗口下的均匀采样问题
问题定义
统计数据流上的"1"比特位的数量:给定一个二进制数据流,每位为"0"或者"1"。在最近的 $k$ 个比特里头,有多少个"1"?其中 $k \leq N$。
简单的解决方案:
- 存储最近的 $N$ 个比特
- 当新的比特位到达时,抛弃前面第 $N+1$ 个比特
挑战:
- 事实:除非存储窗口内所有比特位,否则无法获取确切答案
- 如果无法存储 $N$ 比特位(例如 $N = 1,000,000,000$),那还能怎么办?
- 幸运的是,通常情况下近似答案也是可以接受的
- 挑战:在数据流上"0"和"1"的分布可能非常不均匀
2. DGIM 方法
(1)基本思想
使用"桶"(bucket)来组织数据,每个桶代表一定数量的"1"。
三条关于桶的属性:
- 桶的大小为2的幂次方,每种桶要么1个,要么2个
- 桶和桶之间不重叠
- 桶按照尺寸大小排列
(2)桶更新
当一个新比特到达时:
- 如果最旧的桶中所有比特位都过期,则去除这个最旧的桶
- 如果当前的比特位是0:无需做额外的改变
- 如果当前的比特位是1:
- 创建一个新的桶,大小为1,仅包含这个新比特位
- 如果有三个大小为1的桶,则将最旧的两个桶合并成一个大小为2的桶
- 如果现在有三个大小为2的桶,则将最旧的两个桶合并成一个大小为4的桶
- 如此循环…

(3)如何查询
如何估计最近的 $N$ 个比特中的"1"的数量:
- 将所有桶(除了最后一个)的大小累加起来
- 最后一个桶的大小按照折半计算
注意:我们并不知道最后一个桶里面有多少个1仍然在预计的窗口之中。
(4)误差分析
为何误差是 50%?
假设最后一个桶的大小是 $2^r$:
- 则假设 $2^{r-1}$(一半)1比特仍然在窗口内,误差最多是 $2^{r-1}$
- 由于每个小于 $2^r$ 的桶大小都至少有一个桶,因此真实的和至少为:$1 + 2 + 4 + ... + 2^{r-1} = 2^r - 1$
- 因此,误差最多是 50%
思考: 如何进一步降低误差?
可以将"每种桶要么1个,要么2个"的规则改为"每种桶要么1个,要么2个,要么3个…要么 $r-1$ 个",这样可以将误差降低到 $O(1/r)$。
3. 滑动窗口下的最大值问题
问题定义:
给定时间序列数据流,在滑动窗口内找到最大值。
解法:
示例:$N=8$

维护一个递减的候选列表:
- 当新元素到达时,从后往前删除所有小于新元素的候选
- 将新元素加入候选列表
- 当窗口滑动时,删除过期的元素
性能: 每个元素最多被处理两次(一次加入,一次删除),时间复杂度 $O(1)$ 均摊
4.Chain-Sample 算法(滑动窗口下的均匀采样)
(1)问题定义
在滑动窗口模型下,如何进行均匀采样?
(2)算法步骤
设 $i$ 为当前元组序号,$n$ 为窗口大小,$k$ 为样本大小:
- 各个新元素以概率 $1/\min(i,n)$ 被选中,加入样本集合
- 当元素被选入到样本中,选择另一新元素的索引号,该元组将在旧元素过期后替代它
- 当第 $i$ 元素过期时,当前窗口变为 $(i+1...i+n)$,因此从该范围中选择索引
- 一旦该索引的元素到达时,将其存储起来,并同样为其选择一个替代的索引。即:创建了一个潜在的替换链表
- 当某元素从样本中被舍弃时,同时舍弃其链表
(3)案例

假设样本大小 $k=1$;窗口大小 $n=10$
数据流:$3, 5, 1, 4, 6, 2, 8, 5, 2, 3, 5, 4, 2, 2, 5, 0, 9, 8, 4, 6, 7, 3$
- 元素3被选中,选择下一个替换索引(例如第10个位置)
- 当第10个元素到达时,检查是否需要替换
- 继续维护替换链表
(4)性能分析
令 $T(i)$ 表示某元素的链表的期望长度,此时 $i$ 表示第 $i$ 个尚未过期的元素:
- $T[1] = 1$
- $T[i+1] = 1 + (1/n)\sum_{j=1}^i T[j]$
则链表的期望长度小于等于 $T(n) \approx e \approx 2.718$
期望的内存占用率为:$O(k)$
第四讲 分布式数据流
一、分布式数据流模型
1. 分布式数据流场景
(1) 网络监控场景
背景:
- 网络设备上的24×7 IP数据包/流量数据流
- 真正的大规模数据流快速到达
- AT&T每天收集600到800 GB的NetFlow数据
- 通常传输到异地的数据仓库进行离线分析
NetFlow数据示例:
| 源地址 | 目标地址 | 时长 | 大小 | 协议 |
|---|---|---|---|---|
| 10.1.0.2 | 16.2.3.7 | 12 | 20K | http |
| 18.6.7.1 | 12.4.0.3 | 16 | 24K | http |
| 13.9.4.3 | 11.6.8.2 | 15 | 20K | http |
| 15.2.2.9 | 17.1.2.1 | 19 | 40K | http |
| 12.4.3.8 | 14.8.7.4 | 26 | 58K | http |
传统架构问题:
- 后端数据仓库离线分析——缓慢、昂贵
- 需要实时且仅通过一次来处理网络流
(2) 典型网络监控查询
SQL连接查询:
-- 在过去的一个月中,最常出现的前1000个(源地址,目的地址)对
SELECT COUNT(R1.source, R2.dest)
FROM R1, R2
WHERE R1.dest = R2.source
集合表达式查询:
- 有多少不同的(源地址,目的地址)对被R1和R2观察到,但没有被R3观察到?
(3) 实时数据流分析需求
关键任务:
- 欺诈检测
- 拒绝服务攻击(DDoS)检测
- SLA违规监控(Service Level Agreement)
- 实时流量工程以提高资源利用率
核心要求:
- 权衡通信和计算以减轻负载
- 使响应快速,最小化网络资源使用
- 尽量减少节点上的存储和处理成本
(4) 传感器网络场景
应用领域:
- 环境监测
- 军事应用
- 许多(数百、数千、数百万)传感器散布在地形上
传感器功能:
- 测量光线、温度、压力
- 探测信号、移动、辐射
- 记录音频、图像、动作
资源限制:
- 有限的电池电量、内存、处理器能力
- 无线电覆盖范围有限
- 通信是电池耗电的主要原因
- “传输一个比特的数据相当于执行800条指令”
2. 分布式数据流模型定义
(1) 核心特征
分布式特性:
- 数据流物理上分布在远程站点
- 例如:边缘路由器的UDP数据包流
整体性查询:
- 并集进行查询:$Q(S_1 \cup S_2 \cup \ldots)$
- 流式数据在整个网络中分布
复杂性:
- 比集中式数据流更加复杂
- 需要空间、时间、通信效率高
- 最小化网络开销
- 最大化网络寿命(例如:传感器电池寿命)
- 无法承受将所有流数据"集中化"
(2) 查询模型分类
一次性查询(One-shot queries):
- 按需从网络中"拉取"查询结果
- 通信轮次为一次或少数几次
- 节点可以为一类查询做准备
连续查询(Continuous queries):
- 在查询地点持续跟踪/监控结果
- 在(近)实时中检测异常/离群行为
- 即"分布式触发器"
- 挑战在于最小化通信,使用"推送式"技术
- 可能会将一次性算法作为子程序使用
(3) 近似与随机化
必要性:
- 最小化通信开销通常需要近似和随机化
示例:持续监控平均值
- 精确答案:必须发送每一次变化
- 近似值:只需发送"显著"的变化
随机方法的重要性:
- 统计相异元素数量需要随机性
- 否则必须发送完整数据
(4) 通信网络特性
拓扑结构:
- 平面型:所有节点地位相同
- 层次型:存在协调者或根节点
- 完全分布型:例如P2P DHT(分布式哈希表)
其他特性:
- 单播(传统有线)
- 多播
- 广播(无线电网络)
- 节点故障、数据丢失、间歇性连接等
二、聚集查询
1. 树状结构基础
网络结构:
- 树状结构是基本的构建单元
- 在传感网等领域已有大量工作致力于构建通信树
- 假设树已经构建好,专注于固定树上的问题
树的类型:
- 二层结构
- 常规树
简单方案的局限: 将所有数据向上推送到树根并在基站进行计算存在明显缺点:给靠近根的节点带来负担,导致电池耗尽和网络断开;非常浪费,未能节省通信资源。
改进方向: 需要进行高效的网络内计算,处理各种聚集查询,包括SQL原语(MIN、MAX、SUM、COUNT、AVG)、更复杂的操作(去重计数、点查询与范围查询、分位数、小波变换、直方图、抽样),以及数据挖掘任务(关联规则、聚类等)。
2. 生成/融合/评估框架
框架定义: 为网络内聚集查询建立形式化框架,包含三个核心组件:
- 生成(Generate),g(i): 接收输入并生成摘要(在叶节点)
- 融合(Fusion),f(x,y): 合并两个摘要(在内部节点)
- 评估(Evaluate),e(x): 输出结果(在根节点)
典型示例:
- 最大值(MAX):$g(i) = i,f(x,y) = max(x,y),e(x) = x$
- 平均值(AVG):$g(i) = (i, 1),f((i,j), (k,l)) = (i+k, j+l),e(i,j) = i/j$
- 通用形式:$g(i) = \{i\},f(x,y) = x ∪ y$(需要限制 $|f(x,y)|$ 的大小)
3. 聚集查询的分类
分类维度:
- 重复值敏感性: 如果报告了多个相同的值,答案是否会改变?
- 示例或汇总: 结果是输入中的某个值(如最大值)还是对输入的一个小汇总(如求和)?
- 单调性: $F(X \cup Y)$ 相对于 $F(X)$ 和 $F(Y)$ 是否单调,影响选择操作的下推
- 部分状态: $|g(x)|$, $|f(x,y)|$ 的大小是固定的还是递增的?聚集是代数的还是整体的?
聚集查询分类表:
| 聚集类型 | 重复值敏感 | 样本/总结 | 单调 | 代数/整体 |
|---|---|---|---|---|
| min, max | × | 样本 | √ | 代数 |
| sum, count | √ | 总结 | √ | 代数 |
| average | √ | 总结 | × | 代数 |
| 中位数、分位数 | √ | 样本 | × | 整体 |
| 相异元素数量 | × | 总结 | √ | 整体 |
| 采样 | √ | 样本集合 | × | 代数? |
| 直方图 | √ | 总结 | × | 整体 |
4. 整体性聚集查询与草图摘要
整体性查询的挑战:
- 需要整个输入来进行计算,没有任何摘要信息足够
- 例如count distinct需要记住所有不同元素以判断新元素是否与现有元素均不同
解决方案: 采用采样、数据规约、流处理等技术,使用草图(Sketch)摘要或其他可合并的摘要信息。
草图摘要(Sketch)原理:
- 数据的一种伪随机线性投影,符合生成/融合/评估模型
- 假设输入是向量 $x_i$,且聚合是 $F(\sum_i x_i)$
- $x_i$ 的草图 $g(x_i)$ 是矩阵乘积 $Mx_i$
- 两个草图的组合是它们的加总:$f(g(x_i), g(x_j)) = M(x_i + x_j) = Mx_i + Mx_j = g(x_i) + g(x_j)$
- 提取函数 $e()$ 取决于草图类型
Count-Min草图(CM Sketch):
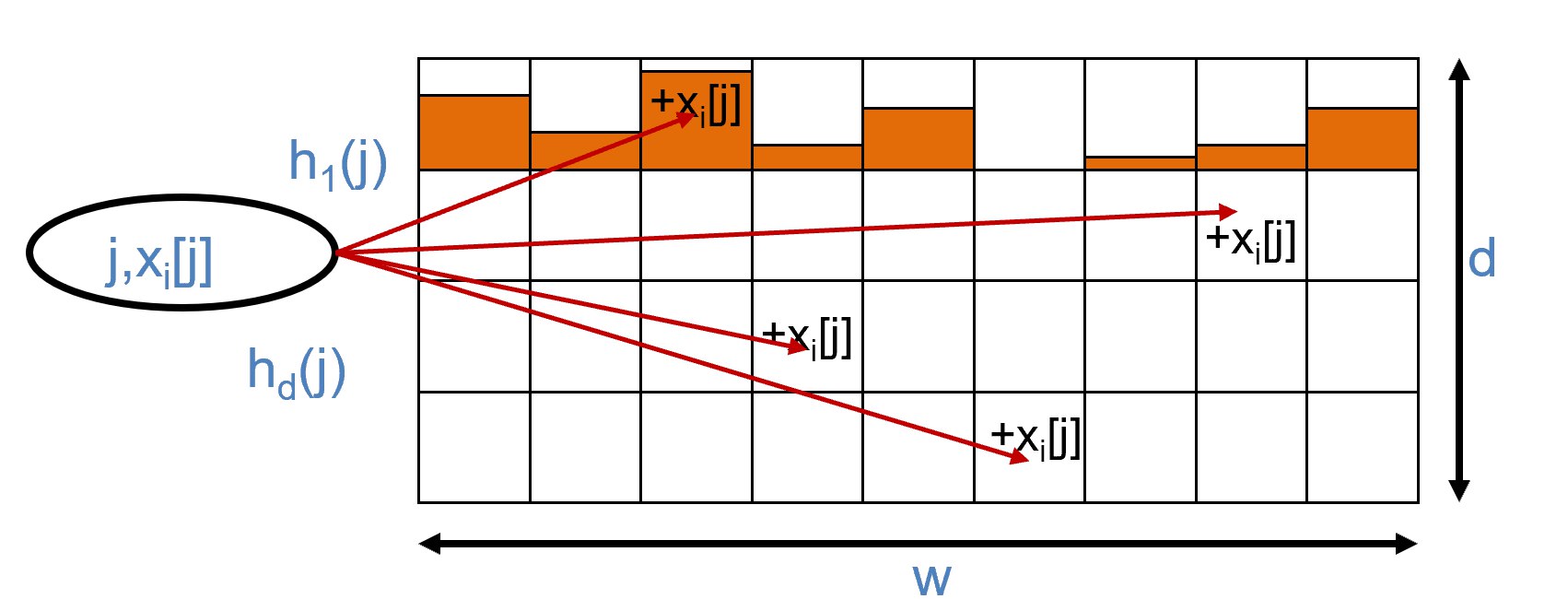
- 应用场景: 点查询、范围查询、分位数、连接大小估计
- 数据结构: 将各节点的输入建模为U维向量 $x_i$,创建大小为 $w \times d$ 的数组摘要,使用 $d$ 个哈希函数将向量映射到 $[1..w]$
- 更新操作: 向量 $x$ 中的每个条目 $j$ 被映射到每一行的一个桶,在第 $k$ 行的位置 $h_k(j)$ 处加上 $x_i[j]$
- 合并操作: 通过逐条目的加总来合并两个草图
- 查询操作: 估计 $x_i[j]$ 的值为 $\min_k \text{sketch}[k, h_k(j)]$
- 性能保证: 任一点查询的误差小于 $\varepsilon |x|_1$,空间开销 $O(\frac{1}{\varepsilon} \log \frac{1}{\delta})$,误差高于阈值的概率低于 $1-\delta$
其他草图类型:
- AMS草图: 自连接、连接操作的近似结果误差小于 $\varepsilon |x|_2 |y|_2$,空间复杂度 $O(\frac{1}{\varepsilon^2} \log \frac{1}{\delta})$
- FM草图: 估算相异元素个数 $(|x|_0)$,误差小于 $\varepsilon |x|_0$,空间复杂度 $O(\frac{1}{\varepsilon^2} \log \frac{1}{\delta})$
- 布隆过滤器(Bloom filters): 对集合进行编码
5. 网络不可靠性问题
理想假设的局限性: 基于树型结构的聚集查询假设可靠网络,无节点故障、不丢失任何消息。但实际中故障可能严重影响计算,靠近根的节点发生故障可能丢失整棵子树,消息丢失可能需要检测并重新发送,节点故障可能需要重建整个树。
多路径路由解决方案:
- 传感网络特性: 基于无线电通信,广播成本与单播相同
- 策略优势: 使用多路径路由可提高可靠性、减少故障影响、减少重复消息需要
MAX查询示例:
- 将网络构造成从根节点等距的节点环
- 监听来自下方环的所有消息,然后发送所接收到的所有值的最大值
- 快速收敛,具有高路径多样性
- 每个节点只发送一次,成本与树相同
6. 排序与重复的非敏感性(ODI)
ODI定义与特性:
对顺序和重复性不敏感(Order and Duplicate Insensitive)的聚集查询需要满足以下条件:
- g函数在有相同项时输出相同结果:$i=j \Rightarrow g(i) = g(j)$
- f函数是结合的和交换的:$f(x,y) = f(y,x)$ 且 $f(x,f(y,z)) = f(f(x,y),z)$
- f函数对相同摘要是幂等的:$f(x,x) = x$
验证: min、max满足ODI要求,但sum不满足ODI要求。
创建ODI摘要的技术: 只有min和max天然符合ODI特性,其他聚集需要利用对重复项不敏感的技术,包括Flajolet-Martin草图(FM)、最小哈希、随机标记、布隆过滤器等。
(1)FM Sketch(Flajolet-Martin草图)
算法原理:
- 目标: 估计输入数据中的相异元素数量(count distinct)
- 哈希函数设计: 使用哈希函数将输入项映射到 $i$,概率为 $2^{-i}$。例如:$\Pr[h(x) = 1] = \frac{1}{2}$, $\Pr[h(x) = 2] = \frac{1}{4}$, $\Pr[h(x)=3] = \frac{1}{8}$。实现上通过均匀哈希函数计算尾随零的数量。
- 数据结构: 维护FM Sketch = 位图数组 $L$,含 $\log U$ 比特位。所有项初始化为0,对于每个传入的值 $x$,设置 $\text{FM}[h(x)] = 1$
估计算法:
- 如果有 $d$ 个不同的值,预期 $d/2$ 映射到FM[1],$d/4$ 映射到FM[2],以此类推
- 设 $R$ = FM中最右侧0的位置,$R$ 作为 $\log(d)$ 的指示器
- 输出估计值:$d = c \cdot 2^R$,其中缩放常数 $c \approx 1.3$
- 提高准确性:对多个副本(不同的哈希函数)取均值,使用 $O(\frac{1}{\varepsilon^2} \log \frac{1}{\delta})$ 个副本可获得至少 $1-\delta$ 置信度的 $(1\pm\varepsilon)$ 准确度估计
ODI属性:
- 可以融合多个具有相同哈希函数 $h()$ 的FM摘要,通过对摘要进行按位或运算
- 计数应用:给每个项目打上站点ID标签,用一元表示法 $(i,1), (i,2), \ldots, (i,c_i)$,在修改后的输入上运行FM,执行ODI协议
(2)随机采样(Random Sampling)
随机标记技巧: 解决如何找到所有集合联合的一个随机样本的问题
- 对于每个项,附加范围在$[0,1]$内的随机标签
- 选择带有K个最小标签,向上级发送
- 合并所有接收到的项,并选择K个最小标签
示例:
节点1: (a, 0.34), (c, 0.77)
节点2: (d, 0.57), (b, 0.92)
合并后选K=1: (a, 0.34)
(3)布隆过滤器(Bloom Filters)
功能与原理:
- 紧凑地编码集合成员关系
- 使用 $k$ 个哈希函数将项映射到位向量 $k$ 次,将相应的 $k$ 个位置设置为1表示元素存在
- 可查询元素,以约 $2n$ 位存储大小为 $n$ 的集合
ODI属性: 布隆过滤器是ODI,多个布隆过滤器可以合并(按位OR,类似FM sketch)
三、Top-K监控
1. 连续分布式模型
(1) 模型定义
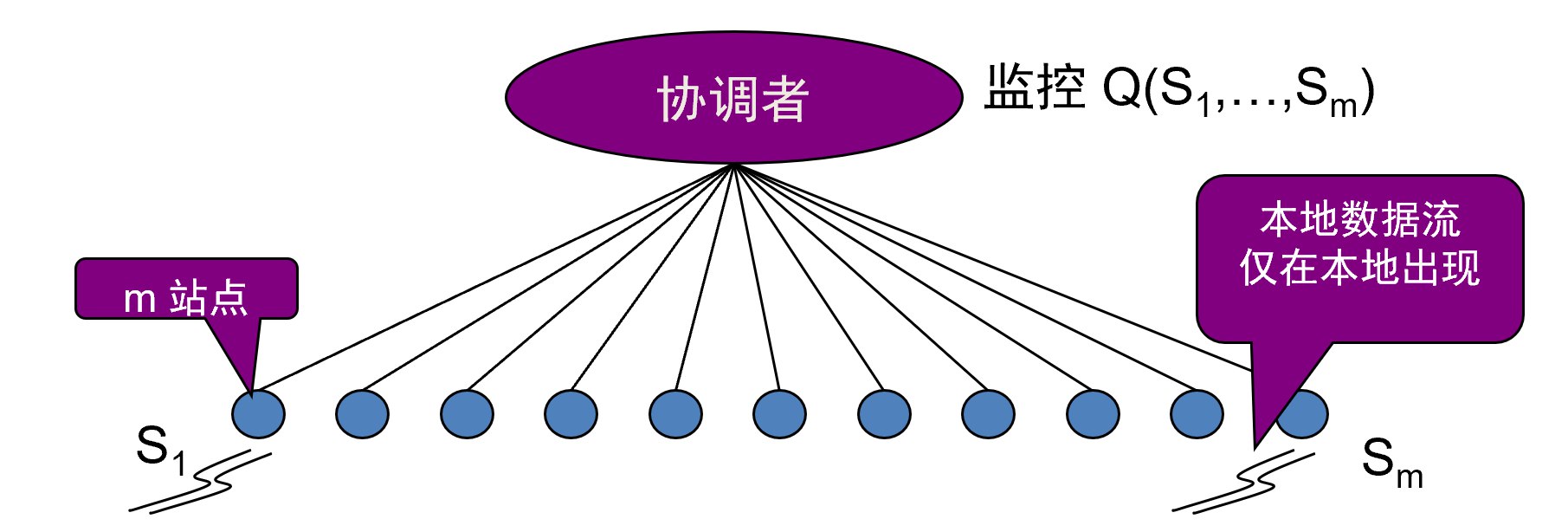
网络结构:
- 协调者(Coordinator)+ m个站点
- 每个站点有本地数据流 $S_1, \ldots, S_m$
- 可能允许站点间通信,但大多数情况并不需要
目标:
- 在协调者处连续跟踪(全局)流上的查询 $Q(S_1, \ldots, S_m)$
应用场景:
- 大规模网络事件监控
- 实时异常/DDoS攻击检测
- 电力网监测
(2) 挑战
数据流特性:
- 本地站点的数据流不断变化
- 新的读数被记录,新的数据到达
- 假设:变化是相对平滑和渐进的
要求:
- 保证协调者处的答案始终正确
- 在某个保证的精度范围内
- 平凡解决方案:持续采集所有数据——通信开销巨大!
(3) 问题特征
监控是连续的:
- 实时跟踪,而非一次性查询/响应
分布式的:
- 每个远程站点只能观察到全局数据流的一部分
通信限制:
- 必须最小化监控负担
流式的:
- 每个站点看到高速的本地数据流
- 可能受到资源(CPU/内存)限制
整体的:
- 挑战在于监控完整的全局数据分布
- 简单的聚合(例如:总流量)更容易处理
2. 定期轮询的问题
(1) 轮询策略
应用场景:
- 有时定期轮询可以应付简单任务
- 例如:SNMP以粗粒度轮询总流量
需要处理:
- 聚集的整体性质
(2) 轮询频率的权衡
过于频繁的轮询:
- 导致高通信量
- 传感器网络中过度消耗电池
不频繁的轮询:
- 观察事件的延迟增加
结论:
- 需要技术来减少通信量
- 同时保证对事件的快速响应
3. 通信开销优化的监控方法
(1) 核心思想
无需精确答案:
- 有准确度保证的近似值就足够了
- 在准确性和通信/处理成本之间权衡
关键洞察:“基于推送"的网络内处理
- 在各站点安装本地过滤器以处理本地流更新
- 提供对本地流行为的边界(在协调者处)
- 仅当过滤器被违反时才向协调者"推送"信息
- 协调者设置/调整本地过滤器以保证准确度
(2) 松弛分配(Slack Allocation)
主要想法:
- 由于允许查询结果是近似的,存在松弛
- 松弛:计算结果与真实值之间的误差容忍度
误差类型:
- 绝对误差型:$|Y - \hat{Y}| \leq \varepsilon$,松弛度为 $\varepsilon$
- 相对误差型:$\hat{Y}/Y \in (1\pm\varepsilon)$,松弛度为 $\varepsilon Y$
分配策略:
- 对于给定的聚集,松弛度可以在各个远程站点之间合理分配
- 存在多种松弛度分配的启发式规则
4. Top-K监控算法
(1) 问题定义
场景设置:
- 每个站点监控 $n$ 个对象
- 各对应一个本地计数器 $V_{i,j}$(站点 $j$ 上对象 $i$ 的值)
- 随着时间推移,各站点上各个对象的值会发生变化
- 全局计数器:$V_i = \sum_j V_{i,j}$
目标:
- 找到top-k对象集合
- 允许相对于真实结果有 $\varepsilon$-近似
正确性规则:
- 若对象 $i \in \text{top-k}$,$l \notin \text{top-k}$
- 则必有:$V_i + \varepsilon \geq V_l$
(2) Babcock-Olston方法
核心技术:
- 介绍了基本的松弛分配启发式规则
- 使用本地偏移参数,使所有本地分布看起来像全局分布
处理流程:
- 在进行全局调整之前
- 通过远程站点与协调者之间的协商来修正本地的松弛违规行为
- 消息延迟不会影响正确性
(3) 调整因子方法
定义调整因子 $\delta_{i,j}$:
- 使得 $V_{i,j} + \delta_{i,j}$ 的top-k与 $V_i$ 的top-k相同
不变量维持:
- 对于元素 $i$,调整因子之和为零:$\sum_j \delta_{i,j} = 0$
- 对于非top-k元素 $l$,top-k元素 $i$:
- $\delta_{l,0} \leq \delta_{i,0} + \varepsilon$
精确示例:
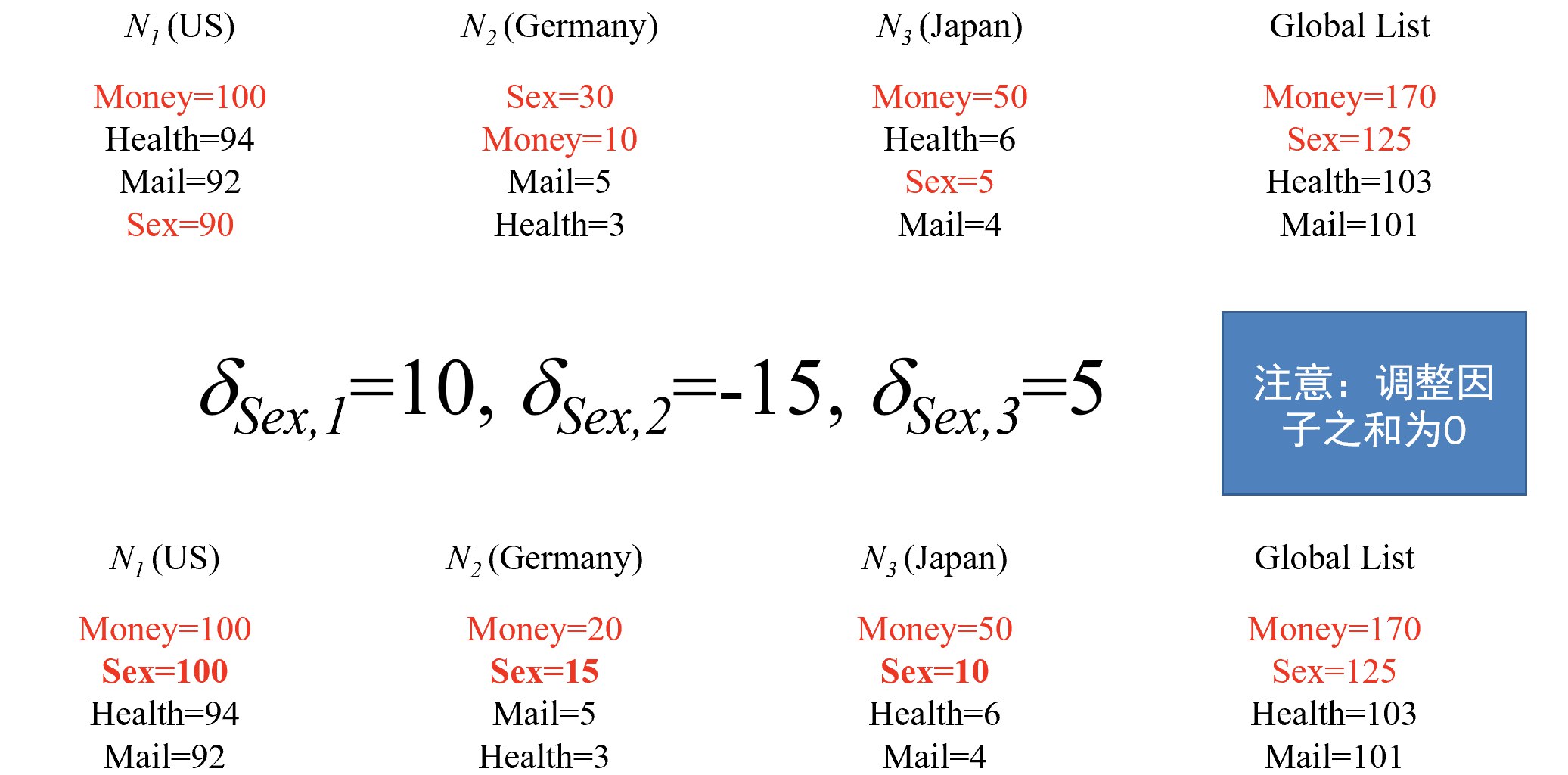
站点1(美国): $Money=100, Sex=100, Health=94, Mail=92$ 站点2(德国): $Money=20, Sex=15, Mail=5, Health=34$ 站点3(日本): $Money=50, Sex=10, Health=6, Mail=4$
全局: $Money=170, Sex=125, Health=103, Mail=101$ 调整因子: $δ_{sex},1=10, δ_{sex},2=-15, δ_{sex},3=5$
允许误差示例(ε=5):

站点3触发: $
(4) 局部条件和解决方式
局部条件:
- 在每个站点 $j$ 检查调整后的top-k计数是否超过非top-k计数
- 条件:$\sum_{i \in \text{top-k}} (V_{i,j} + \delta_{i,j}) \geq \sum_{l \notin \text{top-k}} (V_{l,j} + \delta_{l,j})$
解决机制:
局部解决:
- 站点 $j$ 和协调者仅尝试修复
- 尝试从 $\delta_{i,0}$ 和 $\delta_{l,0}$ “借用"以恢复条件
全局解决:
- 如果局部解决失败,则联系所有站点
- 收集所有受影响的 $V_{i,j}$(top-k加上被违反的计数)
- 为每个计数计算松弛,并重新分配
- 发送新的调整因子 $\delta'_{i,j}$,继续进行
(5) 松弛度划分策略
均匀分配:
- 每个站点分配相等的松弛度
- $\varepsilon_j = \varepsilon/m$($m$ 为站点数)
按比例分配:
- 根据各站点的数据量或重要性按比例分配
- 例如:$\varepsilon_j = \varepsilon \cdot \frac{V_j}{\sum_k V_k}$
(6) 优点和缺点
优点:
- 在近似范围内保证正确性
- 即使存在延迟,也能收敛到正确结果
- 通信量减少了一个数量级(与每次 $V_{i,j}$ 改变 $\varepsilon/m$ 就发送相比)
缺点:
- 重新分配变得复杂:必须检查 $O(km)$ 个条件
- 每个站点需要 $O(n)$ 的空间,协调者需要 $O(mn)$ 的空间
- 消息量大(约 $O(k)$ 消息)
- 全局重新同步代价高:需要向 $k$ 个站点发送 $m$ 条消息
5. 通用经验教训
(1) 核心原则
分解策略:将全局(整体的)聚集分解为"安全"的本地条件,使得本地条件 ⇒ 全局正确性
参数设置:
- 设置本地参数以帮助跟踪
- 使用近似来定义松弛,并在站点之间(以及协调者)分配松弛
局部优化:尽可能避免全局调整,尽量在本地修补问题
(2) 研究展望
现状:分布式流的共同特性使得可以采用通用的技术/原则,而非"点对点"解决方案
关键技术:
- 网络内的查询处理
- 在站点进行本地过滤,权衡近似与处理/网络成本
- 利用网络局部性并避免全局重新同步
第五讲 哈希
一、哈希函数和哈希表
1. 问题起源
应用需求:
许多应用都需要一种动态集合结构,至少要支持INSERT、SEARCH、DELETE字典操作。
典型例子:
- 关于植物的百科全书
- 图书馆馆藏书籍
基本操作:
- INSERT(T, x):插入元素x到表T中
- DELETE(T, x):从表T中删除元素x
- SEARCH(T, k):在表T中查找关键字k
2. 哈希函数
定义: 哈希函数是将关键词映射到非负整数的函数:$h(\text{key}) = \text{value} \in \mathbb{Z}^+$
核心特性:
(1) 压缩存储
- 哈希值的空间开销远小于输入关键词的空间开销
- 例如:爬虫将爬取的网页URL哈希成一个整数,存储空间显著降低,实现数据压缩的效果
(2) 无冲突(理想状态)
- 不同的关键词会得到不同的哈希值
- 即使关键词差异很小,也可能生成完全不同的哈希值
- 同一关键词由相同的哈希函数哈希之后,哈希值不变
(3) 不可逆
- 若哈希函数未知,仅凭哈希值无法轻易猜到此哈希值对应的关键词
- 唯一找到关键词的方法是蛮力法(Brute Force)
3. 哈希表结构
基本原理:
哈希表通过哈希函数将关键字映射到表中的位置,实现快速的数据访问。
性能影响因素:
- 哈希函数选取:应尽量减少冲突,并将键和条目均匀分布在整个表中
- 冲突解决策略:将键/条目存储在不同的位置,或者在同一位置链式存储多个键/条目
- 哈希表的大小:过大的表会导致内存浪费;过小的表会增加冲突
典型方法对比
| 操作 | 未排序数组 | 排序数组 | 链表 | 二叉搜索树 | 哈希表 |
|---|---|---|---|---|---|
| 插入 | O(1) | O(n) | O(1)或O(n) | O(log n) | O(1) |
| 搜索 | O(n) | O(log n) | O(n) | O(log n) | O(1) |
| 删除 | O(n) | O(n) | O(n) | O(log n) | O(1) |
注意: 哈希表的O(1)性能并不是绝对保证的,依赖于哈希函数质量和冲突解决策略。
4. 开放寻址法
基本思想:
在哈希表之外,没有存储空间被利用。插入操作会系统性地搜索表,一直到找到空槽。
散列函数特点:
- 散列函数依赖于关键字和搜索次数:$h: U \times {0, 1, \ldots, m-1} \to {0, 1, \ldots, m-1}$
- 搜索序列 $\langle h(k,0), h(k,1), \ldots, h(k,m-1) \rangle$ 是 ${0, 1, \ldots, m-1}$ 的一个排列
限制:
- 表可能会充满
- 删除操作是困难的(但不是不可能)
(1) 线性探查
公式:
$$h(k, i) = (h'(k) + i) \bmod m$$其中 $h'(k)$ 是普通的散列函数。
问题:一次群集(Primary Clustering)
- 长期运行的占有的槽建立后,增加了平均搜索时间
- 占有的槽运行时间较长会变得更长
- 原因:当一个空槽前有i个满的槽时,该空槽下一个将被占用的概率是 $(i+1)/m$。连续被占用的槽就会变得越来越长,因而平均查找时间也会越来越大。
(2) 二次探查
公式:
$$h(k, i) = (h'(k) + c_1 i + c_2 i^2) \bmod m$$其中 $c_1$ 和 $c_2$ 都是正的辅助常数。
改进与问题:
- 避免了一次群集
- 但无法避免二次群集(Secondary Clustering)
- 原因:$h(k_1, 0) = h(k_2, 0)$ 蕴含着 $h(k_1, i) = h(k_2, i)$
(3) 双重散列
公式:
$$h(k, i) = (h_1(k) + i \cdot h_2(k)) \bmod m$$其中 $h_1(k)$ 和 $h_2(k)$ 是两个普通的散列函数。
设计要求:
- $h_2(k)$ 必须要与表的大小 $m$ 互素
- 一种方式是设置 $m$ 为2的幂次方,并且设计 $h_2(k)$ 仅产生奇数
案例:
设散列表大小为13,$h_1(k) = k \bmod 13$,$h_2(k) = 1 + (k \bmod 11)$
对于关键字14:
- $14 \equiv 1 \pmod{13}$,$14 \equiv 3 \pmod{11}$
- 探查序列:槽1 → 槽5 → 槽9($h_1(14) = 1,h_k(14) = 1+3 = 4$,即冲突后每次向后跳四格)
- 在探查了槽1和槽5并发现它们被占用后,关键字14被放到了槽9当中
二、布隆过滤器
1. 布隆过滤器简介
定义:
布隆过滤器(Bloom Filter,1970年提出)是一种空间高效的概率数据结构,用于测试某个元素是否属于一个集合。
核心特点:
- 可能误报:查询返回的元素可能在集合中,也可能不在集合中(假阳性)
- 不会漏报:查询不会返回肯定不在集合中的项(无假阴性)
典型应用场景:
- 垃圾邮件地址过滤:可以高效地过滤垃圾邮件地址
- 拼写检查:能够以高精度和高速度纠正最常见的拼写错误
- 重复检查:可帮助网络爬虫确定某个URL是否已经被抓取过
(1)数据结构定义
基本组成:
设 $S$ 是一个包含 $n$ 个元素的集合。我们有 $k$ 个哈希函数,记为 $h_1, h_2, \ldots, h_k$,其值域为 ${0, 1, \ldots, m-1}$。
初始化:
- 长度为 $m$ 的位数组初始时均被设置为0
- 每个元素通过 $k$ 个哈希函数映射到位数组的 $k$ 个位置
示例:
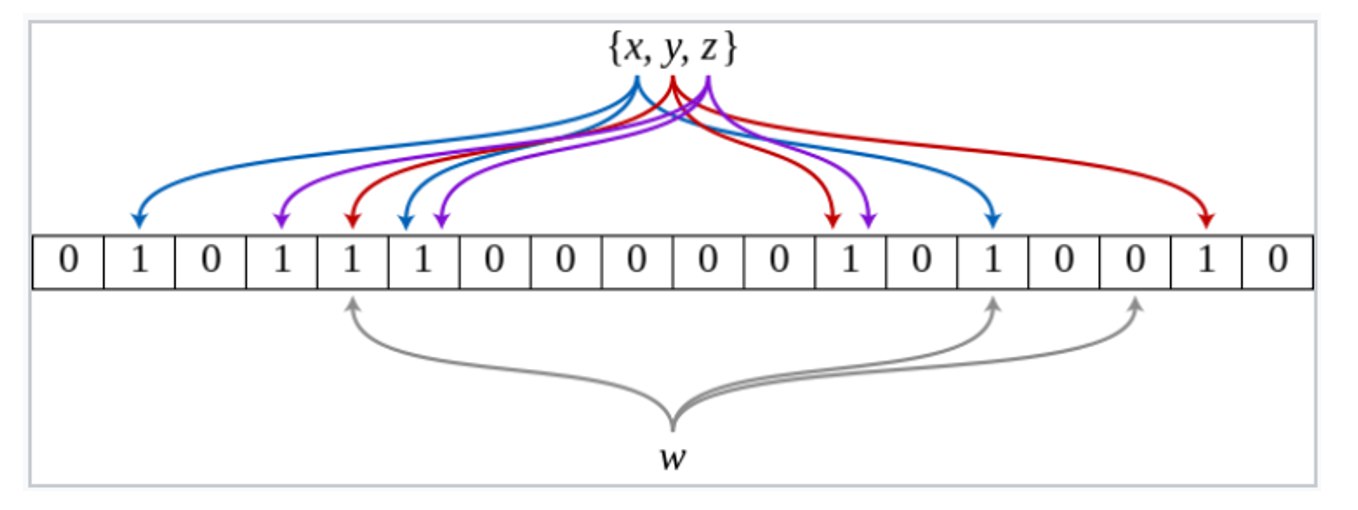
集合 ${x, y, z}$ 的布隆过滤器($m=18$,$k=3$):
彩色箭头显示每个元素在位数组中被映射的位置。
(2)数据维护和查询
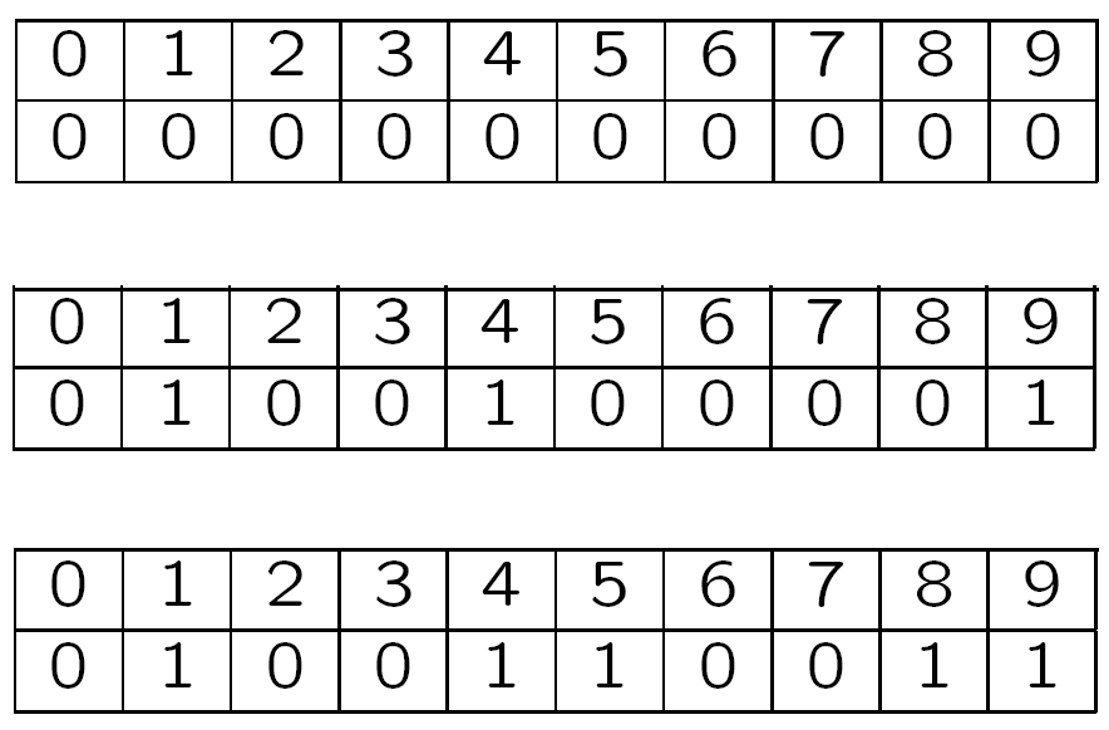
插入操作:
设有大小为 $m=10$ 的布隆过滤器,使用 $k=3$ 个哈希函数。
初始状态:
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
插入 $x_0$,$H(x_0) = {1, 4, 9}$:
[0, 1, 0, 0, 1, 0, 0, 0, 0, 1]
插入 $x_1$,$H(x_1) = {4, 5, 8}$:
[0, 1, 0, 0, 1, 1, 0, 0, 1, 1]
查询操作:
- 查询 $x_1$:$H(x_1) = {4, 5, 8}$,所有位都为1 → 是(正确)
- 查询 $x_2$:假设 $H(x_2) = {0, 4, 8}$,位置0为0 → 否(正确)
- 查询 $x_3$:假设 $H(x_3) = {1, 5, 8}$,所有位都为1 → 是(假阳性)
(3)假阳率分析
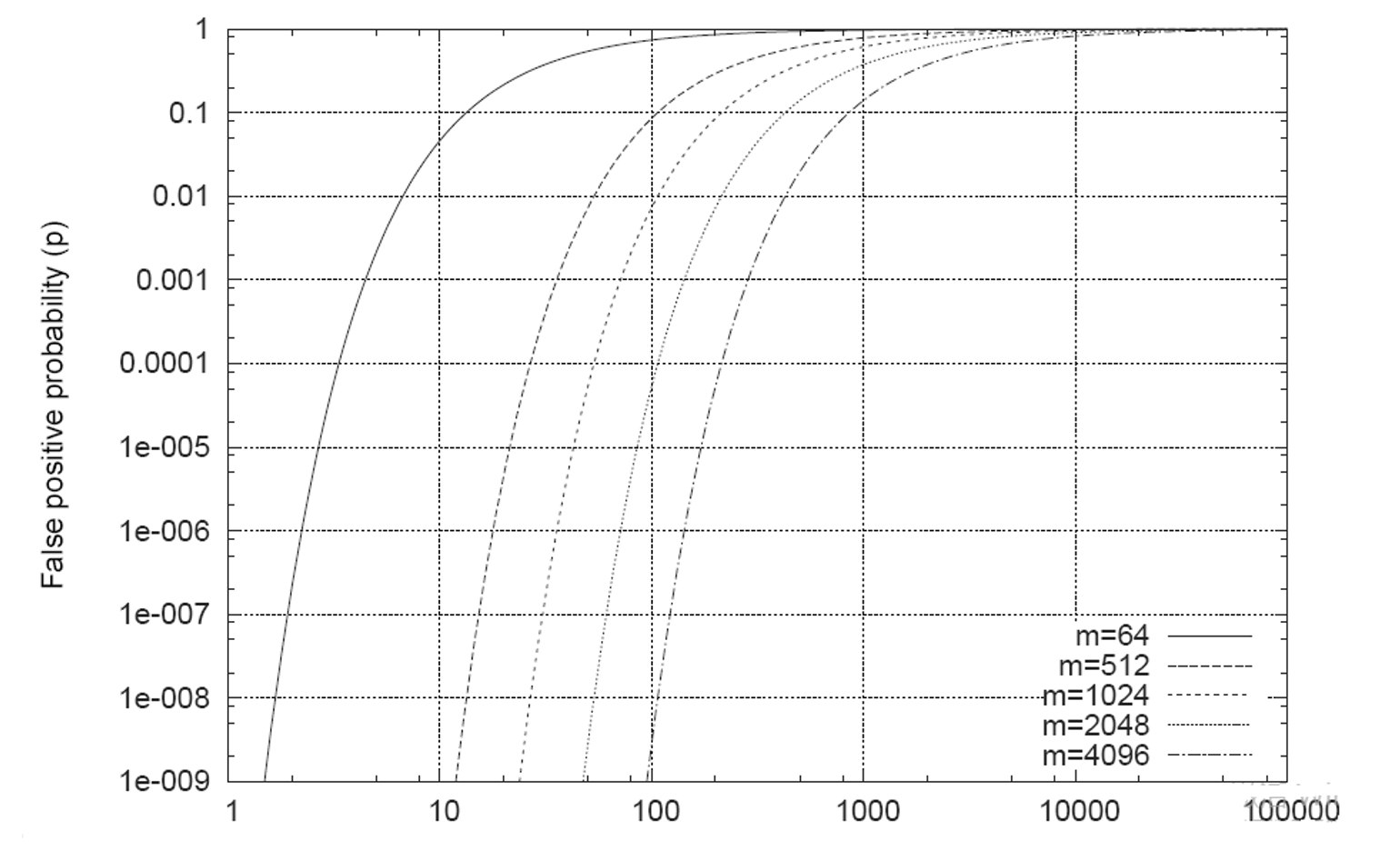
概率推导:
单个位为0的概率
- 插入一个元素时,某位未被哈希函数设置为1的概率:$1 - 1/m$
- 使用 $k$ 个哈希函数,该位仍为0的概率:$(1 - 1/m)^k$
- 插入 $n$ 个元素后,该位仍为0的概率:$(1 - 1/m)^{kn}$
假阳率公式
指定位为1的概率:
$$p = 1 - \left(1 - \frac{1}{m}\right)^{kn}$$假阳率(所有 $k$ 个位置都为1的概率):
$$f = \left[1 - \left(1 - \frac{1}{m}\right)^{kn}\right]^k \approx (1 - e^{-kn/m})^k$$影响因素:
- $n$ 增加,误报率增加
- $m$ 增加,误报率降低
问题: 给定 $m$ 和 $n$,如何选择 $k$ 来最小化假阳率?
优化过程:
令 $p = e^{-kn/m}$,则:
$$f \approx (1 - p)^k = e^{k\ln(1-p)}$$最小化 $g = k\ln(1-p)$:
由于 $\ln p = -kn/m$,我们有:
$$g = k\ln(1-p) = -\frac{m}{n}\ln(p)\ln(1-p)$$最优解:
当 $p = 1/2$ 时,$g$ 被最小化,即:
$$k_{\text{opt}} = \frac{m}{n}\ln 2 \approx 0.693 \cdot \frac{m}{n}$$此时假阳率为:
$$f_{\text{min}} = (0.5)^k \approx 0.6185^{m/n}$$2. 支持删除 - 计数布隆过滤器
标准布隆过滤器的限制:
不支持删除操作,因为删除一个元素可能影响其他元素。
计数布隆过滤器(Counting Bloom Filter):
- 不再使用位来标记元素,而是使用一个计数器,删除一个元素时即将对应位置的计数减一
- 当计数为零时代表元素不存在,该方法虽然支持了删除,但是空间随着计数器大小成倍增加。
3. 布谷鸟过滤器
布谷鸟哈希(Cuckoo Hashing):
2001年由Rasmus Pagh和Flemming Friche Rodler提出,利用较少计算换取了较大空间。
命名来源:
布谷鸟产蛋后不自己筑巢,而是将蛋放入其他鸟的巢中,移走原来的一个蛋。类似地,布谷鸟哈希在插入时可能"挤走"已有元素。
(1) 元素插入
使用两个哈希函数:
- 情况1:两个位置都空着 → 随机挑选一个
- 情况2:其中一个位置空着 → 占用这个空着的位置
- 情况3:两个位置都被占用 → 挑选一个位置占用,原先占用该位置的对象需要重新找位置,如此往复
(2) 总体数据结构
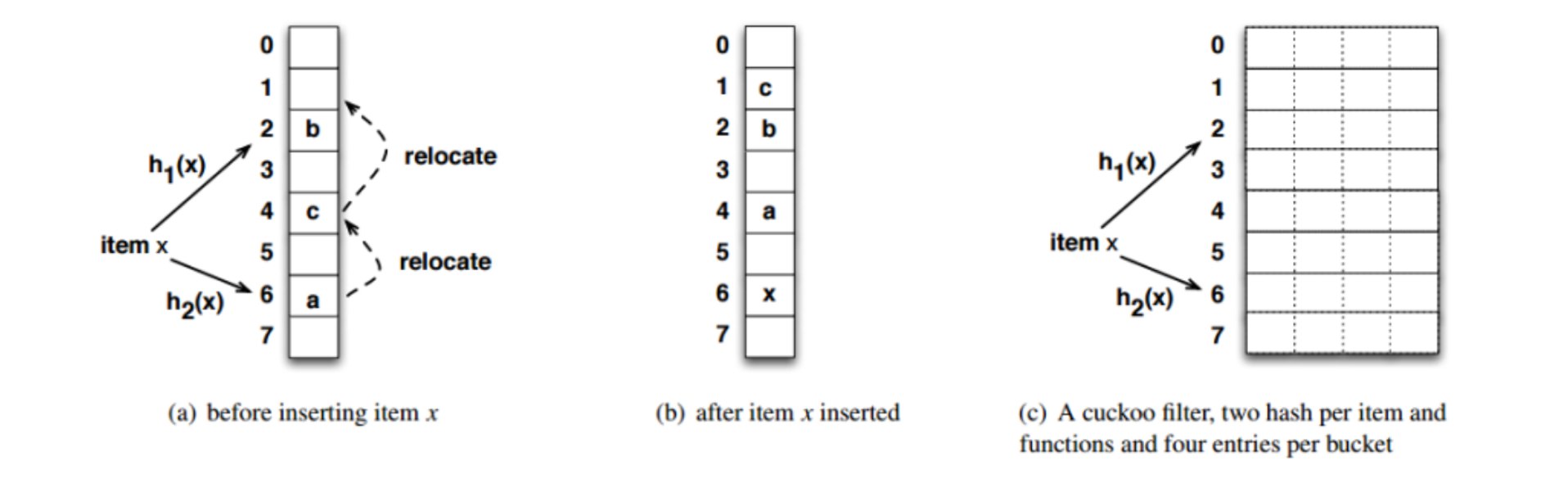
改进:
为了提高空间利用率,降低碰撞概率,布谷鸟过滤器在布谷鸟哈希上做了改进:
- 从一维结构变成二维结构(每个桶存储 $n$ 个元素)
- 每个位置中只存储几个bit的指纹,而非完整的元素
- 只有当一个桶中的所有slot都被填满时,才会使用替换策略
示例: 每个桶中存储4个slot,使用二维数组表示。
三、最小哈希和LSH
1. 距离度量
目标:
在高维空间中找到近邻。首先需要定义什么是"距离”。
Jaccard相似度:
两个集合的Jaccard相似度定义为它们交集的大小除以并集的大小:
$$\text{sim}(A, B) = \frac{|A \cap B|}{|A \cup B|}$$Jaccard距离:
$$d(A, B) = 1 - \frac{|A \cap B|}{|A \cup B|}$$案例:
对于两个集合,若:
- 交集大小 = 3
- 并集大小 = 8
则:
- Jaccard相似度 = 3/8
- Jaccard距离 = 5/8
2. 场景任务:找寻相似文档
目标:
给定大量(百万或十亿份)文档,找出相似度极高的文档对。
应用:
- 镜像网站,或是近似的镜像网站
- 许多新闻站点上的类似新闻文章
问题:
- 一个文档中的许多小部分可能在另一个文档中乱序出现
- 文档数据库规模宏大,无法一一比对
- 文档太大或数量太多,无法全部装入主内存
复杂度分析:
对于 $N = 1,000,000$ 的文档库:
- 需要比较的文档对数:$N(N-1)/2 \approx 5 \times 10^{11}$
- 按每天 $10^5$ 秒,每秒 $10^6$ 次比较,需要5天
- 若 $N = 10,000,000$,所需时间将超过一年
3. 三个关键步骤及详细实现
整体流程:
- Shingling(分片):将文档转换为集合
- Min-Hashing(最小哈希):将大集合转换为短签名,且保留相似性
- Locality-Sensitive Hashing(局部敏感哈希):专注于潜在相似的文档的签名对
步骤1:Shingling(分片)
目标: 将文档转换为集合
不佳的方法:
- 文档 = 文档中出现的单词集合
- 文档 = “重要"单词集合
- 问题:忽略了单词的顺序!
k-shingle(或k-gram)定义:
在文档中的由 $k$ 个标记组成的序列。标记可以是字符、单词或其他东西。
示例:
设$k = 2$,字符串 $D = \text{abcab}$,转换成一组2-shingle:
$$S(D) = {\text{ab}, \text{bc}, \text{ca}}$$选项: 将shingle视为包(多重集),则ab计数两次:
$$S(D) = {\text{ab}, \text{bc}, \text{ca}, \text{ab}}$$分片压缩:
为了压缩长的shingle,可以将它们哈希到(比如说)4字节,并使用这些shingle的哈希值来表示文档。
案例:
$k = 2$,字符串 $D = \text{abcab}$:
- $S(D) = {\text{ab}, \text{bc}, \text{ca}}$
- 对这些shingle进行哈希:$h(D) = {1, 5, 7}$
相似度度量:
考虑文档 $D$,其k-shingle集合 $C = S(D)$。等价地,每个文档是在k-shingle空间中的一个0/1向量。
文档相似度 = k-shingle集合的Jaccard相似度:
$$\text{sim}(D_1, D_2) = \frac{|C_1 \cap C_2|}{|C_1 \cup C_2|}$$集合编码成位向量:
使用0/1(位,布尔)向量对集合进行编码,每个维度对应于全集中的一个元素。
-
交集 = 按位与(AND)
-
并集 = 按位或(OR)
示例: $C_1 = 10111$,$C_2 = 10011$
- 交集大小 = 3
- 并集大小 = 4
- Jaccard相似度 = 3/4
- Jaccard距离 = 1/4
矩阵表示:
- 行 = 元素(shingle)
- 列 = 集合(文档)
- 如果元素 $e$ 属于集合 $s$,则第 $e$ 行和第 $s$ 列的位置被置为1
特点: 通常情况下,矩阵是稀疏的!
步骤2:最小哈希(Min-Hashing)
目标:
找到一个哈希函数 $h(\cdot)$,使得:
- 如果 $\text{sim}(C_1, C_2)$ 很高,那么 $P[h(C_1) = h(C_2)]$ 也高
- 如果 $\text{sim}(C_1, C_2)$ 较低,那么 $P[h(C_1) \neq h(C_2)]$ 也高
核心思想:
想象布尔矩阵的行在随机排列 $\pi$ 下进行了重排。
哈希函数定义:
$$h_\pi(C) = \min_\pi \pi(C)$$即在排列 $\pi$ 下,列 $C$ 中值为1的第一个行的索引。
签名生成:
使用多个(例如100个)独立的哈希函数(即排列)来创建一列的签名。
最小哈希的核心性质:
给定随机排列 $\pi$,则:
$$P(h_\pi(C_1) = h_\pi(C_2)) = \text{sim}(C_1, C_2)$$证明思路:
- 令 $X$ 是一个文档(shingles的集合),$y \in X$ 是一个shingle,则: $$P[\pi(y) = \min(\pi(X))] = \frac{1}{|X|}$$
- 若 $y$ 满足 $\pi(y) = \min(\pi(C_1 \cup C_2))$,则:
- $\pi(y) = \min(\pi(C_1))$ 或 $\pi(y) = \min(\pi(C_2))$
- 两个事件同时为真的前提条件是:$y \in C_1 \cap C_2$
- 因此: $$P(\min(\pi(C_1)) = \min(\pi(C_2))) = \frac{|C_1 \cap C_2|}{|C_1 \cup C_2|} = \text{sim}(C_1, C_2)$$
签名的相似度:
由于 $P(h_\pi(C_1) = h_\pi(C_2)) = \text{sim}(C_1, C_2)$,推广到多个哈希函数:
列的相似度 = 其签名的预期相似度
最小哈希签名生成过程:
- 选择 $K = 100$ 个随机的行排列
- 将 $\text{sig}(C)$ 视为一个列向量
- $\text{sig}(C)[i] = \min(\pi_i(C))$,即根据第 $i$ 个排列,列 $C$ 中第一个值为1的行的索引
压缩效果:
文档 $C$ 的签名很小,大约100字节!已经将长的位向量"压缩"成了短的签名。
步骤3:LSH 局部敏感哈希
目标:
找到Jaccard相似度 $\geq s$(例如 $s = 0.8$)的文档。
核心思想:
使用一个函数 $f(x, y)$,该函数用于判断 $x$ 和 $y$ 是否为候选对,即相似度需要被评估的元素对。
LSH策略:
- 将签名矩阵 $M$ 的列哈希到多个桶中
- 每一对哈希到同一个桶中的文档构成一个候选对
签名分组:
- 将签名矩阵 $M$ 划分为 $b$ 组(bands),每组包含 $r$ 行
- 对于每一组,将该组中每一列的部分哈希到一个具有 $k$ 个桶的哈希表中
- 候选列对是那些在至少一个组中哈希到同一个桶中的列对
调整: 调整 $b$ 和 $r$ 以捕获大多数相似对,但尽量减少非相似对。
哈希计数优化:
- 若签名相同,必然映射到同一个桶中
- 若签名不同,有可能(小概率)映射到同一个桶中,大概率映射到不同的桶中
案例分析1:高相似度文档
- 设定: $b = 20$,$r = 5$,目标是找到相似度 $\geq s = 0.8$ 的文档对。
- 假设: $\text{sim}(C_1, C_2) = 0.8$
- 分析
- $C_1$ 和 $C_2$ 在某一组中相同的概率:$(0.8)^5 = 0.328$
- $C_1$ 和 $C_2$ 在所有20个组中都不相似的概率:$(1 - 0.328)^{20} = 0.00035$
- 结论
- 约有1/3000的80%相似列对是假阴性(被错过)
- 将找到约99.965%的真正相似文档对
案例分析2:低相似度文档
-
目标:令 b=20,r=5,找到相似度 ≥ s=0.8 的文档对。
-
假设: $\text{sim}(C_1, C_2) = 0.3$
-
分析
- $C_1$ 和 $C_2$ 在某一特定组中相同的概率:$(0.3)^5 = 0.00243$
- $C_1$ 和 $C_2$ 在至少一个组中相同的概率:$1 - (1 - 0.00243)^{20} = 0.0474$
-
结论
- 约4.74%的概率,相似度为0.3的文档对最终成为候选对
- 它们是假阳性,需要检查但最终会发现相似度低于阈值
LSH体现的权衡
最小哈希的数量(矩阵 $M$ 的行数)、组的数量 $b$、每组的行数 $r$,需要平衡假阳性和假阴性的数量。
S曲线分析
至少有1个组相同的概率:
$$P = 1 - (1 - t^r)^b$$其中 $t$ 是列的相似度。
极端情况
- 假设只有一个带($b=1$),且只有一行($r=1$):$P = t$(线性关系)
4. 方法比较与总结
三种方法对比:
方法1:直接比较
- 基于100万个文档,形成约 $5 \times 10^{11}$ 个文档对
- 对每个文档对执行相似度计算
- 优点:最精准,能够精确获得所有高相似度的文档对
- 缺点:开销非常大,对于大的文档库来说计算上不现实
方法2:Min-Hashing
- 生成签名矩阵(100万列)
- 针对所有列进行两两计算(约 $5 \times 10^{11}$ 次)
- 优点:计算效率大幅改进,能够处理大规模的文档库
- 缺点:在准确度上做了妥协,有一些高相似度文档对可能未被发现
方法3:LSH
- 基于签名矩阵使用LSH技术
- 一次遍历与各组相关联的哈希桶
- 优点:进一步提升执行效率,能够应对更大的数据集合
- 缺点:候选集合中可能出现低相似度文档对(假阳性),同时可能错失部分高相似度文档对(假阴性)
实际操作建议:
- 调整 $M$、$b$ 和 $r$,以几乎找到所有具有相似签名的对,同时消除大多数没有相似签名的对
- 在主内存中检查候选对是否确实具有相似的签名
- 可选:在数据的另一次遍历中,检查剩余的候选对是否确实代表相似的文档
5. 衍生问题
问题:
考虑一个在线商城,不断地在卖商品,有些商品比较畅销,卖了多件,有些商品卖的比较少。请问:仅卖一件的商品数量在所有已售出商品中的占比是多少?
示例:
假设商品售卖记录是:a b a a c a d b e c b
易知:
- a、b、c均被售出多次
- d、e仅被售出一次
- 仅卖一件的商品占比为40%(2/5)
相关性:
这个问题可以使用Min-Hashing相关技术来高效估计,无需精确统计所有商品。
第六讲 线性规划与整数规划
- 线性规划问题研究在资源约束条件下的最大化或最小化目标问题,表示方式有标准型和松弛型,单纯形算法来求解线性规划问题
- 整数规划比线性规划有更多约束条件
- 分支界定法是解决整数规划问题的有效方法,但是当变量数量多的时候效率会下降
- 切平面法是解决整数规划问题的有效方法
一、线性规划:单纯形算法
1. 线性函数与线性规划
线性函数的定义:
给定一组实数 $a_1, a_2, ..., a_n$ 和一组变量 $x_1, x_2, ..., x_n$,定义在这些变量上的线性函数为:
$$f(x_1, x_2, ..., x_n) = a_1x_1 + a_2x_2 + ... + a_nx_n$$线性约束的定义:
如果 $b$ 是一个实数,而 $f$ 是一个线性函数,则:
- $f(x_1, x_2, ..., x_n) = b$ 是线性等式
- $f(x_1, x_2, ..., x_n) \geq b$ 和 $f(x_1, x_2, ..., x_n) \leq b$ 是线性不等式
线性约束表示线性等式或者线性不等式。
线性规划问题的定义:
一个线性规划问题是指:一个线性函数最小化或最大化的问题,该线性函数服从一组有限个线性约束。
可以分为:
- 最小化线性规划 vs. 最大化线性规划
线性规划的几何意义:
- 可行解:满足所有约束条件的 $x_1, x_2$ 的取值称为一个可行解
- 可行区域:所有可行解构成的区域
示例:
$$ \begin{align} \text{最大化} \quad & x_1 + x_2 \\ \text{满足约束条件:} \quad & 4x_1 - x_2 \leq 8 \\ & 2x_1 + x_2 \leq 10 \\ & 5x_1 - 2x_2 \geq -2 \\ & x_1, x_2 \geq 0 \end{align} $$在图示中,可行区域为一个多边形区域,最优解 $x_1 + x_2 = 8$ 出现在可行域的顶点处。
重要性质: 线性规划的最优解通常出现在可行域的顶点处。
2. 线性规划转标准型
标准型的定义:
已知 $n$ 个实数 $c_1, c_2, ..., c_n$; $m$ 个实数 $b_1, b_2, ..., b_m$; 以及 $mn$ 个实数 $a_{ij}$, 其中 $i = 1,2,...,m$;$j = 1,2,...,n$。需要找到 $n$ 个实数 $x_1, x_2,...,x_n$。
一般形式:
$$ \begin{align} \text{最大化} \quad & c_1x_1 + c_2x_2 + ... + c_nx_n \quad \text{(目标函数)} \\ \text{满足约束条件:} \quad & a_{i1}x_1 + a_{i2}x_2 + ... + a_{in}x_n \leq b_i \quad (i = 1,2,...,m) \quad \text{(约束)} \\ & x_j \geq 0 \quad (j = 1,2,..., n) \quad \text{(非负约束)} \end{align} $$矩阵表示形式:
构造:
- $m \times n$ 矩阵 $A = (a_{ij})$
- 一个 $m$ 维向量 $b = (b_i)$
- 一个 $n$ 维向量 $c = (c_i)$
- 一个 $n$ 维向量 $x = (x_i)$
标准型可表示为:
$$ \begin{align} \text{最大化} \quad & c^Tx \quad \text{(目标函数)} \\ \text{满足约束条件:} \quad & Ax \leq b \quad \text{(约束)} \\ & x \geq 0 \quad \text{(非负约束)} \end{align} $$可用元组 (A, b, c) 表达一个标准的线性规划问题。
标准型的特点:
- 目标函数是最大化
- 所有约束都是不等式(小于等于号)
- 所有变量都有非负约束
转换为标准型的技巧:
一个线性规划问题可能不是标准型,可能的原因及解决方法包括:
(1)目标函数是最小化而非最大化
解决方法: 将目标函数中的系数取负数
示例:
$$ \begin{aligned} \text{最小化} \quad & -2x_1 + 3x_2 \\ \text{满足约束:} \quad & x_1 + x_2 = 7 \\ & x_1 - 2x_2 \leq 4 \\ & x_1 \geq 0 \end{aligned} \quad \rightarrow \quad \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2 \\ \text{满足约束:} \quad & x_1 + x_2 = 7 \\ & x_1 - 2x_2 \leq 4 \\ & x_1 \geq 0 \end{aligned} $$(2)变量不具有非负约束
解决方法: 将该变量 $x_j$ 每次出现的地方都改为 $x_j' - x_j''$,且 $x_j'$ 和 $x_j''$ 均 $\geq 0$
示例:
$$ \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2 \\ \text{满足约束:} \quad & x_1 + x_2 = 7 \\ & x_1 - 2x_2 \leq 4 \\ & x_1 \geq 0 \end{aligned} \quad \rightarrow \quad \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2' + 3x_2'' \\ \text{满足约束:} \quad & x_1 + x_2' - x_2'' = 7 \\ & x_1 - 2x_2' + 2x_2'' \leq 4 \\ & x_1, x_2', x_2'' \geq 0 \end{aligned} $$(3)可能有等式约束
解决方法: 转化成一对不等式
示例:
$$ \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2' + 3x_2'' \\ \text{满足约束:} \quad & x_1 + x_2' - x_2'' = 7 \\ & x_1 - 2x_2' + 2x_2'' \leq 4 \\ & x_1, x_2', x_2'' \geq 0 \end{aligned} \quad \rightarrow \quad \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2' + 3x_2'' \\ \text{满足约束:} \quad & x_1 + x_2' - x_2'' \leq 7 \\ & x_1 + x_2' - x_2'' \geq 7 \\ & x_1 - 2x_2' + 2x_2'' \leq 4 \\ & x_1, x_2', x_2'' \geq 0 \end{aligned} $$(4)可能有不等式约束,但不是小于等于号,而是大于等于号
解决方法: 更改约束的符号(两边同时乘以 $-1$)
示例:
$$ \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2' + 3x_2'' \\ \text{满足约束:} \quad & x_1 + x_2' - x_2'' \leq 7 \\ & x_1 + x_2' - x_2'' \geq 7 \\ & x_1 - 2x_2' + 2x_2'' \leq 4 \\ & x_1, x_2', x_2'' \geq 0 \end{aligned} \quad \rightarrow \quad \begin{aligned} \text{最大化} \quad & 2x_1 - 3x_2' + 3x_2'' \\ \text{满足约束:} \quad & x_1 + x_2' - x_2'' \leq 7 \\ & -x_1 - x_2' + x_2'' \leq -7 \\ & x_1 - 2x_2' + 2x_2'' \leq 4 \\ & x_1, x_2', x_2'' \geq 0 \end{aligned} $$3. 线性规划转松弛型
松弛型的定义:
松弛型(Slack Form):约束都是等式(除了要求变量非负的约束)
标准型 vs 松弛型:
- 标准型:所有的约束都是不等式
- 松弛型:约束都是等式(除了要求变量非负的约束)
引入松弛变量:
通过引入新变量,将不等式改变成等式:
$$\sum_{j=1}^{n} a_{ij}x_j \leq b_i \quad \rightarrow \quad s = b_i - \sum_{j=1}^{n} a_{ij}x_j, \quad s \geq 0$$称 $s$ 为松弛变量,因为它度量了以上不等式左右两边的松弛或差别。
更简洁的表示:
去除关于"最大化”、“满足约束"这些词,直接写成等式形式。
示例:
原标准型:
$$ \begin{align} \text{最大化} \quad & 2x_1 - 3x_2 + 3x_3 \\ \text{满足约束条件:} \quad & x_1 + x_2 - x_3 \leq 7 \\ & -x_1 - x_2 + x_3 \leq -7 \\ & x_1 - 2x_2 + 2x_3 \leq 4 \\ & x_1, x_2, x_3 \geq 0 \end{align} $$转换为松弛型(引入松弛变量 $x_4, x_5, x_6$):
$$ \begin{align} z &= 2x_1 - 3x_2 + 3x_3 \\ x_4 &= 7 - x_1 - x_2 + x_3 \\ x_5 &= -7 + x_1 + x_2 - x_3 \\ x_6 &= 4 - x_1 + 2x_2 - 2x_3 \end{align} $$重要概念:
- 等式左边:基本变量(在等式左边的变量)
- 等式右边:非基本变量(在等式右边的变量)
松弛型的元组表示:
可用元组 (N, B, A, b, c, v) 表示松弛型。
示例:
$$ \begin{align} z &= 28 - \frac{x_3}{6} - \frac{x_5}{6} - \frac{2x_6}{3} \\ x_1 &= 8 + \frac{x_3}{6} + \frac{x_5}{6} - \frac{x_6}{3} \\ x_2 &= 4 - \frac{8x_3}{3} - \frac{2x_5}{3} + \frac{x_6}{3} \\ x_4 &= 18 - \frac{x_3}{2} + \frac{x_5}{2} \end{align} $$元组表示:
- $B = \{1, 2, 4\}$(基本变量集合)
- $N = \{3, 5, 6\}$(非基本变量集合)
- $c = (c_3, c_5, c_6)^T = (-1/6, -1/6, -2/3)^T$
- $v = 28$
矩阵 $A$:
$$ A = \begin{pmatrix} a_{13} & a_{15} & a_{16} \\ a_{23} & a_{25} & a_{26} \\ a_{43} & a_{45} & a_{46} \end{pmatrix} = \begin{pmatrix} 1/6 & 1/6 & -1/3 \\ -8/3 & -2/3 & 1/3 \\ -1/2 & 1/2 & 0 \end{pmatrix} $$向量 $b$:
$$ b = \begin{pmatrix} b_1 \\ b_2 \\ b_4 \end{pmatrix} = \begin{pmatrix} 8 \\ 4 \\ 18 \end{pmatrix} $$4. 单纯形算法
算法核心思想:
单纯形算法的本质是从可行域的一个顶点出发,沿着目标函数值改进的方向移动到相邻顶点,直到找到最优解。
基本解的概念:
松弛型等式系统拥有无限个解。我们集中于基本解:
- 把等式右边所有(非基本)变量设为 $0$
- 再计算等式左边(基本)变量的值
- 再计算目标值
每次迭代的目标: 重新整理线性规划,使得基本解有一个更大的目标值。
算法详细步骤(以最大化问题为例):
初始问题:
$$ \begin{align} \text{最大化} \quad z &= 3x_1 + x_2 + 2x_3 \\ \text{满足约束条件:} \quad & x_1 + x_2 + 3x_3 \leq 30 \\ & 2x_1 + 2x_2 + 5x_3 \leq 24 \\ & 4x_1 + x_2 + 2x_3 \leq 36 \\ & x_1, x_2, x_3 \geq 0 \end{align} $$步骤1:转换为松弛型
引入松弛变量 $x_4, x_5, x_6$:
$$ \begin{align} z &= 3x_1 + x_2 + 2x_3 \\ x_4 &= 30 - x_1 - x_2 - 3x_3 \\ x_5 &= 24 - 2x_1 - 2x_2 - 5x_3 \\ x_6 &= 36 - 4x_1 - x_2 - 2x_3 \end{align} $$初始基本解:
- 基本解:$(\bar{x}_1, \bar{x}_2, ..., \bar{x}_6) = (0, 0, 0, 30, 24, 36)$
- 目标值:$z = 3 \times 0 + 1 \times 0 + 2 \times 0 = 0$
步骤2:第一次迭代
观察分析:
- 考虑增加 $x_1$ 的值(因为其系数为正,可以增加目标值),使所有值保持非负
- 从三个约束式可知:
- $x_1$ 超过 $30$ 时,$x_4$ 变负
- $x_1$ 超过 $12$ 时,$x_5$ 变负
- $x_1$ 超过 $9$ 时,$x_6$ 变负
- 因此,$x_1$ 最多取 $9$,此时 $x_6 = 0$
- 互换 $x_1$ 和 $x_6$($x_1$ 入基,$x_6$ 出基)
第一次迭代后:
$$ \begin{align} z &= 27 + \frac{x_2}{4} + \frac{x_3}{2} - \frac{3x_6}{4} \\ x_1 &= 9 - \frac{x_2}{4} - \frac{x_3}{2} - \frac{x_6}{4} \\ x_4 &= 21 - \frac{3x_2}{4} - \frac{5x_3}{2} + \frac{x_6}{4} \\ x_5 &= 6 - \frac{3x_2}{2} - 4x_3 + \frac{x_6}{2} \end{align} $$新基本解:
- 基本解:$(9, 0, 0, 21, 6, 0)$
- 目标值:$z = 27$
步骤3:第二次迭代
观察分析:
- 增加 $x_2$ 或 $x_3$ 都可增加目标值
- 设选择 $x_3$,从三个式子可知 $x_3$ 的最大值分别为 $18, 42/5, 3/2$
- 因此,选择第3个约束($x_3$ 最多取 $3/2$),围绕 $x_3$ 和 $x_5$ 进行转动
- 互换 $x_3$ 和 $x_5$($x_3$ 入基,$x_5$ 出基)
第二次迭代后:
$$ \begin{align} z &= \frac{111}{4} + \frac{x_2}{16} - \frac{x_5}{8} - \frac{11x_6}{16} \\ x_1 &= \frac{33}{4} - \frac{x_2}{16} + \frac{x_5}{8} - \frac{5x_6}{16} \\ x_3 &= \frac{3}{2} - \frac{3x_2}{8} - \frac{x_5}{4} + \frac{x_6}{8} \\ x_4 &= \frac{69}{4} + \frac{3x_2}{16} + \frac{5x_5}{8} - \frac{x_6}{16} \end{align} $$步骤4:第三次迭代
第三次迭代后:
$$ \begin{align} z &= 28 - \frac{x_3}{6} - \frac{x_5}{6} - \frac{2x_6}{3} \\ x_1 &= 8 + \frac{x_3}{6} + \frac{x_5}{6} - \frac{x_6}{3} \\ x_2 &= 4 - \frac{8x_3}{3} - \frac{2x_5}{3} + \frac{x_6}{3} \\ x_4 &= 18 - \frac{x_3}{2} + \frac{x_5}{2} \end{align} $$最终基本解:
- 此时,基本解是 $(8, 4, 0, 18, 0, 0)$
- 目标值 $z = 28$
- 因为目标函数中所有非基本变量的系数都是负数,无法继续增加目标值,求解结束!
最优解: $x_1 = 8, x_2 = 4, x_3 = 0$,最大值 $z = 28$
算法总结:
-
转换为松弛型:引入松弛变量将不等式转换为等式
-
找到初始基本可行解:将所有非基本变量设为 $0$
-
检验是否最优:检查目标函数中非基本变量的系数
- 如果都 $\leq 0$(最大化问题),则达到最优
- 如果都 $\geq 0$(最小化问题),则达到最优
-
选择入基变量:选择目标函数系数为正(最大化)或负(最小化)的非基本变量
-
选择出基变量:选择使入基变量取值最小的约束对应的基本变量
-
基变换:通过代数运算更新松弛型
-
重复步骤3-6:直到达到最优或判定无界
二、整数规划:问题定义
1. 整数规划的基本概念
整数规划的定义:
整数规划(Integer Programming, IP) 是在线性规划基础上,要求部分或全部决策变量必须取整数值的优化问题。
一般形式:
$$ \begin{align} \text{最大化(或最小化)} \quad & \sum_{i=1}^{n} c_ix_i \\ \text{满足约束条件:} \quad & \sum_{i=1}^{n} a_{ji}x_i \leq b_j \quad (j = 1,2,...,m) \\ & x_i \geq 0, \quad x_i \in \mathbb{Z} \quad (\text{部分或全部}\ i) \end{align} $$整数规划的分类:
根据变量的整数要求不同,整数规划可分为三类:
(1)混合整数规划(Mixed Integer Programming, MIP)
部分变量必须是整数,部分变量可以是连续值。对部分域所有$x_i$,满足:$x_i \geq 0$且为整数。
(2)纯整数规划(Pure Integer Programming, PIP)
所有决策变量都必须取整数值。对每个$x_i$,满足:$x_i \geq 0$且为整数。
(3)0-1整数规划(Binary Integer Programming)
变量只能取0或1两个值,用于表示"是/否"决策。对每个$x_i$,满足:$x_i \in \{0,1\}$。
2. 整数规划的实际应用示例
运输问题:
需要运输180台电视和110台洗衣机。有两种运输方式:
- 小型货车:可装载20台电视和20台洗衣机,成本360元
- 大型卡车:可装载40台电视和10台洗衣机,成本400元
数学模型:
$$ \begin{align} \text{最小化} \quad & 360x_1 + 400x_2 \\ \text{满足约束条件:} \quad & 20x_1 + 40x_2 \geq 180 \\ & 20x_1 + 10x_2 \geq 110 \\ & x_1, x_2 \geq 0, \quad x_1, x_2 \in \mathbb{Z} \end{align} $$其中$x_1$表示使用小型货车的数量,$x_2$表示使用大型卡车的数量。
3. 整数规划的建模技术
技术1:定义二元变量
除了约定部分或所有变量必须为整数值之外,也允许定义二元变量,即:$x_i \in \{0,1\}$。
优势:能够引入逻辑约束
示例:假设$x_i \in \{0,1\}$:
-
如果选择了$x_1$,则不能选择$x_2$,那么可以表示成:$x_1 + x_2 \leq 1$;
-
如果选择了$x_1$,则必须选择$x_2$,那么可以表示成:$x_1 \leq x_2$;
-
必须选择$x_1$或$x_2$,或两者均选取,那么可以表示成:$x_1 + x_2 \geq 1$;
技术2:限定变量的范围
目标:限定变量$x$的范围是:$x \leq 2$或者$x \geq 6$
方法:
挑选一个二元变量$w = \begin{cases} 1, & x \leq 2 \\ 0, & x \geq 6 \end{cases}$
设定$M$是一个很大的数,转变成为IP约束:
$$ \begin{align} x &\leq 2 + M(1-w) \\ x &\geq 6 - Mw \\ w &\in \{0,1\} \end{align} $$验证:
- 如果$x \leq 2$,则令$w = 1$:约束变为$x \leq 2$和$x \geq 6 - M$(后者自动满足)
- 如果$x \geq 6$,则令$w = 0$:约束变为$x \leq 2 + M$(自动满足)和$x \geq 6$
在两种情况下,IP约束都被满足。
技术3:表达复杂表达式之间的"或"关系
目标:表达复杂表达式之间的"或"关系
示例:$x_1 + 2x_2 \geq 12$或$4x_2 - 10x_3 \leq 1$
整数规划建模:
$$ \begin{align} x_1 + 2x_2 &\geq 12 - M(1-w) \\ 4x_2 - 10x_3 &\leq 1 + Mw \\ w &\in \{0,1\} \end{align} $$验证:
- 如果$w = 1$,则第一个约束生效:$x_1 + 2x_2 \geq 12$
- 如果$w = 0$,则第二个约束生效:$4x_2 - 10x_3 \leq 1$
技术4:考虑分段线性函数
目标:表达分段线性函数
示例:
$$ y = \begin{cases} 2x, & \text{if } 0 \leq x \leq 3 \\ 9-x, & \text{if } 4 \leq x \leq 7 \\ -5+x, & \text{if } 8 \leq x \leq 9 \end{cases} $$建模方法:
每段分别定义$w_i$和$x_i$:
$$ w_1 = \begin{cases} 1, & 0 \leq x \leq 3 \\ 0, & \text{otherwise} \end{cases}, \quad x_1 = \begin{cases} x, & 0 \leq x \leq 3 \\ 0, & \text{otherwise} \end{cases} $$类似地定义$w_2, x_2$和$w_3, x_3$
约束系统:
$$ \begin{align} & 0 \leq x_1 \leq 3w_1, \quad w_1 \in \{0,1\} \\ & 4w_2 \leq x_2 \leq 7w_2, \quad w_2 \in \{0,1\} \\ & 8w_3 \leq x_3 \leq 9w_3, \quad w_3 \in \{0,1\} \\ & w_1 + w_2 + w_3 = 1 \\ & x = x_1 + x_2 + x_3 \\ & x_i \text{ integer } \forall i \end{align} $$最终表达式:
$$y = 2x_1 + (9w_2 - x_2) + (-5w_3 + x_3)$$4. 整数规划问题求解:从两个变量开始
案例问题:
$$ \begin{align} \text{Maximize: } z &= 3x + 4y \\ \text{Subject to: } & 5x + 8y \leq 24 \\ & x, y \geq 0, \quad x, y \in \mathbb{Z} \end{align} $$简单的解法:
- 先求解线性规划(忽略整数要求),得到$x = 4.8, y = 0$和$z = 14.4$
- 四舍五入,得到$x = 5, y = 0$,但此解不可行!
- 取整,得到$x = 4, y = 0$,且$z = 12$。该解与$x = 0, y = 3$时的解值相同。
最优解:$x = 3, y = 1$,且$z = 13$
结论:
- Q1:最优整数解是什么? $(3, 1)$
- Q2:能否使用线性规划来解决整数规划问题? 不能直接使用,需要专门的算法
三、整数规划:分支界定法(Branch and Bound)
1. 枚举树 - 完全枚举思想
0-1背包问题示例:
有6件物品,背包容量不超过14,求最大利用率:
| 物品 | iPad | server | Brass Rat | Au Bon Pain | 6.041 tutoring | 15.053 dinner |
|---|---|---|---|---|---|---|
| 价格 | 5 | 7 | 4 | 3 | 4 | 6 |
| 利用率 | 16 | 22 | 12 | 8 | 11 | 19 |
数学模型:
$$ \begin{align} \text{Maximize: } & 16x_1 + 22x_2 + 12x_3 + 8x_4 + 11x_5 + 19x_6 \\ \text{Subject to: } & 5x_1 + 7x_2 + 4x_3 + 3x_4 + 4x_5 + 6x_6 \leq 14 \\ & x_i \in \{0,1\} \quad \text{for } 1 \leq i \leq 6 \end{align} $$枚举法分析:
- 考虑决策变量的所有可能值,即:$n \rightarrow 2^n$
- 想法:将问题分成两部分迭代。首次迭代时,考虑$x_1 \in \{0,1\}$的情况
- 树中的每个节点代表原始问题加上额外的约束条件
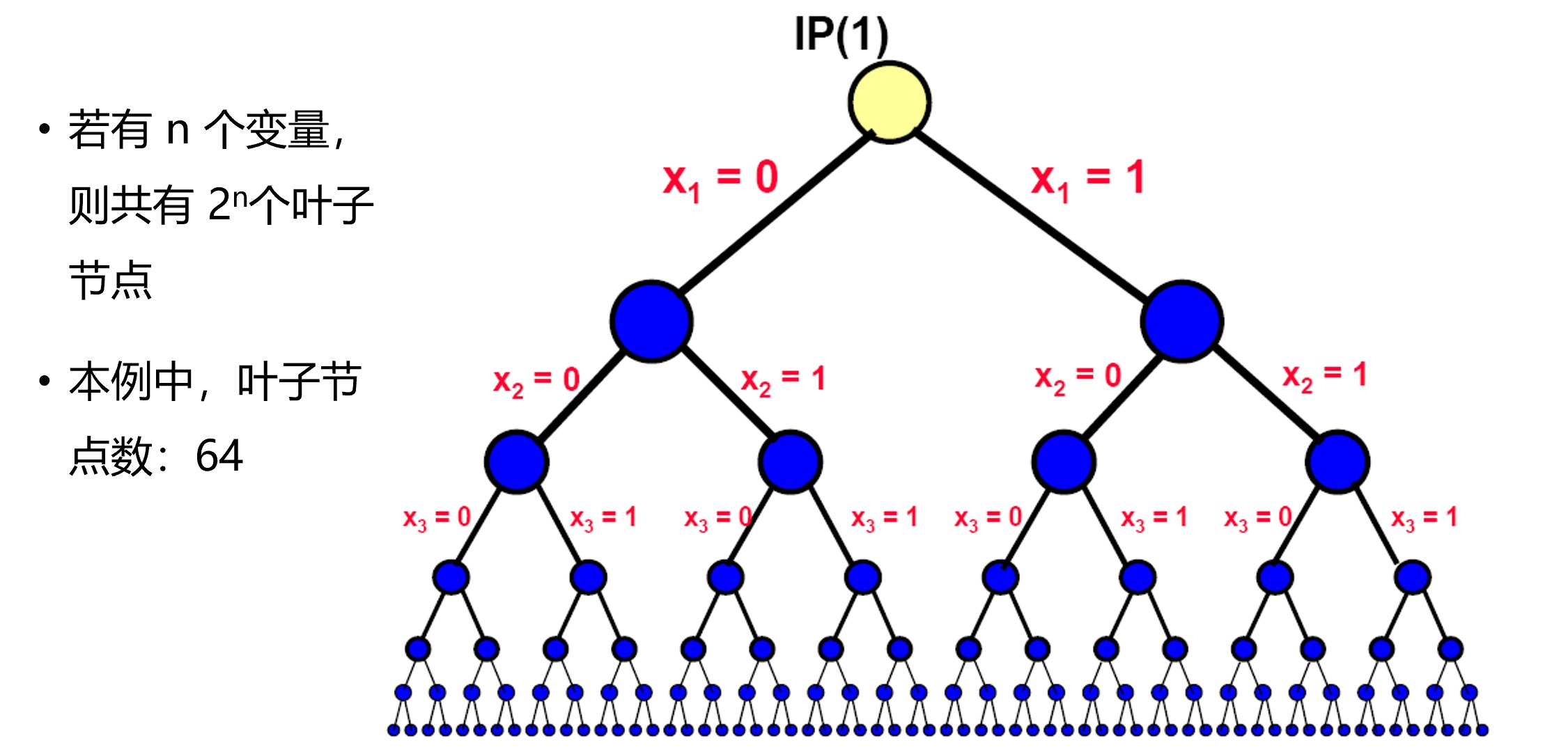
枚举树基本概念:
- 节点2和节点3被称为枝举树中节点1的子节点
- IP(1) 是原始的整数规划问题
- IP(2) 通过向IP(1)添加约束条件”$x_1 = 0$“得到
- IP(3) 通过向IP(1)添加约束条件”$x_1 = 1$“得到
- IP(1)的最优解可以通过从IP(2)和IP(3)中选取最好的解来获得(整数解)
- 最优解也可能在IP(2)和IP(3)两个分支中
2. 整数规划线性松弛
线性松弛(LP relaxation)的定义:
如果去掉变量必须为整数的要求,就称其为整数规划问题的线性松弛。
背包问题的线性松弛:
$$ \begin{align} \text{最大化: } & 24x_1 + 2x_2 + 20x_3 + 4x_4 \\ \text{约束条件: } & 8x_1 + 1x_2 + 5x_3 + 4x_4 \leq 9 \\ & 0 \leq x_i \leq 1, \quad \text{对于 } 1 \leq i \leq 4 \end{align} $$贪心算法求解:
背包问题的线性松弛可以通过"贪心算法"来求解:
可以将目标函数看作是美元金额,并将约束条件视为对重量的限制。
| item | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| value/lb. | $3 | $2 | $4 | $1 |
求解策略:
如果按照每磅价值从高到低依次将物品放入背包,会得到什么结果?
通过求解每个整数规划问题的线性松弛,可为每个整数规划问题得到一个界限。
(1) LP(k)的求解结果会给出一个具体的界限值。
示例:LP(4)的求解
$$ \begin{align} \text{Maximize: } & 24x_1 + 2x_2 + 20x_3 + 4x_4 \\ \text{Subject to: } & 8x_1 + 1x_2 + 5x_3 + 4x_4 \leq 9 \\ & x_1 = 0, x_2 = 0 \\ & 0 \leq x_i \leq 1 \text{ for } 3 \leq i \leq 4 \end{align} $$- LP(4)的最优解:$x_1 = 0, x_2 = 0, x_3 = 1, x_4 = 1, z = 24$
- 如果LP(k)的最优解对于IP(k)也是可行的,那么它也是IP(k)的最优解
重要性质:
对于所有$j$来说,$z_{IP}(j) \leq z_{LP}(j)$,例如:$z_{IP}(1) \leq 32$
不直接求解IP(k),而是求其线性松弛(LP relaxation),以获得边界值。
(2)当前最优解(incumbent)的定义:
算法偶然找到的、具有最佳目标函数值的可行整数解。
注意:当前最优解是整数规划问题的一个可行解,且是迄今为止找到的最佳解。
LP(1)的求解:
$$ \begin{align} \text{Maximize: } & 24x_1 + 2x_2 + 20x_3 + 4x_4 \\ \text{Subject to: } & 8x_1 + 1x_2 + 5x_3 + 4x_4 \leq 9 \\ & 0 \leq x_i \leq 1 \text{ for } i = 1 \text{ to } 4 \end{align} $$- LP(1)的最优解:$x_1 = 1/2, x_2 = 0, x_3 = 1, x_4 = 0, z = 32$
重要观察:
对于所有$j$来说,$z_{IP}(j) \leq z_{LP}(j)$,例如:$z_{IP}(1) \leq 32$
(3) 剪枝
推论:如果$z_{LP}(k) \leq z_I$,可以剪枝活动节点$k$的IP(k),其中$z_I$是当前最优解的目标函数值。
活动节点:节点尚未被剪枝,并且LP(k)还没有被解出来
LP(2)的分析:
$$ \begin{align} \text{Maximize: } & 24x_1 + 2x_2 + 20x_3 + 4x_4 \\ \text{Subject to: } & 8x_1 + 1x_2 + 5x_3 + 4x_4 \leq 9 \\ & x_1 = 0 \\ & 0 \leq x_i \leq 1 \text{ for } i = 2 \text{ to } 4 \end{align} $$- LP(2)的最优解为:$z_{LP}(2) = 25$
- 假设我们已经知道了一组解:$x_1 = 1, x_2 = 1, x_3 = 0, x_4 = 0, z_I = 26$,则可以剪枝LP(2)
3. 分支界定算法的完整流程
在什么条件下,我们不能从最大化的分支定界树中剪枝活动节点$j$?
算法伪代码:
while there is some active nodes do
select an active node j
mark j as inactive
Solve LP(j): denote solution as x(j);
Case 1 -- if z_LP(j) ≤ z_I then prune node j;
Case 2 -- if z_LP(j) > z_I and
if x(j) is feasible for IP(j)
then Incumbent := x(j), and z_I := z_LP(j);
then prune node j;
Case 3 -- if z_LP(j) > z_I and
if x(j) is not feasible for IP(j) then
mark the children of node j as active
endwhile
中文说明:
当存在某些活动节点时,执行以下操作:
- 选择一个活动节点$j$
- 将$j$标记为不活动
- 求解LP(j):令$x(j)$表示解决方案;
- 情况1–如果$z_{LP}(j) \leq z_I$,则剪枝节点$j$;
- 情况2–如果$z_{LP}(j) > z_I$且$x(j)$是IP(j)的可行解,则Incumbent $:= x(j)$,$z_I := z_{LP}(j)$;然后剪枝节点$j$;
- 情况3–如果$z_{LP}(j) > z_I$且$x(j)$不是IP(j)可行解,则标记节点$j$的子节点为活动节点
结束循环
4. 分支界定法案例
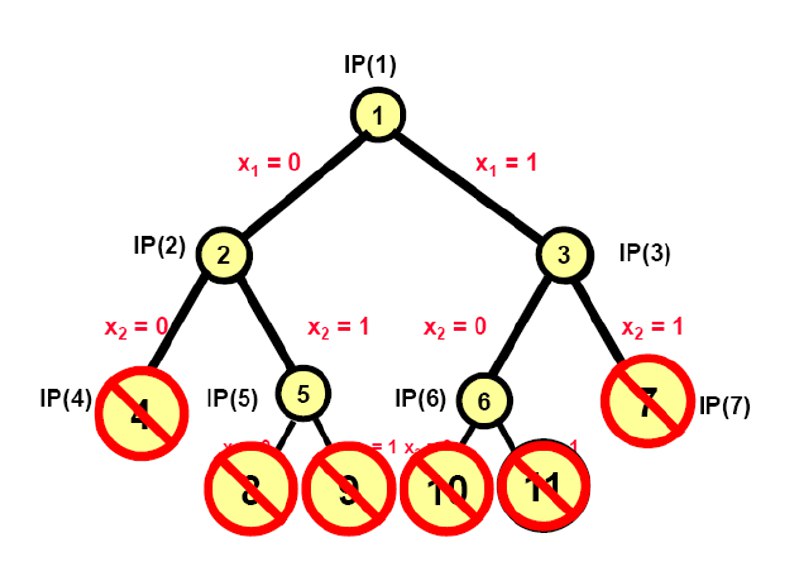
初始状态:LP(1)
$$ \begin{align} \text{Maximize: } & 24x_1 + 2x_2 + 20x_3 + 4x_4 \\ \text{Subject to: } & 8x_1 + 1x_2 + 5x_3 + 4x_4 \leq 9 \\ & 0 \leq x_i \leq 1 \text{ for } i = 1 \text{ to } 4 \end{align} $$- 没有当前最优解,$z_I = -\infty$
- LP(1)的最优方案是:$x_1 = 1/2, x_2 = 0, x_3 = 1, x_4 = 0, z_{LP}(2) = 32$
分支到LP(2):
- LP(2)的最优方案是:$x_1 = 0, x_2 = 1, x_3 = 1, x_4 = 3/4, z_{LP}(2) = 25$
分支到LP(3):
- 没有当前最优解,$z_I = -\infty$,$z_{LP}(1) = 32$
- LP(3)的最终方案是:$x_1 = 1, x_2 = 0, x_3 = 1/5, x_4 = 0, z_{LP}(3) = 28$
分支到LP(4):
- 没有当前最优解,$z_I = -\infty$,$z_{LP}(1) = 32$
- LP(4)的最优解:$x_1 = 0, x_2 = 0, x_3 = 1, x_4 = 1, z_{LP}(4) = 24$
- 剪枝完毕(因为都是整数),更新$z_I = 24$
分支到LP(5):
- 最优可行解$z_I = 24$
- LP(5)的最终方案是:$x_1 = 0, x_2 = 1, x_3 = 1, x_4 = 3/4, z_{LP}(5) = 25$
分支到LP(6):
- 当前最优解$z_I = 24$
- LP(6)的最优方案是:$x_1 = 1, x_2 = 0, x_3 = 1/5, x_4 = 0, z_{LP}(6) = 28$
分支到LP(7):
- 当前最优解$z_I = 24$
- LP(7)的最优解:$x_1 = 1, x_2 = 1, x_3 = 0, x_4 = 0, z_{LP}(7) = 26$
- 剪枝完毕(界限剪枝)
分支到LP(8):
- 当前最优解$z_I = 26$ (更新)
- LP(8)的最优解:$x_1 = 0, x_2 = 1, x_3 = 1, x_4 = 1, z_{LP}(8) = 6$
- 子树剪枝(界限剪枝,因为$z_{LP}(8) < z_I$)
分支到LP(9):
- 当前最优解$z_I = 26$
- LP(9)的最优解:$x_1 = 0, x_2 = 1, x_3 = 1, x_4 = 3/4, z_{LP}(9) = 25$
- 子树剪枝(界限剪枝,因为$z_{LP}(9) < z_I$)
分支到LP(10):
- 当前最优解$z_I = 26$
- LP(10)的最优解:$x_1 = 1, x_2 = 0, x_3 = 0, x_4 = 1/4, z_{LP}(10) = 25$
- 子树剪枝(界限剪枝,因为$z_{LP}(10) < z_I$)
最终分支LP(11):
- 当前最优解$z_I = 26$
- LP(11)的最优解:无可行解,可被剪枝
- 剪枝完毕(不可行剪枝)
最终结果:
- 最优整数解:$x_1 = 0, x_2 = 1, x_3 = 1, x_4 = 1, z^* = 26$
5. 分支界定法的经验总结
算法优势:
- 分支定界法可以加快搜索速度,仅解决部分节点的线性规划问题
算法局限:
- 分支定界法依赖于剪枝子树,这可能是因为节点处的整数规划(IP)问题已经被解决,或者因为该IP解不可能是最优解
- 当变量很多时,完全枚举不可能负担(即使是仅50个变量也有很大消耗)
加速技巧:
- 技巧一:能够"智能地"选择最佳分支变量的启发式规则
- 技巧二:使用"取整”,例如,将非整数解通过向上或向下取整转换为整数解,以此来快速获得可行解,从而缩小搜索范围
- 示例:$x_1 + x_2 \leq 1.5 \rightarrow x_1 + x_2 \leq 1$,or $z_{IP} \leq z_{LP} = 5.5 \rightarrow z_{IP} \leq 5$
四、整数规划:切平面法(Cutting Plane Method)
1. 有效不等式(Valid Inequalities)
定义:
整数规划(IP)的有效不等式是指任何不会排除任何可行整数解的约束条件。
示例问题:
最大化目标函数:$z = 3x + 4y$
约束条件:$5x + 8y \leq 24$ $0 \leq x, y \in \mathbb{Z}$(即x和y都是非负整数)
有效不等式的特点:
- 约束条件$x \leq 5$是一个有效不等式
- 约束条件$x \leq 4$同样是一个有效不等式
- 整数规划的一个有效不等式也被称为切割平面或切面
目标:
希望找到能排除部分线性规划可行区域的切割平面。
2. 取整(Rounding)技术
基本原理:
一个分数形式的整数变量边界可以被截断。
示例:
$x \leq 1.5 \rightarrow x \leq 1$
整数系数约束的取整:
给定一个涉及所有整数变量且系数也为整数的约束条件:
$3x + 6y + 9z \leq 11$ 可以转化为 $x + 2y + 3z \leq \lfloor 11/3 \rfloor = 3$
非负整数变量约束的取整:
对于涉及非负整数变量的约束条件:
$\sum a_i x_i \leq b$ 可以转化为 $\sum \lfloor b/a_i \rfloor x_i \leq \lfloor b \rfloor$
注意事项:
注意左边是整数,因此右边也可以被截断,但这并不一定比原始约束条件更严格。
3. Gomory切割(Gomory Cuts)
定义:
Gomory切割用于向所有整数规划问题(IPs)中添加有效不等式(也称为切割),对于改进界限非常有用。
核心思想:
Gomory切割是从线性规划(LP)松弛的最优单纯形表中的单个约束条件获得的。
假设前提:
这里假设所有变量必须取整数值。
情况一:所有左侧系数都在0到1之间
约束形式:$0.2x_1 + 0.3x_2 + 0.3x_3 + 0.5x_4 + x_5 = 1.8$
有效不等式(忽略来自$x_5$的贡献):
$0.2x_1 + 0.3x_2 + 0.3x_3 + 0.5x_4 \geq 0.8$
这种有效不等式通过从最优解中提取信息并创建新的约束条件,有助于排除非整数解,从而提高求解效率。
情况二:所有左边的系数都是非负的
约束形式:$1.2x_1 + 0.3x_2 + 2.3x_3 + 2.5x_4 + x_5 = 4.8$
有效不等式(focus on fractional parts):
$0.2x_1 + 0.3x_2 + 0.3x_3 + 0.5x_4 \geq 0.8$
情况三:通用情况
约束形式:$1.2x_1 - 1.3x_2 - 2.4x_3 + 11.8x_4 + x_5 = 2.9$
向下取整(特别担心负数):
$1x_1 - 2x_2 - 3x_3 + 11x_4 + x_5 \leq 2$
有效不等式(前面两个式子相减):
$0.2x_1 + 0.7x_2 + 0.6x_3 + 0.8x_4 \geq 0.9$
4. 凸包(Convex Hull)
定义:
凸包是包含所有整数解的最小线性规划可行区域。
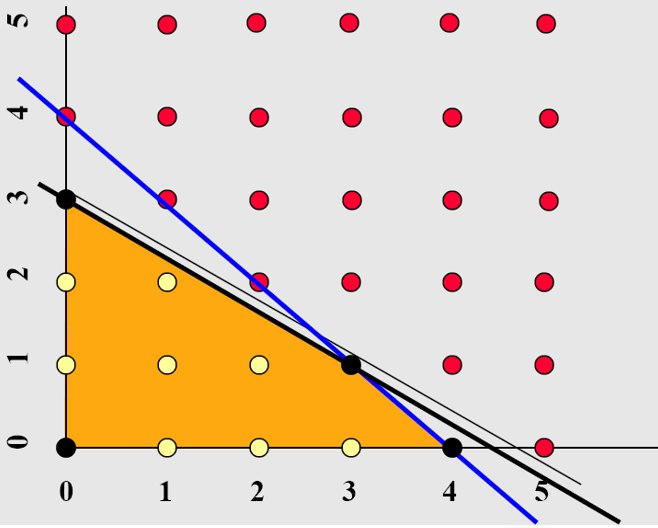
示例1:
最大化:$z = 3x + 4y$
约束条件:$5x + 8y \leq 24$ $0 \leq x, y \in \mathbb{Z}$
添加凸包 : $ x + y ≤ 4,2x + 3y ≤ 9$
示例2:
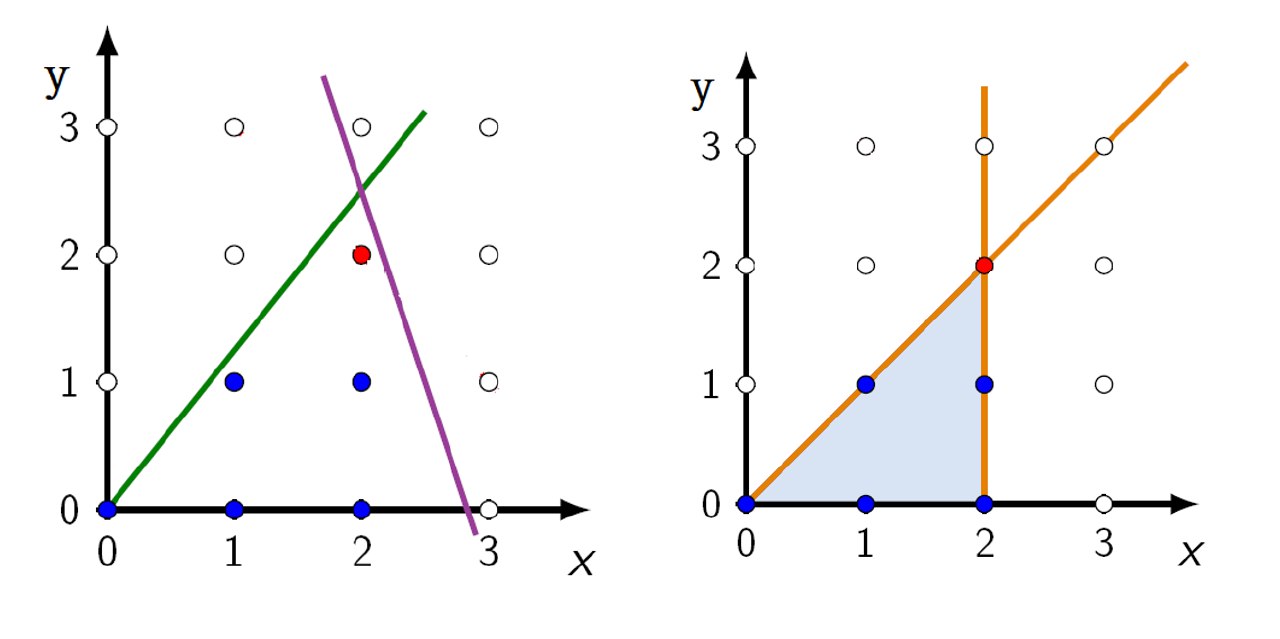
最大化:$z = x + y$
约束条件:$-5x + 4y \leq 0$ $6x + 2y \leq 17$ $0 \leq x, y \in \mathbb{Z}$
使用取整技术添加约束条件: $x ≤ 2,y ≤ x$
5. 切平面算法
算法步骤:
步骤1:求解线性规划松弛问题
步骤2:如果线性规划解是整数解,则它是原始问题的最优解。任务完成!
步骤3:如果线性规划解不是整数解,找到一个线性约束条件,该条件排除线性规划解但不排除任何整数点(总是可能的);
步骤4:加入切割约束条件;
步骤5:返回步骤1。
6. 切平面法案例详解
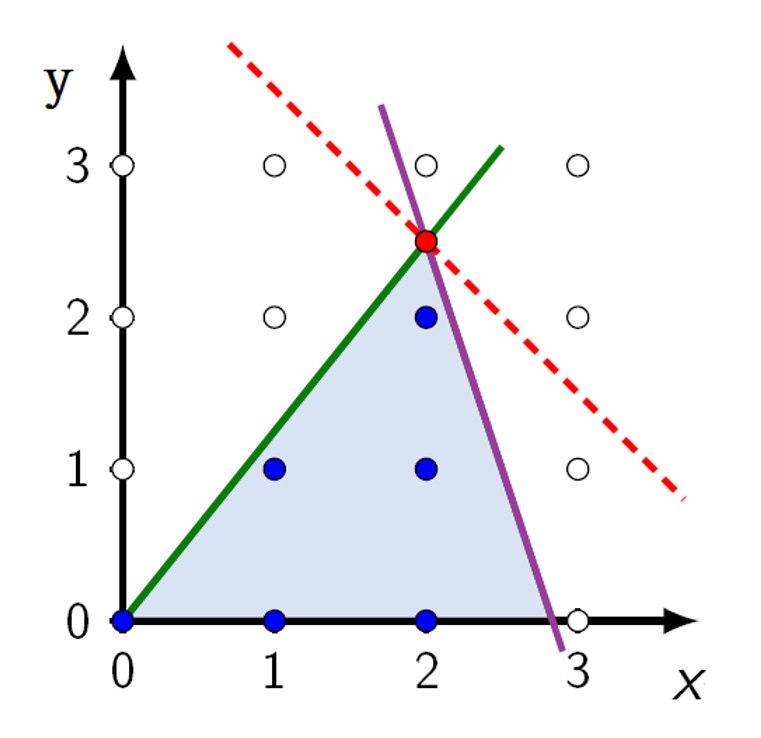
初始问题:
最大化:$z = x + y$
约束条件:$-5x + 4y \leq 0$ $6x + 2y \leq 17$ $0 \leq x, y \in \mathbb{Z}$
有效不等式:$0 \leq x, y \in \mathbb{Z}$
最优解 = 4.5($x = 2,y=2.5$)
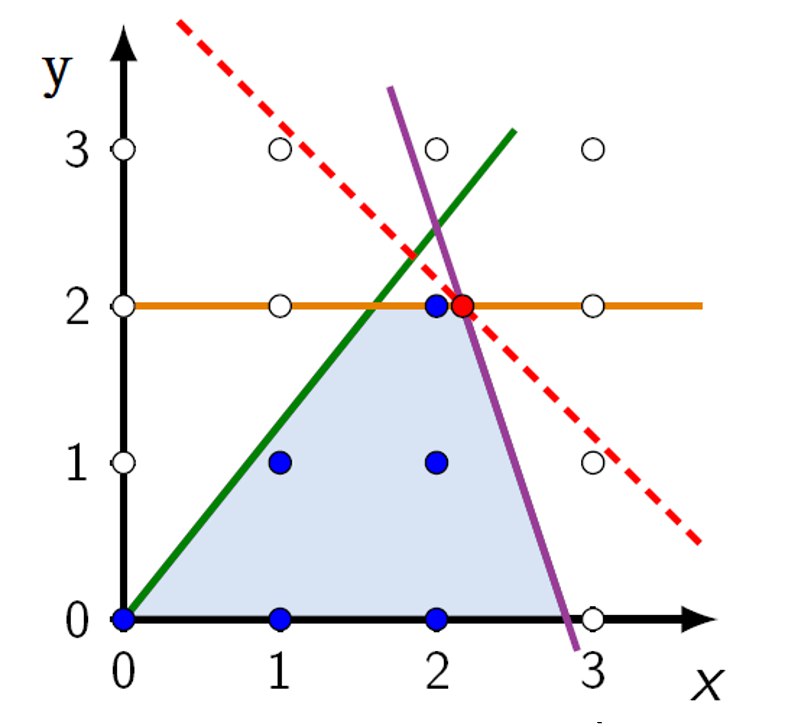
迭代1:添加约束y ≤ 2
- 最优解 z = 4.1667($x = 13/6,y=2$)
- 移除整数约束以获得线性松弛
- 最优解是对最优成本的一个上界
- 如果解是整数,则它是原始问题的最优解
分析:
约束条件$y \leq 2$是一个有效的切割,因为它排除了最优的线性规划解,但没有排除任何整数点。
现在求解这个新问题的线性规划松弛。
一个切割必须同时排除线性规划解,同时保留所有可行的整数点。至少存在一个有效的切割。
此时,仍然有变量不完全是整数。再加一个切割!
迭代2:添加约束x ≤ 2
最大化:$z = x + y$
约束条件:$-5x + 4y \leq 0$ $6x + 2y \leq 17$ $y \leq 2$ $x \leq 2$ $0 \leq x, y \in \mathbb{Z}$
最优解:$ x = 2, y = 2, z = 4$
线性规划的解都是整数,因此也是整数规划问题的最优解
7. 切平面法的特点总结
算法优势:
- 通过添加切割约束逐步收紧可行域
- 每次迭代都会改进上界
- 最终必定收敛到整数最优解
算法局限:
- 可能需要多次迭代
- 每次迭代需要求解一个线性规划问题
- 选择合适的切割平面需要一定技巧
与分支界定法的比较:
- 切平面法通过添加约束收紧可行域
- 分支界定法通过分支和剪枝搜索解空间
- 实际应用中常将两种方法结合使用(分支切割法)
第七讲 内存计算
一、海量内存概述
1. 传统数据处理模式 vs 内存数据处理模式
传统数据处理模式:
- CPU与内存之间频繁交互
- 内存与磁盘(硬盘)之间存在I/O瓶颈
- 数据需要从磁盘加载到内存,处理后再写回磁盘
- I/O操作成为性能瓶颈
内存数据处理模式:
- CPU直接与内存交互,减少I/O操作
- 数据主要存储和处理都在内存中完成
- 大幅减少或消除磁盘I/O瓶颈
- 显著提升数据处理速度
核心理念: Jim Gray在2006年提出的著名观点:
- “Tape is Dead”(磁带已死)
- “Disk is Tape”(磁盘就是磁带)
- “Flash is Disk”(闪存就是磁盘)
- “RAM Locality is King”(内存局部性为王)
解释: 随着技术发展,存储介质的角色在不断演变。内存成为数据处理的核心,其他存储介质逐渐降级为备份或归档用途。
2. 海量内存技术的发展趋势
硬件发展:
- 存储器芯片集成度不断提高
- 内存价格持续下降(如图所示,从1955年到2020年呈指数级下降)
- 内存容量大幅增长,使得海量数据内存处理成为可能
新型硬件架构:
- 3D XPoint™ Technology(英特尔傲腾技术)等新型存储技术的出现
带来的机遇与挑战: 海量内存给传统的数据管理、数据挖掘方法带来了新的机遇和挑战,需要重新设计算法和系统架构。
3. 内存计算的优势
根据Aberdeen Group 2011年的研究数据对比:

| 性能指标 | 使用内存计算 (n=33) | 不使用 (n=163) | 内存计算优势 |
|---|---|---|---|
| 活跃业务数据量(中位数) | 38 TB | 18 TB | 2.1倍数据量 |
| 分析数据量(中位数) | 14 TB (37%全部数据) | 4 TB (22%全部数据) | 3.5倍数据量 |
| 数据分析/查询平均响应时间 | 42秒 | 75分钟 | 107倍速度提升 |
| 每小时处理数据量 | 1200 TB | 3.2 TB | 375倍效率提升 |
主要优势:
- 消除了磁盘的I/O瓶颈
- 提高了单位时间内数据处理的能力与数据访问速度
- 实现了对大规模海量数据的实时分析和运算
- 提升数据挖掘的效率和准确度
二、基于单机版内存增大优势
1.关联规则
购物篮模型:从庞大的消费者记录中抽取关于购物模式的信息。
- 频繁项集是购物篮模型最基本的问题——
- 哪些商品经常被消费者同时购买(营销)
- 也被称为"关联规则”
- 从病例中寻找患某种疾病的病人的共同特征等。
关联规则挖掘:发现大量数据中项集之间的相关联系,是数据挖掘中最活跃的研究领域之一。
关联规则定义:设I = {I₁, I₂, …, Iₘ}是一个项目的集合,事务tᵢ(i = 1,2,…,n)是I的一个子集,则由一系列具有唯一标识TID的事务组成的D = {t₁, t₂, …, tₙ}称为事务数据库。
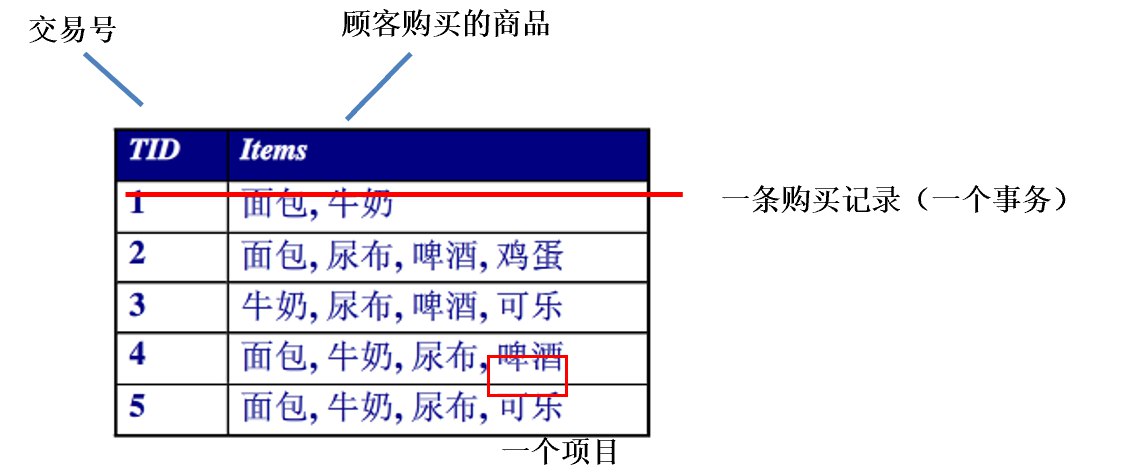
关联规则形如X ⇒ Y的蕴含式,X ⊆ I,Y ⊆ I,X∩Y = ∅。

度量指标:
- 支持度(support):support(面包,牛奶,尿布) = 2/5,计算公式为同时购买面包,牛奶,尿布的记录数/数据集记录总数
- 置信度(confidence):confidence(面包⇒牛奶,尿布) = 2/4,计算公式为同时购买面包,牛奶,尿布的记录数/数据集中购买面包的记录数
关联规则挖掘包含两个子问题:
- ①发现频繁项目集(基础和研究重点):寻找所有满足支持度不小于用户给定的minsupport的项目集
- ②生成关联规则:在已经发现的最大频繁项目集中,寻找置信度不小于用户给定的minconfidence的关联规则(一条规则的置信度很容易从支持度计数中推出;生成关联规则相对简单,且在内存、I/O、算法效率上的改进余地不大)
2.Apriori算法
基本信息:最经典的关联规则挖掘算法,由Agrawal等人于1993年提出。
基本思路:逐层迭代,通过连接和剪枝来生成频繁项集。流程为:数据库 → 候选1-项集 →(剪枝)→ 频繁1-项集 →(连接)→ 候选2-项集 → … → 频繁k-项集
两条定理——先验性质:
- 如果一个集合是频繁项集,则它的所有子集都是频繁项集
- 如果一个集合不是频繁项集,则它的所有超集都不是频繁项集
基本步骤:
- 假设规模为k的频繁项集为Lₖ,它的候选项集为Cₖ。
- 扫描数据库,对每一项进行累加计数,寻找规模为1的满足minsupport的频繁项集,然后迭代进行以下三步操作,生成所有的频繁项集:
- ①从规模为k的频繁项集中生成规模为k+1的频繁项集的候选集Cₖ₊₁;
- ②扫描数据库,计算候选项集中每一个候选的支持度;
- ③将满足最小支持度的项加入Lₖ₊₁。
发现频繁项集:以minsupport=2(绝对支持度计数)为例,通过多趟扫描逐步生成C₁→L₁→C₂→L₂→C₃→L₃。
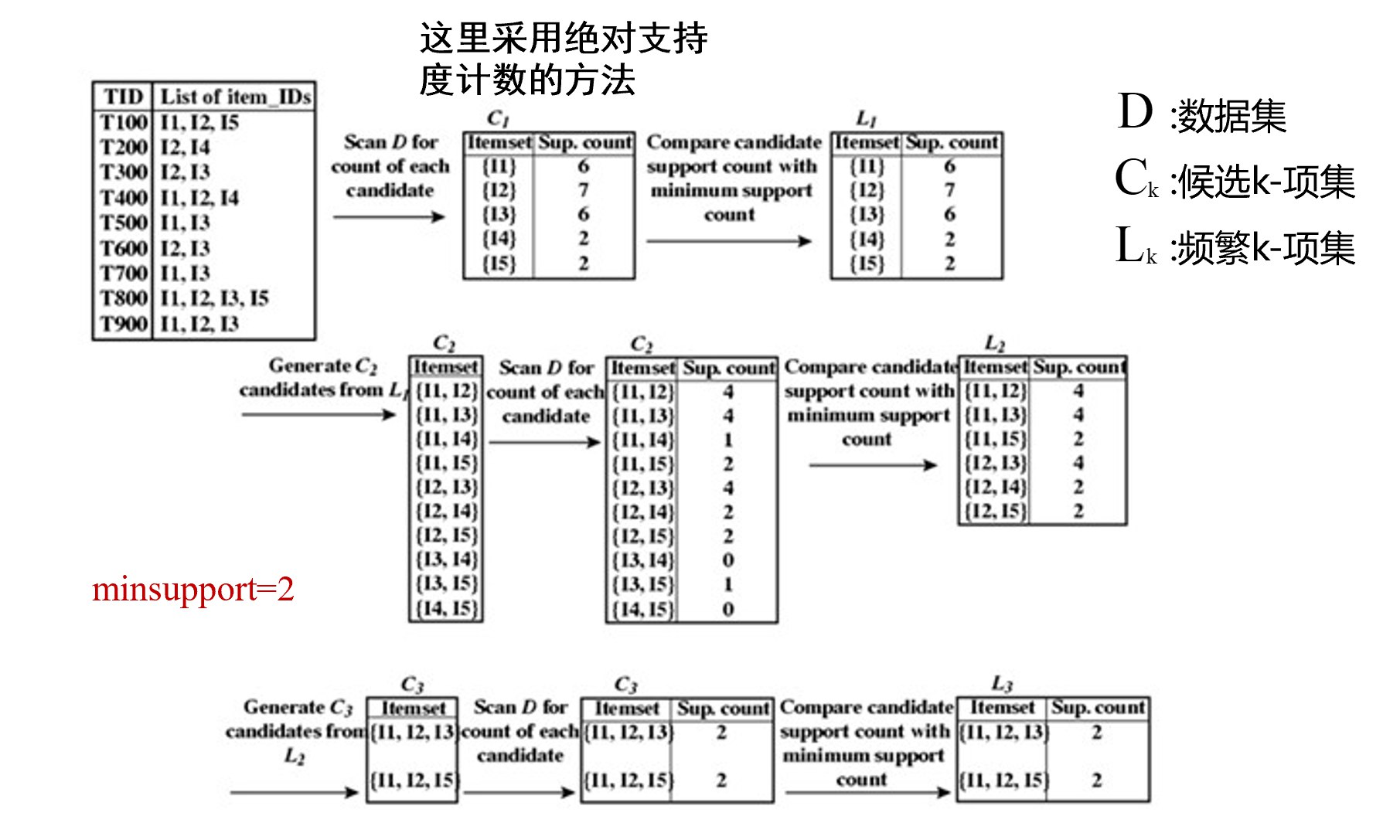
生成关联规则:给定一个频繁项集I,对于它的每个非空子集a,生成满足minconfidence的规则a ⇒ (I-a),该规则的confidence = support(I) / support(a)。示例:L₂中频繁项{I₁,I₂},规则I₁⇒I₂的置信度 = 4/6,规则I₂⇒I₁的置信度 = 4/7。
算法分析:虽然简单且易于实现,是最具代表性的关联规则挖掘算法,
缺点:
- 但随着数据集规模的不断增长,逐渐显现出一定的局限性:需多次扫描数据库,很大的I/O负载,算法的执行效率较低;
- 产生大量的候选项目集,会消耗大量的内存;
- 对于每一趟扫描,只有当内存大小足够容纳需要进行计数的候选集时才能正确执行。如果内存不够大,要么使用一种空间复杂度更小的算法,要么只能对一个候选集进行多次扫描,否则将会出现"内存抖动“的情况,即在一趟扫描中页面频繁地移进移出内存,造成运行时间的剧增。
观察:在Apriori算法的整个过程中,第一趟扫描时只需对规模为1的项计数,相对于对规模为2的项进行计数所需的空间而言是非常小的,而在第二趟扫描时,所有的可用空间基本都投入用于对候选集C₂进行计数。通过实验发现Apriori算法的内存瓶颈在第二趟扫描时出现,即对候选集C₂进行计数比对候选集C₃、C₄或规模更大的候选集进行计数所需的空间更大。
3.PCY算法
基本信息:得名于作者Park、Chen和Yu,1995年提出。将哈希技术引入频繁项集发现中,利用第一趟扫描时未使用的大量内存空间来完整地存放一张哈希表,减少了第二趟扫描时候选集C₂的数量。
主要思想:
- 第一趟扫描:对单个项进行计数的同时将商品对散列到对应的桶中,并将该桶的计数加1。频繁桶为最终计数值不小于minsupport的桶,非频繁桶为最终最终计数值小于minsupport的桶。
- 第二趟扫描:即使一个2-项集中的每一项都是频繁的,但如果它被散列到非频繁桶中,它就不可能是频繁项集,可以从候选项集中删除,这样就可大大减少要考虑的2-项集。
- 第一趟扫描与第二趟扫描之间:把桶替换成对应的二进制位的位图,如果对应的是频繁桶则该位为1,否则为0。一个占32位(4字节)的桶被换成了1位,在第二趟扫描时只需要1/32的空间并销,因此在第二趟扫描时,PCY算法可用来计数的空间几乎和Apriori算法一样大。
步骤:第一遍扫描生成频繁1-项集,同时对2-项集进行哈希得到哈希表和位向量;第二遍扫描通过L₁自连接生成候选集,使用位图过滤(只有哈希到频繁桶的才是候选),对候选项对计数。结果是候选2-项集的数目大大减少。
-
第一步:确定每个项的 order(顺序编号)
根据字母顺序:
- A 的 order = 1
- B 的 order = 2
- C 的 order = 3
- D 的 order = 4
- E 的 order = 5
-
第二步:计算每个2-项集的哈希位置
-
例子1:{A, C}
h(A,C) = (1 × 10 + 3) mod 7 = 13 mod 7 = 6 ✅ 映射到位置6 -
例子2:{B, C}
h(B,C) = (2 × 10 + 3) mod 7 = 23 mod 7 = 2 ✅ 映射到位置2
-
-
第三步:进行位向量统计
- 统计当前桶的元素个数是否$>=2$
- 得到如下位向量<1,0,1,0,1,0,1>
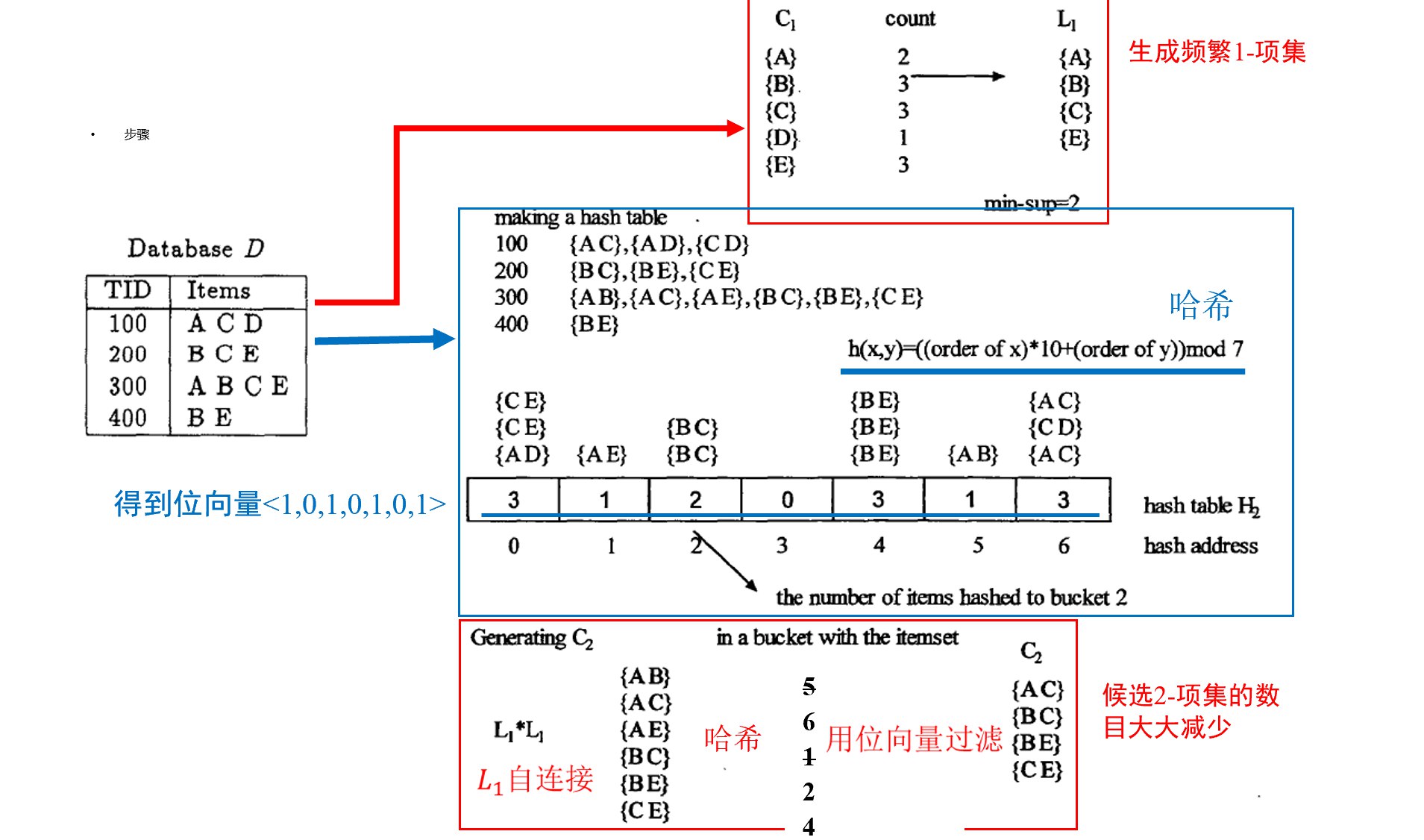
优点:高效地产生频繁项集,提升了性能;减少了数据库的扫描次数;减少计数所需的内存空间的大小。
分析:最差的情况是所有桶都是频繁桶,则第二遍扫描中PCY算法需要计算的相对数目与Apriori算法相比没有任何减少。在寻找频繁3-项集以及更多项集时,PCY算法与Apriori算法相同。
4.多阶段算法
主要思路:
- 在PCY的第一遍和第二遍之间插入额外的扫描过程,将2-项集哈希到另外的独立的哈希表中(使用不同的哈希函数)。
- 在每个中间过程中,只需哈希那些在以往扫描中哈希到频繁桶的频繁项。
- 需要三次扫描数据库。
步骤:
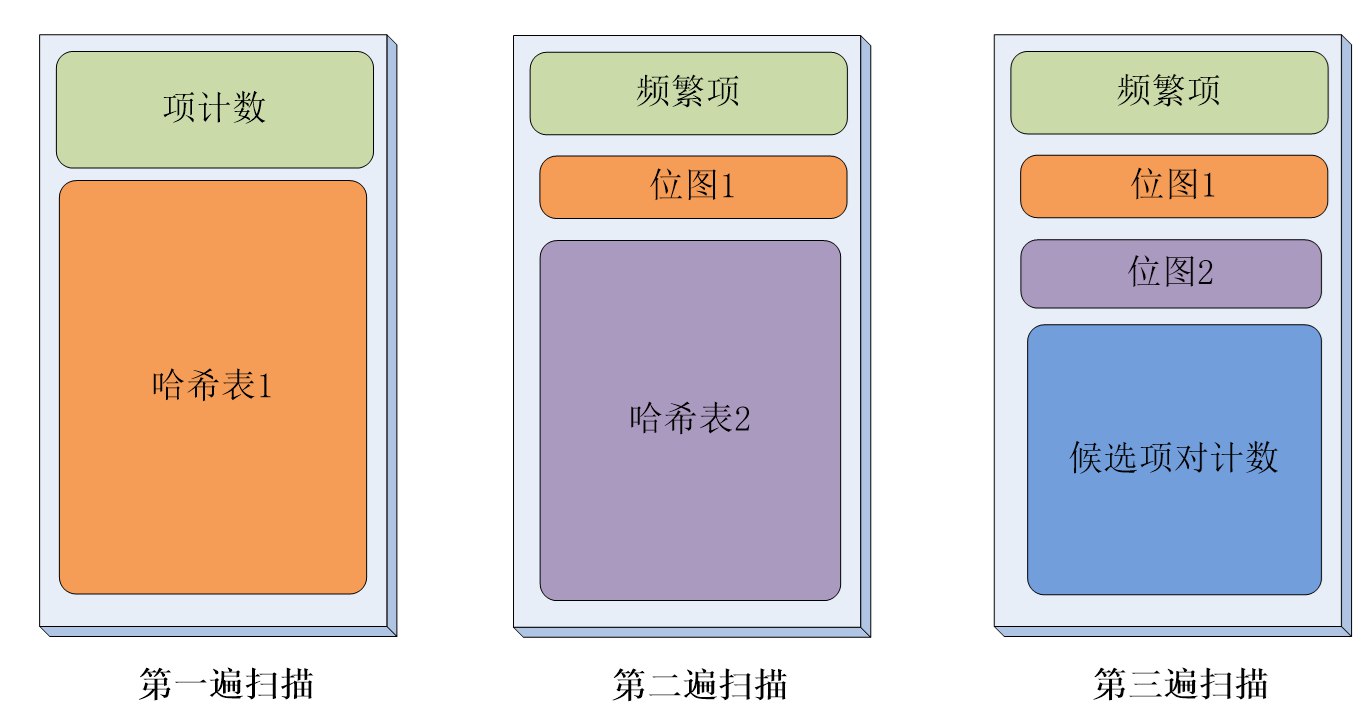
- 第一趟扫描与PCY算法相同;
- 第二趟扫描中2-项集{i,j}被哈希需满足①i和j都是频繁项、②第一趟扫描时{i,j}被哈希到了一个频繁桶,使用不同的哈希函数建立哈希表2;
- 第三趟扫描中{i,j}是候选2-项集需满足①i和j都是频繁项、②第一趟扫描时{i,j}被哈希到频繁桶(查询Bitmap1)、③第二趟扫描时{i,j}被哈希到频繁桶(查询Bitmap2)。
分析:
- Pass3的第③个条件是多阶段算法与PCY算法最本质的区别。
- 因为在第二趟扫描时,不是所有的2-项集都被散列到桶中,因此桶的计数值变得比第一趟扫描时更小,最终结果是更多的桶变成非频繁桶;(过滤更多)
- 由于两次扫描采用的哈希函数不同,那些在第一趟扫描时被散列到频繁桶中的非频繁2-项集很可能在第二趟扫描时被哈希到一个非频繁桶中,故排除很多通过了前两个条件判断的2-项集。
- 多阶段算法寻找频繁2-项集不只局限于使用3次扫描,
- 可以执行更多次用桶进行哈希的扫描,并且每次使用不同的哈希函数,后面的每一趟扫描都能排除更多的2-项集;
- 但是如果扫描的次数过多,不仅算法的执行次数更长,也有可能导致最终可用的内存小到无法对所有的频繁2-项集进行计数。
5.多哈希算法
定义:多哈希算法(Multihash Algorithm)是PCY算法的一种变形。
思路:对PCY算法的第一遍扫描进行修改,将内存划分为多张哈希表,第二遍扫描只需对所有哈希表中都哈希到频繁桶的两个频繁项组成的项对计数。
与多阶段算法的区别:多阶段算法是在连续的扫描过程中使用两个不同的哈希函数和哈希表,多哈希算法是在第一次扫描的过程中同时使用两个哈希函数和两张哈希表。
步骤:第一遍扫描统计频繁项,同时维护哈希表1和哈希表2;第二遍扫描输入频繁项+位图1+位图2,对同时在两个哈希表中都哈希到频繁桶的候选项对计数。
分析:
- 优点是只要桶的平均计数不小于阈值,频繁桶的数目仍然比较多,这样一个非频繁2-项集同时哈希到两个哈希表的频繁桶内的概率就更低,可以减少第二遍扫描的运算量。
- 风险是使用两个哈希表时,每个哈希表仅有PCY算法的一半的桶,这样每个桶上的平均计数会翻倍,必须保证大多数桶的计数不会达到阈值。
- 多哈希算法也不只局限于使用两个哈希表,风险是桶的平均计数可能会超过阈值。
三、基于共享式内存和分布式内存结合架构优势
1.三种系统架构
SMP (对称多处理)
- 也称UMA (一致性存储访问)
- 各处理器平等,访问内存任何地址时间相同
- 共享相同物理内存、总线结构和系统资源
- 主要特征是”共享",单一寻址空间,编程简单
- 缺点:受总线限制,可扩展性差
MPP (大规模并行处理)
- 多个SMP服务器通过互联网络连接
- “完全无共享(shared-nothing)“架构
- 每个节点只访问本地资源,通过消息传递机制交互
- 优点:可扩展性好
- 缺点:通信开销大,编程困难
NUMA (非一致性存储访问)
- 访问本地内存速度远高于远端内存
- 具有多个CPU模块,每个模块有独立的CPU、内存、I/O
- 每个CPU可访问系统中所有物理内存空间
- 结合SMP和MPP优势:保持对称性和单一地址空间,同时具备可扩展能力
- 属于分布/共享内存结构
2.SPADE算法
基本思想
- 利用垂直数据格式和连接-剪枝策略
- 只需对数据库进行三次扫描
- 产生频繁序列时只需对垂直数据序列进行交集操作
数据表示:垂直格式
- 将序列数据库从水平格式转换为垂直格式
- 每个项用ID_list表示,包含(CID, TID)对
- CID: 客户/序列标识
- TID: 事务/时间标识
- 通过扫描数据库构建每个项的ID_list
- 计算support: 统计ID_list中distinct CID数目
算法流程
第一步: 生成频繁1-序列
- 扫描数据库,构建每个单项的ID_list
- 统计每个项的distinct CID数目
- 与minsupport比较,得到频繁1-序列
第二步: 连接生成候选k-序列
示例: 从频繁1-序列生成频繁2-序列
频繁1-序列的ID_list:
| 项b | 项c | |||
|---|---|---|---|---|
| CID | TID | CID | TID | |
| 1 | 2 | 2 | 3 | |
| 1 | 3 | 3 | 2 | |
| 2 | 1 | 3 | 5 | |
| 2 | 4 | |||
| 3 | 2 |
连接过程详解:
要生成b→c(表示b在c之前发生):
- 查找同一个CID中,TID(b) < TID(c)的记录
- CID=1: b出现在TID=2,3; c出现在TID=无 → 没有满足条件的
- CID=2: b出现在TID=1,4; c出现在TID=3 → TID(b)=1 < TID(c)=3 ✓
- CID=3: b出现在TID=2; c出现在TID=2,5 → TID(b)=2 < TID(c)=5 ✓
要生成c→b(表示c在b之前发生):
- 查找同一个CID中,TID(c) < TID(b)的记录
- CID=1: c出现在TID=无; b出现在TID=2,3 → 没有c,不满足
- CID=2: c出现在TID=3; b出现在TID=1,4 → TID(c)=3 < TID(b)=4 ✓
- CID=3: c出现在TID=2,5; b出现在TID=2 → TID(c)=2不小于TID(b)=2 ✗
连接后生成的频繁2-序列ID_list:
| b→c (序列模式) | c→b (序列模式) | ||||
|---|---|---|---|---|---|
| CID | TID(b) | TID(c) | CID | TID(c) | TID(b) |
| 2 | 1 | 3 | 2 | 3 | 4 |
| 3 | 2 | 5 |
- 频繁(k-1)-序列与频繁(k-1)-序列连接形成候选k-序列
- 连接规则(必须同时满足):
- 共享相同的CID
- 前面项的TID必须在后面项的TID之前(遵守时间顺序)
- 通过两个序列的ID_list交集操作生成新序列的ID_list
- 例如: b→c表示在同一CID中,b的TID < c的TID
第三步: 剪枝得到频繁k-序列
判断哪些候选序列是频繁的:
假设最小支持度minsupport = 2(至少要在2个客户中出现)
- b→c序列: distinct CID = {2, 3} → 2个客户 → support=2 ≥ minsupport ✓ 保留,是频繁序列
- c→b序列: distinct CID = {2} → 1个客户 → support=1 < minsupport ✗ 剪枝,不是频繁序列
最终得到频繁2-序列:
| b→c (频繁序列) | ||
|---|---|---|
| CID | TID(b) | TID(c) |
| 2 | 1 | 3 |
| 3 | 2 | 5 |
算法的实际意义:
SPADE算法用于序列模式挖掘 - 发现用户购买行为的规律: 终止条件
- 找不到频繁序列,或
- 无法通过连接形成候选序列时,算法结束
优化特性
- ID_list会随着频繁序列长度增加而减小
- 连接操作速度随之加快
- 减少了内存占用和计算开销
等价类划分(搜索空间划分)
- 采用基于后缀的等价类划分搜索空间
- 形如Y→X和YX的序列都归入后缀类[X]
- 每个等价类是独立的,包含生成所有共享相同后缀的频繁序列所需的完整信息
- 可以在内存中独立处理每个等价类
- 为pSPADE的并行化提供基础
3.pSPADE算法
算法背景
- 第一个应用共享式内存架构进行并行序列模式挖掘的算法
- 工作在SGI Origin 2000系统(NUMA体系结构)的12台处理器上
- 采用硬件分布式共享存储(HDSM)架构
任务拆分
- 利用SPADE算法的等价类划分性质
- 所有处理器访问整个数据库的一份拷贝
- 并行地工作于不同的等价类,异步处理全局计算树
- 每个类的挖掘工作独立,处理器不需要同步
负载均衡策略
静态负载均衡(SLB)
- 根据等价类中元素数量分配权重
- 按权重递减顺序排序,依次分配给当前权值和最小的处理器
- 分配完毕后完全异步,无需同步或交互
- 示例:P0预先分配好了C1和C3,P1预先分配好了C2。然后就按照这个分配方案来实施。即使P1已经执行完毕所有任务了,它也无法分担P0的任务。
类间动态负载均衡(CDLB)
- 按权重将所有类递减排列成逻辑中心任务队列
- 处理器动态从队列获取类,处理完后自动获取下一个
- 示例:首先预估所有任务的工作量,进行排序,得C1, C2, C3。然后,分配P0来执行C1,分配P1来执行C2。结束早的那个处理器来执行C3。
递归动态负载均衡(RDLB)
- 有空闲处理器时,在树的每一新层递归运用CDLB方法
- 不同处理器能够处理新层次上的不同类
- 示例:首先预估工作量,排序得C1、C2、C3。然后P0预先分配好了C1和C3,P1预先分配好了C2,P1执行较快,则又执行C3。此时P0已经执行完毕,则它能够分配C3的子任务(X3)。依次类推,直到完全结束。
算法优点
- 减少数据库扫描次数,降低I/O操作开销
- 采用异步机制,只在负载失衡时同步
- 将搜索空间分成基于后缀的类,可独立处理
- 数据局域性最大化,同步最小化
- 动态负载均衡保证处理器负载均衡
- 解决大型数据库中搜索空间大、可扩展性差的问题
第八讲 社区发现
社区发现是复杂网络分析中的重要问题,目标是找出网络中紧密连接的节点群组。
一、图切割(Graph Partitioning)
1. 社区划分问题
给定无向图 $G = (V, E)$,其中:
- $V$ 表示所有的顶点(节点)集合
- $E$ 表示所有的边集合
任务: 将所有顶点分成两个不相交的组:
- 组 $A$:包含一部分节点
- 组 $B = V\backslash A$:包含剩余的所有节点(即 $V$ 中除了 $A$ 之外的所有节点)
核心问题: 如何评判这个划分的好坏?
2. 评判准则
一个良好的社区划分应该满足:
- 最大化社区内部的连接数:同一个社区内的节点之间应该有尽可能多的边连接
- 最小化社区之间的连接数:不同社区之间的连接应该尽可能少
3. 割(Cut)的定义
为了量化划分的质量,我们引入"割"的概念。
割(cut) 是指:只有一个端点在社区 $A$ 内,另一个端点在社区 $A$ 外的所有边的权重之和。
数学表达式:
$$cut(A) = \sum_{i \in A, j \notin A} w_{ij}$$公式解释:
- $i \in A$:节点 $i$ 在社区 $A$ 中
- $j \notin A$:节点 $j$ 不在社区 $A$ 中(即在社区 $B$ 中)
- $w_{ij}$:连接节点 $i$ 和节点 $j$ 的边的权重(如果是无权图,权重为1)
- $\sum$:对所有满足条件的边进行求和
通俗理解: 割就是"跨越两个社区的边的总权重”,这个值越小,说明两个社区之间的连接越少,划分越好。
求解方法: 存在多项式时间算法来求解最小割问题,特别是 Edmonds-Karp 算法,其时间复杂度为 $O(|V| \cdot |E|^2)$。
4. 最小割 (Minimum-cut)
目标: 找到一个划分 $(A, B)$,使得 $cut(A,B)$ 的值最小。
$$\arg\min_{A,B} cut(A,B)$$公式解释:
- $\arg\min$:表示"使得后面的值最小的参数”
- 即找到使 $cut(A,B)$ 最小的划分方式 $(A, B)$
最小割的局限性:
虽然最小割能找到连接最少的划分,但存在明显的问题:
- 只考虑簇间的联通性:只关心两个社区之间有多少连接
- 不考虑簇内的连通性:不关心每个社区内部的结构
- 可能产生不平衡的划分:例如,将一个孤立的节点分离出来,只需要切断很少的边,但这样的划分是没有意义的
举例说明: 假设有一个图,其中有一个节点只通过一条边连接到主图,那么最小割会将这个节点单独分离出来(只需切断1条边),但这样的划分显然不合理。
5. 归一化切割 (Normalized-cut)
为了解决最小割的问题,我们引入归一化切割,它同时考虑了簇间的连通性和各簇的规模。
体积(Volume)的定义: 首先需要定义社区 $A$ 的"体积" $vol(A)$:
$$vol(A) = \sum_{i \in A} k_i$$其中 $k_i$ 是节点 $i$ 的度(degree),即连接到节点 $i$ 的所有边的权重之和。$vol(A)$ 表示至少有一个端点在社区 $A$ 中的所有边的总权重,反映了社区 $A$ 的"规模"或"密度"。
归一化切割的定义:
$$ncut(A,B) = \frac{cut(A,B)}{vol(A)} + \frac{cut(A,B)}{vol(B)}$$公式解释:
- 第一项 $\frac{cut(A,B)}{vol(A)}$:割的大小相对于社区 $A$ 的规模
- 第二项 $\frac{cut(A,B)}{vol(B)}$:割的大小相对于社区 $B$ 的规模
- 两项相加:综合考虑两个社区的规模
为什么要归一化? 通过除以各自的体积,我们将割的大小"标准化"了。这样如果一个社区很大($vol$ 很大),即使割的值不变,归一化后的值也会变小,从而避免了将单个节点分离出来的情况(因为单个节点的 $vol$ 很小,归一化后的值会很大)。
优势:
- 使划分更加平衡,避免产生极小的社区
- 同时考虑了社区间的连接和社区的规模
挑战:
- 计算归一化割是 NP-hard 问题
- 需要使用近似算法或启发式方法来高效地找到好的划分
6. 练习题详解
题目: 对于给定的图(红色节点和绿色节点),分别计算最优切割和最小切割的 $ncut$ 值。
题目分析: 从图中可以看到两种切割方式:
- 最优切割(蓝色虚线):在红色社区(左侧)和绿色社区(右侧)之间进行切割
- 最小切割(红色虚线):将右下角单个绿色节点孤立出来
(1)最小切割的 $ncut$ 值计算
划分方式:社区 $A$ 为红色节点+5个绿色节点,社区 $B$ 为右下角单个绿色节点。
- $cut(A,B) = 1$(只有1条边连接孤立节点)
- $vol(A) = 51(共有25条边和1条半边)
- $vol(B) = 1$(节点完全孤立,内部没有边,只需要考虑还未割出的那条边,因此度为1)
- $ncut_{\text{min}} = \frac{1}{51} + \frac{1}{1} = \frac{52}{51} \approx 1.02$
这说明将单个节点完全孤立是一个极差的划分!
(2)最优切割的 $ncut$ 值计算
划分方式:社区 $A$ 为所有红色节点(左侧10个节点),社区 $B$ 为所有绿色节点(右侧6个节点)。
- $cut(A,B) = 2$(2条边跨越蓝色虚线)
- $vol(A) = 32$(红色区域内部15条边+2条半边)
- $vol(B) = 20$(绿色区域内部9条边+2条半边)
- $ncut_{\text{optimal}} = \frac{2}{32} + \frac{2}{20} = \frac{1}{16} + \frac{1}{10} = \frac{13}{80} =0.1625$
结果对比:
| 切割方式 | $cut(A,B)$ | $vol(A)$ | $vol(B)$ | $ncut$ 值 |
|---|---|---|---|---|
| 最小切割 | 1 | 51 | 1 | 1.02 |
| 最优切割 | 2 | 30 | 18 | 0.1625 |
结论:
- 最小切割将单个节点孤立后,$vol(B) = 1$ 导致 $ncut$ 值增大,这是最差的划分
- 最优切割虽然 $cut$ 值不是最小,但 $ncut$ 值很小,实现了平衡且合理的划分
- 归一化切割通过考虑社区规模,避免了不合理的极端划分,$ncut$ 值越小说明划分越好
二、边介数(Edge Betweenness)
1. 边介数的定义
边介数(Edge Betweenness):通过该边的最短路径的数量。
作用:
- 用于衡量图中一条边的重要性或中心性
- 反映图中有多少条最短路径经过该边
重要性判断:
- 若很多最短路径都经过该边,则该边对于保持图的高效连接性就非常重要
- 相反,如果仅少数最短路径经过该边,则该边的重要性就较低
应用价值:
边介数有助于识别图中的关键连接,即这些连接一旦断裂会显著影响图中节点之间的通信效率。
示例:
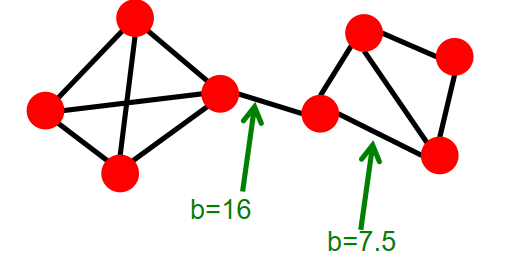
在下图中,不同的边具有不同的边介数值:
- 左侧的边:$b = 16$(有16条最短路径经过)
- 右侧的边:$b = 7.5$(有7.5条最短路径经过)
边介数越大,该边在网络中的重要性越高。
2. Girvan-Newman方法(简称GN方法)
GN方法定义:
Girvan-Newman方法是一种基于边介数概念的层次聚类算法,适用于无向无权网络。
算法流程:
重复以下步骤直到没有边剩余:
- 计算边介数:计算网络中所有边的边介数
- 移除边介数最高的边:找到边介数最大的边并将其从图中删除
- 重新计算:在每个步骤后,需要重新计算剩余边的边介数
输出结果:
- 相连接的边构成社区
- 可输出网络的层次分解
重要提示: 在每个步骤,均需重新计算边介数,因为移除一条边会影响其他边的最短路径。
3. GN方法案例分析
考虑下图所示的网络,应用GN方法进行社区划分:
Step 1: 计算所有边的边介数,移除边介数最高的边(边7-8,边介数为49)
结果:图被分成两个主要部分
Step 2: 重新计算剩余边的边介数,继续移除边介数最高的边
结果:进一步细分,形成更小的社区
Step 3: 持续迭代,直到所有边都被移除
结果:每个节点成为独立的社区
最终输出:层次状的网络划分
通过记录每次移除边的顺序,可以构建一个层次树(dendrogram),展示网络在不同粒度下的社区结构。
4. 如何计算边介数
(1)基本方法:构建根节点到其余子节点的最短路径数量
步骤1:构建最短路径树
从起始节点(如节点A)开始,使用BFS构建到所有其他节点的最短路径树,并标记每个节点的层次:
- 第0层:起始节点A
- 第1层:与A直接相连的节点(B, C, D, E)
- 第2层:距离A为2的节点(F, G, H)
- 第3层:距离A为3的节点(I, J)
- 第4层:距离A为4的节点(K)
步骤2:计算最短路径数量
计算从起始节点A到网络中其他每个节点的最短路径数量。
公式:
从A到某个节点X的最短路径数量 = 所有能到达X的父节点的最短路径数量之和
示例:
- 从A到H的最短路径数量 = 从A到D的最短路径数量 + 从A到E的最短路径数量
- 从A到K的最短路径数量 = 从A到I的最短路径数量 + 从A到J的最短路径数量
(2)自底向上计算边介数:如果存在多条最短路径,则可按比例划分边介数。
算法步骤:
-
添加边流
- 初始化:每个节点的流 = 1 + 其所有子边的流之和
- 根据父节点的值分配流
-
对于每个起始节点U,重复广度优先搜索过程
详细计算规则:
对于某条边 $(X, Y)$,其边介数的计算遵循以下规则:
- 如果从A到Y只有一条最短路径经过X,则该边获得完整的流
- 如果从A到Y有多条最短路径(通过不同的父节点),则按照各父节点的最短路径数量比例分配流
具体案例:
以节点为K为例:
- K对于A而言是叶子节点,所以他的流为1(根据算法规则:子节点的流为0),
- 共有2条最短路径可被分配,根据I,J各有三条最短路径,为3:3,即1:1,因此每条边分配 $\frac{1}{2}$
以节点I为例:
- A-I的最短路径总和算1,外加经过I到K的0.5,所以I的流为1.5
- I有1.5可被分配,按照2:1的比例划分(因为A到F有2条最短路径,到G有1条最短路径)
- 故边$V_{F,I}$得到的流为1,边$V_{G,I}$得到的流为0.5
以此自下而上故能得到所有边的边介数
5. 练习题
题目:给定下图所示的网络结构,请计算从节点B开始的路径边介数。
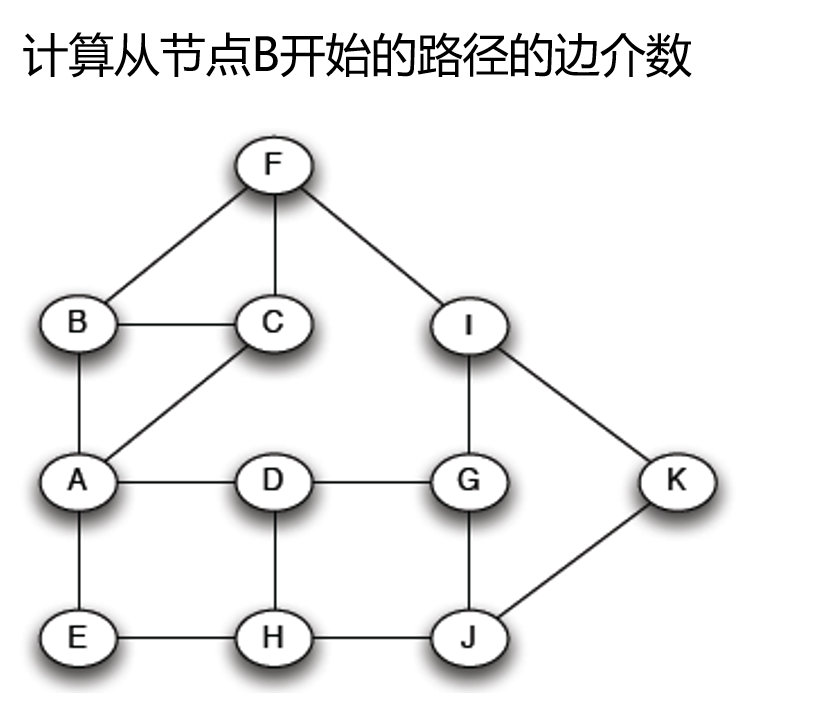
步骤1:构建最短路径树
从起始节点B开始,使用BFS构建到所有其他节点的最短路径树,并标记每个节点的层次:
- 第0层:起始节点B
- 第1层:与B直接相连的节点(A,C,F)
- 第2层:距离B为2的节点(D,E,I)
- 第3层:距离B为3的节点(G,H,K)
- 第4层:距离B为4的节点(J)
步骤2:计算最短路径数量
计算从起始节点B到网络中其他每个节点的最短路径数量。定义节点B到节点I的最短路径数量的方法为$N(i)$,故
- 第0层:起始节点B
- 第1层:与B直接相连的节点$N(A) = 1$,$N(C) = 1$,$N(F) = 1$
- 第2层:距离B为2的节点$N(D) = N(A)=1$,$N(E) = N(A)=1$,$N(I)=N(F) = 1$
- 第3层:距离B为3的节点$N(G) = N(D)+N(I)=2$,$N(H) = N(D)+N(E)=2$,$N(K)=N(I) = 1$
- 第4层:距离B为4的节点$N(J) = N(G)+N(H)+N(K) = 5$
步骤3:自底向上计算边介数
每个节点的流 = 1 + 其所有子边的流之和,根据父节点的最短路径数量按比例分配流。
-
第4层:距离B为4的节点(J),J为叶子节点,所以J的流为1,分配边流:
$$V_{G,J} = \frac{N(G)}{N(J)} \times 1 = \frac{2}{5}, \quad V_{H,J} = \frac{N(H)}{N(J)} \times 1 = \frac{2}{5}, \quad V_{K,J} = \frac{N(K)}{N(J)} \times 1 = \frac{1}{5}$$ -
第3层:距离B为3的节点(G,H,K),计算各自的流:
- G的流 $= 1 + \frac{2}{5} = \frac{7}{5}$,分配边流:$V_{D,G} = \frac{N(D)}{N(G)} \times \frac{7}{5} = \frac{1}{2} \times \frac{7}{5} = \frac{7}{10}$,$V_{I,G} = \frac{N(I)}{N(G)} \times \frac{7}{5} = \frac{1}{2} \times \frac{7}{5} = \frac{7}{10}$
- H的流 $= 1 + \frac{2}{5} = \frac{7}{5}$,分配边流:$V_{D,H} = \frac{N(D)}{N(H)} \times \frac{7}{5} = \frac{1}{2} \times \frac{7}{5} = \frac{7}{10}$,$V_{E,H} = \frac{N(E)}{N(H)} \times \frac{7}{5} = \frac{1}{2} \times \frac{7}{5} = \frac{7}{10}$
- K的流 $= 1 + \frac{1}{5} = \frac{6}{5}$,分配边流:$V_{I,K} = \frac{N(I)}{N(K)} \times \frac{6}{5} = 1 \times \frac{6}{5} = \frac{6}{5}$
-
第2层:距离B为2的节点(D,E,I),计算各自的流:
- D的流 $= 1 + \frac{7}{10} + \frac{7}{10} = 1 + \frac{14}{10} = \frac{12}{5}$,分配边流:$V_{A,D} = \frac{N(A)}{N(D)} \times \frac{12}{5} = 1 \times \frac{12}{5} = \frac{12}{5}$
- E的流 $= 1 + \frac{7}{10} = \frac{17}{10}$,分配边流:$V_{A,E} = \frac{N(A)}{N(E)} \times \frac{17}{10} = 1 \times \frac{17}{10} = \frac{17}{10}$
- I的流 $= 1 + \frac{7}{10} + \frac{6}{5} = 1 + \frac{7}{10} + \frac{12}{10} = \frac{29}{10}$,分配边流:$V_{F,I} = \frac{N(F)}{N(I)} \times \frac{29}{10} = 1 \times \frac{29}{10} = \frac{29}{10}$
-
第1层:距离B为1的节点(A,C,F),计算各自的流:
- A的流 $= 1 + \frac{12}{5} + \frac{17}{10} = 1 + \frac{24}{10} + \frac{17}{10} = \frac{51}{10}$,分配边流:$V_{B,A} = \frac{51}{10} = 5.1$
- C的流 $= 1 + 0 = 1$,分配边流:$V_{B,C} = 1$
- F的流 $= 1 + \frac{29}{10} = \frac{39}{10}$,分配边流:$V_{B,F} = \frac{39}{10} = 3.9$
三、模块度(Modularity)
1.模块度
模块度(Modularity)是衡量图结构划分优劣的重要指标。
令 G=(V,E) 为一个无向图,其邻接矩阵为 A:
$$A_{ij} = \begin{cases} 1, & \text{if } (v_i, v_j) \in E \\ 0, & \text{otherwise} \end{cases}$$模块度的定义为:
$$Q = \frac{1}{2m}\sum_{i,j} \left(A_{ij} - \frac{k_i k_j}{2m}\right)\delta(C_i, C_j)$$其中,$m$表示边的数量,$Ci $表示第 $i$ 个社区。$k_i$ 是顶点 $v_i$ 的度(即与顶点 $v_i$ 相连的边的数量),$δ(Ci, Cj) = 1(如果 Ci = Cj)$,否则为 0。
模块度的直观解读
模块度用于衡量网络被划分为社区的好坏程度的一种度量。给定网络被划分为一组 c ∈ C 的情况:
$$Q \propto \sum_{i,j}\left(A_{ij} - \frac{k_i k_j}{2m}\right)\delta(C_i, C_j) = \left[\sum_{i,j} A_{ij} - \sum_{i,j} \frac{k_i k_j}{2m}\right]\delta(C_i, C_j)$$$$= \sum_{c \in C} [(\# \text{ edges within group } c) - (\text{expected } \# \text{ edges within group } c)]$$给定一个图 G,含 n 个节点和 m 条边,构建一个随机图 G’:
- 保持相同的度分布,但边是随机生成
- G’ 是一个多重图
模块度计算
$$Q = \frac{1}{2m}\sum_{c \in C}\sum_{i \in c}\sum_{j \in c}\left(A_{ij} - \frac{k_i k_j}{2m}\right)$$- 模块度的取值范围是 [-1, 1]
- 如果组内边的数量超过了预期数量,则模块度值为正
- 当模块度 M 大于 0.3 至 0.7 时,意味着输入图中存在显著的社区结构
- 是用于评估社区结构好坏的度量
模块度案例
$m = 8, k_1 = 2, k_2 = 2, k_3 = 3, k_4 = 3, k_5 = 2, k_6 = 2, k_7 = 2$
划分方案1:社区划分: 社区$A = {1,2,3}$, 社区$B = {4,5,6,7}$
模块度计算:
$$ \begin{aligned} Q &= \frac{1}{2m}\sum_{i,j} \left( A_{ij} - \frac{k_i k_j}{2m} \right)\delta(C_i, C_j) \\\\[8pt] &= \frac{1}{16}\Bigg[ \left(0 - \frac{k_1 k_1}{16}\right) + 2\left(1 - \frac{k_1 k_2}{16}\right) + 2\left(1 - \frac{k_1 k_3}{16}\right) + \left(0 - \frac{k_2 k_2}{16}\right) \\\\[4pt] &\quad + 2\left(1 - \frac{k_2 k_3}{16}\right) + \left(0 - \frac{k_3 k_3}{16}\right) + \left(0 - \frac{k_4 k_4}{16}\right) + 2\left(1 - \frac{k_4 k_5}{16}\right) \\\\[4pt] &\quad + 2\left(1 - \frac{k_4 k_6}{16}\right) + 2\left(0 - \frac{k_4 k_7}{16}\right) + \left(0 - \frac{k_5 k_5}{16}\right) + 2\left(0 - \frac{k_5 k_6}{16}\right) \\\\[4pt] &\quad + 2\left(1 - \frac{k_5 k_7}{16}\right) + \left(0 - \frac{k_6 k_6}{16}\right) + 2\left(1 - \frac{k_6 k_7}{16}\right) + \left(0 - \frac{k_7 k_7}{16}\right) \Bigg] \\\\[8pt] &= \frac{51}{128} \end{aligned} $$划分方案2:社区划分: 社区$A = {1,2}$, 社区$B = {3,4,5,6,7}$
模块度计算:
$$ \begin{aligned} Q &= \frac{1}{2m}\sum_{i,j} \left( A_{ij} - \frac{k_i k_j}{2m} \right)\delta(C_i, C_j) \\\\[8pt] &= \frac{1}{16}\Bigg[ \left(0 - \frac{k_1 k_1}{16}\right) + 2\left(1 - \frac{k_1 k_2}{16}\right) + \left(0 - \frac{k_2 k_2}{16}\right) + \left(0 - \frac{k_3 k_3}{16}\right) \\\\[4pt] &\quad + 2\left(1 - \frac{k_3 k_4}{16}\right) + 2\left(0 - \frac{k_3 k_5}{16}\right) + 2\left(0 - \frac{k_3 k_6}{16}\right) + 2\left(0 - \frac{k_3 k_7}{16}\right) \\\\[4pt] &\quad + \left(0 - \frac{k_4 k_4}{16}\right) + 2\left(1 - \frac{k_4 k_5}{16}\right) + 2\left(1 - \frac{k_4 k_6}{16}\right) + 2\left(0 - \frac{k_4 k_7}{16}\right) \\\\[4pt] &\quad + \left(0 - \frac{k_5 k_5}{16}\right) + 2\left(0 - \frac{k_5 k_6}{16}\right) + 2\left(1 - \frac{k_5 k_7}{16}\right) + \left(0 - \frac{k_6 k_6}{16}\right) \\\\[4pt] &\quad + 2\left(1 - \frac{k_6 k_7}{16}\right) + \left(0 - \frac{k_7 k_7}{16}\right) \Bigg] \\\\[8pt] &= \frac{19}{128} \end{aligned} $$2. 模块度应用
(1)针对加权图的模块度
给定一个无向图 $G = (V, E)$,其邻接矩阵为 $A$,并关联一个权重矩阵 $W$:
$$ W_{ij} = \begin{cases} w_{ij}, & \text{if } A_{ij} = 1 \\ 0, & \text{otherwise} \end{cases} $$模块度被定义为:
$$ Q = \frac{1}{2m} \sum_{i,j} \left( W_{ij} - \frac{k_i k_j}{2m} \right) \delta(C_i, C_j) $$其中:
- $m$ 表示图中所有边的总权重
- $C_i$ 表示节点 $v_i$ 所属的社区
- $k_i$ 不再是节点 $v_i$ 的度,而是连接到 $v_i$ 的所有边的权重之和
(2)针对有向图的模块度
给定有向图 $G = (V, E)$,其邻接矩阵为 $A$:
$$ A_{ij} = \begin{cases} 1, & \text{if } (v_i, v_j) \in E \\ 0, & \text{otherwise} \end{cases} $$模块度被定义为(注意分母是 $m$,不是 $2m$):
$$ Q = \frac{1}{m} \sum_{i,j} \left( A_{ij} - \frac{k_i^{\text{out}} k_j^{\text{in}}}{m} \right) \delta(C_i, C_j) $$其中:
- $m$ 表示图中的总边数
- $C_i$ 表示节点 $v_i$ 所属的社区
- $k_i^{\text{out}}$ 和 $k_i^{\text{in}}$ 分别表示节点 $v_i$ 的出度和入度
(3)模块度矩阵形式
对于无向图,模块度还可以写成矩阵形式。
定义一个 $n \times k$ 的社区指派矩阵 $S$,其中:
- $S_{ir} = 1$ 表示节点 $v_i$ 属于第 $r$ 个社区
- $S_{ir} = 0$ 表示节点 $v_i$ 不属于第 $r$ 个社区
则有:
$$ \delta(C_i, C_j) = \sum_r S_{ir} S_{jr} $$定义实对称矩阵 $B$,其元素为:
$$ B_{ij} = A_{ij} - \frac{k_i k_j}{2m} $$社区结构的模块度可以改写为:
$$ Q = \frac{1}{2m} \sum_{i,j} \left( A_{ij} - \frac{k_i k_j}{2m} \right) \delta(C_i, C_j) $$$$ = \frac{1}{2m} \sum_{i,j} B_{ij} \sum_r S_{ir} S_{jr} $$$$ = \frac{1}{2m} \sum_{i,j} \sum_r B_{ij} S_{ir} S_{jr} $$$$ = \frac{1}{2m} \operatorname{Tr}(S^{\mathsf T} B S) $$其中,$\operatorname{Tr}(S^{\mathsf T} B S)$ 表示矩阵 $S^{\mathsf T} B S$ 的迹,即其对角元素之和。
3. 谱方法
谱方法:自顶向下的迭代式社区发现方法,基于分裂思想。
- 每次只将一个图分成两个社区,以此类推,直到模块度不再变化为止
- 假设每次划分时,划分的两个社区分别为社区 1 和社区 2
- 顶点要么落在社区 1,要么在社区 2
(1)二分划分变量的定义
因此定义变量:
$$ s_i = \begin{cases} 1, & \text{如果顶点 } v_i \text{ 在社区 1} \\ -1, & \text{否则} \end{cases} $$(2)二分情况下的模块度表达式
因此,二分社区的模块度可以改写为:
$$ Q = \frac{1}{4m} \sum_{i,j} \left( A_{ij} - \frac{k_i k_j}{2m} \right) (s_i s_j + 1) $$$$ = \frac{1}{4m} \sum_{i,j} \left( A_{ij} - \frac{k_i k_j}{2m} \right) s_i s_j $$$$ = \frac{1}{4m} s^{\mathsf T} B s $$其中模块度矩阵 $B$ 定义为:
$$ B_{ij} = A_{ij} - \frac{k_i k_j}{2m} $$注意到,在模块度矩阵 $B$ 中,每一行和每一列的元素之和均为 0,因此向量 $(1,1,\dots,1)$ 是特征值为 0 的特征向量。
(3)模块度矩阵的谱分解
假设模块度矩阵 $B$ 具有 $n$ 个正交特征向量 $\{u_i\}$,对应特征值为:
$$ \beta_1 \ge \beta_2 \ge \cdots \ge \beta_n $$因此,划分向量 $s = (s_1, s_2, \dots, s_n)$ 可以展开为:
$$ s = \sum_{i=1}^n a_i u_i, \qquad a_i = u_i^{\mathsf T} s $$(4)模块度的谱展开形式
将上述展开代入模块度表达式,得到:
$$ Q = \frac{1}{4m} \sum_i a_i u_i^{\mathsf T} B \sum_j a_j u_j $$利用特征向量的正交性,可进一步化简为:
$$ Q = \frac{1}{4m} \sum_{i=1}^n (u_i^{\mathsf T} s)^2 \beta_i $$由此可见,模块度由所有特征值 $\beta_i$ 共同决定。
(5)基于最大特征值的近似最优化
给定图 $G$,其模块度矩阵 $B$ 的特征值和特征向量是固定的。
为了最大化模块度,需要考虑所有特征值 $\beta_i$,但计算代价较高。
因此,通常仅考虑最大的特征值 $\beta_1$ 及其对应的特征向量 $u_1$。
若对划分向量 $s$ 不加限制,最优解应使 $s$ 与 $u_1$ 平行。
但由于 $s_i \in \{1, -1\}$,问题转化为最大化点积 $u_1^{\mathsf T} s$。
因此定义划分规则为:
$$ s_i = \begin{cases} 1, & \text{如果 } u_{1i} > 0 \\ -1, & \text{否则} \end{cases} $$即在最大特征值对应的特征向量 $u_1$ 中:
- 同号分量对应的顶点属于同一社区
- 不同号分量对应的顶点属于不同社区
(6)扩展到多个社区的递归划分问题
鉴于图中可能包含超过 2 个社区,因此希望可以划分为更多部分。
一种自然的做法是重复进行二分划分:
- 首先将网络分成两部分
- 然后对每个子图继续应用上述方法
但这种方法并不正确,原因在于:
- 边的删除会改变模块度的定义
- 后续的模块度最大化将不断放大误差
(7)基于模块度增量的正确递归策略
为避免上述问题,每次仅考虑划分带来的模块度增量。
设子社区 $g$ 的规模为 $n$,其模块度增量定义为:
模块度增量推导
社区 $g$ 的模块度增量 $\Delta Q$ 可以通过以下步骤推导:
第一步:基本形式
$$ \Delta Q = \frac{1}{2m} \left[ \frac{1}{2} \sum_{i,j \in g} B_{ij}(s_i s_j + 1) - \sum_{i,j \in g} B_{ij} \right] $$第二步:化简
$$ \Delta Q = \frac{1}{4m} \left[ \sum_{i,j \in g} B_{ij} s_i s_j - \sum_{i,j \in g} B_{ij} \right] $$第三步:引入克罗内克函数
$$ \Delta Q = \frac{1}{4m} \sum_{i,j \in g} \left[ B_{ij} - \delta_{ij} \sum_{k \in g} B_{ik} \right] s_i s_j $$其中,克罗内克函数定义为:
$$ \delta_{ij} = \begin{cases} 1 & \text{当 } i=j \\ 0 & \text{当 } i \neq j \end{cases} $$第四步:矩阵形式
$$ \Delta Q = \frac{1}{4m} \mathbf{s}^{\mathsf{T}} B^{(g)} \mathbf{s} $$其中,$B^{(g)}$ 是社区 $g$ 的模块度矩阵,$\mathbf{s}$ 是社区划分向量。
符号说明
- $m$:网络中边的总数
- $B_{ij}$:模块度矩阵元素
- $s_i, s_j$:节点 $i, j$ 的社区标签(+1或-1)
- $\delta_{ij}$:克罗内克函数
- $B^{(g)}$:社区 $g$ 的模块度矩阵
- $\mathbf{s}^{\mathsf{T}}$:向量 $\mathbf{s}$ 的转置
因此,仅当模块度增量 $\Delta Q > 0$ 时,才继续划分该子社区;否则停止划分。
由此可以保证,每一次社区划分都会使整体模块度单调增加。
四、Louvain 方法
1. Louvain 方法概述
Louvain 方法是一种社区检测的贪心算法,具有以下特点:
- 支持有向图和加权图
- 提供层次化分区
- 社区数量不是超参数,算法自动确定
- 广泛用于研究大型网络,因为:
- 快速:运行时间仅为 $O(|E|)$,其中 $|E|$ 是边的数量
- 收敛速度快
- 输出的模块度高(即“更好的社区”)
Louvain 算法以贪心方式逐步最大化模块度。
每次遍历包含两个阶段,迭代重复这些遍历,直到模块度不再增加为止。
2. 模块度重写
在 Louvain 方法中,模块度可以重写为更便于计算的形式:
$$ M = \frac{1}{2m} \sum_{i,j} \left( A_{ij} - \frac{k_i k_j}{2m} \right) \delta(C_i, C_j) $$$$ = \left[ \sum_{i,j} \frac{A_{ij}}{2m}
- \frac{\sum_i k_i \sum_j k_j}{4m^2} \right] \delta(C_i, C_j) $$
$$ = \sum_{c \in C} \left[ \frac{\Sigma_{in}^c}{2m}
- \left( \frac{\Sigma_{tot}^c}{2m} \right)^2 \right] $$
其中:
- $\Sigma_{in}^c$ 是社区 $c$ 内部顶点之间的边权重之和
- $\Sigma_{tot}^c$ 是社区 $c$ 中所有顶点的边权重总和
- $m$ 是图中所有边的权重总和
3. Louvain 方法:阶段 1(模块度重写)
初始化:
将图中的每个顶点放入一个独立的社区(每个社区一个顶点)。
迭代过程:
对于每个顶点 $v_i$,算法执行以下计算:
(1) 计算当把顶点 $v_i$ 从其当前社区移动到某个邻近顶点 $v_j$ 的社区时模块度的增量 $\Delta Q$
(2) 将 $v_i$ 移动到能够产生最大模块度增量 $\Delta Q$ 的社区
(3) 循环运行直到没有移动能带来增益为止
第一阶段在达到模块度的局部最大值时停止,即当任何单个移动都不能再改进模块度时。
需要注意的是,算法的输出依赖于考虑顶点的顺序,但研究表明顶点顺序对最终模块度的影响并不显著。
4. 模块度增益计算
模块度变化的两个部分:
模块度的变化可以分为两个部分:
- 增益:$\Delta Q(v_i \to C)$,表示将顶点 $v_i$ 移动到社区 $C$ 时模块度 $Q$ 的增益
- 损失:$\Delta Q(D \to v_i)$,表示将顶点 $v_i$ 从社区 $D$ 中移出时模块度 $Q$ 的损失
将顶点 $v_i$ 移入社区 $C$ 的增益:
$$ \Delta Q(v_i \to C) = \left[\frac{\Sigma_{in}^C + k_{i,in}^C}{2m} - \left(\frac{\Sigma_{tot}^C + k_i}{2m}\right)^2\right] - \left[\frac{\Sigma_{in}^C}{2m} - \left(\frac{\Sigma_{tot}^C}{2m}\right)^2 - \left(\frac{k_i}{2m}\right)^2\right] $$$$ = \left[\frac{k_{i,in}^C}{2m} - \frac{\Sigma_{tot}^C \cdot k_i}{2m^2}\right] $$其中:
- $k_{i,in}^C$ 是顶点 $v_i$ 与社区 $C$ 内部顶点之间的边权重之和
- $k_i$ 是顶点 $v_i$ 的度(所有相连边的权重之和)
将顶点 $v_i$ 从社区 $D$ 中移出的损失:
设 $D'$ 是移出 $v_i$ 后的社区 $D$,则:
$$ \Delta Q(D \to v_i) = - \Delta Q(v_i \to D') $$$$ = \frac{\Sigma_{tot}^{D'} \cdot k_i}{2m^2} - \frac{k_{i,in}^{D'}}{2m} $$总的模块度变化:
$$ \Delta Q = \Delta Q(v_i \to C) + \Delta Q(D \to v_i) $$5. Louvain 方法:阶段 2(社区聚合)
在第一阶段获得的分区被收缩成超级节点,并按照以下方式创建加权网络:
- 如果对应社区之间的顶点之间至少存在一条边,则超级节点之间是连接的。
- 两个超级节点之间边的权重是它们对应分区之间所有边的权重之和。
- 聚合之后,图成为一个加权图,
6. Louvain 方法分析
计算效率:
- 算法运行速度快,在第一次遍历后社区数量急剧减少
- 后续遍历中的计算量显著降低
- 模块度增益计算简单
- 时间复杂度为 $O(|E|)$ 对于包含 $10^6$ 个顶点的图,找到社区结构所需时间通常不到 1 分钟
其他优势:
- 社区数量不是超参数,算法自动确定
- 可以用于评估社区结构的质量
- 可通过模块度曲线确定最佳的簇数量
模块度用于确定簇的数量:
在层次聚类等方法中,可以通过计算不同切割高度下的模块度, 选择模块度最大时对应的簇数量作为最优划分。
模块度曲线通常呈现“先上升、后下降”的趋势,其峰值对应最佳的社区划分。
第九讲 子模函数及其应用
一、应用背景
1.特征选择(Feature Selection)
- 问题描述:给定一组特征 X₁, …, Xₙ,构造子集 A = (Xᵢ₁, …, Xᵢₖ) 用以预测目标变量 Y
- 核心问题:如何选取 k 个特征,使子集信息量最丰富?
- 信息增益:I(A; Y) = H(Y) − H(Y | A)
- H(Y):Y 的熵(表示不确定性)
- H(Y | A):给定 A 条件下 Y 的条件熵
- I(A; Y) 描述通过知道 A 能够获得关于 Y 的信息量
2.影响力最大化(Influence Maximization)
- 基于社交网络,向哪些用户投放广告以达到最佳传播效果
- 找出最具影响力的博客或个人,将信息快速、有效地传播给受众
3.传感器部署(Sensor Placement)
-
问题:给定水分配网络,如何部署传感器以快速检测污染?
-
函数定义:f(A) 表示在子集 A 处部署传感器的效用值
-
效用特性:
- 信息量高的配置(如 A = {1, 2, 3}):f(A) 值大
- 信息冗余度大的配置(如 A = {1, 4, 5}):f(A) 值较低
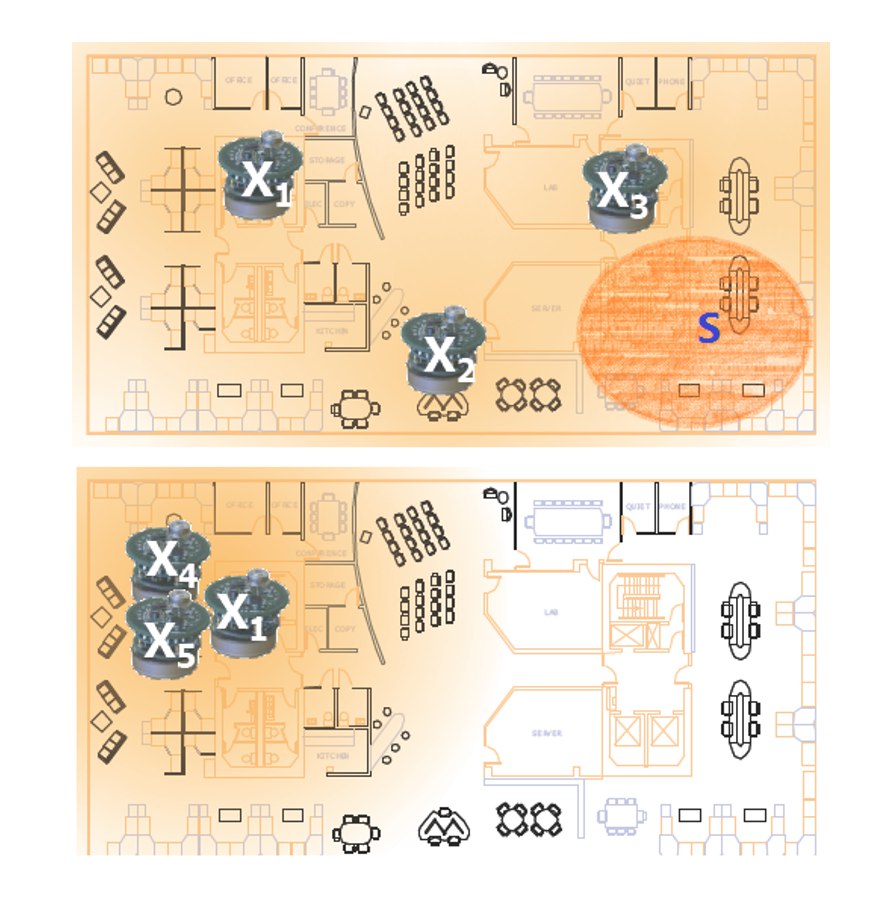
4.图的割函数(Graph Cut)
- 定义:对无向图 G(V, E),割函数 f(S) = |{(u, v) | u ∈ S ⊂ V, v ∈ Sᶜ}|
- 含义:集合 S 与其补集之间的边数
- 示例:S = {1, 2, 3} 时 f(S) = 1;S = {1, 2} 时 f(S) = 2
5. 连续优化
凸函数优化(求最小值)
- 若 f: Rⁿ → R 是凸函数,则可高效获取最小值
- 凸函数特性:连接凸函数图像上任意两点的线段总是在函数图像之上或恰好位于图像上
- 几何直观:U形曲线,底部有唯一最小值点
凹函数优化(求最大值)
- 若 f: Rⁿ → R 是凹函数,则可高效获取最大值
- 凹函数特性:连接凹函数图像上任意两点的线段总是在函数图像之下或恰好位于图像上
- 几何直观:倒U形曲线,顶部有唯一最大值点
6. 离散优化:从凹性到子模性
连续优化中的凹函数
- 若 f : Rⁿ → R 是凹函数,则可高效获取最大值
- 连接凹函数图像上任意两点的线段总在函数图像之下或恰好位于图像上
- 导数 f’(x) 随 x 增加而非递增
离散情况下的子模性
- 对于函数 f : {0,1}ⁿ → R
- 离散导数:∂ᵢf(x) = f(x + eᵢ) − f(x)
- 若 ∂ᵢf(x) 随 x 增加而非递增,则函数是子模的
- eᵢ 表示第 i 个分量为 1,其余分量为 0 的单位向量
二、子模函数
1. 集合函数基础
定义
- 给定有限集合 V = {1, 2, ···, n}
- 集合函数:f : 2^V → R(或 f : {0, 1}ⁿ → R)
- 2^V 是集合 V 的幂集
集合函数的基本性质
- 单调性:若 A ⊆ B ⊆ X,则 F(A) ≤ F(B)
- 非负性:对于所有 S ⊆ X,F(A) ≥ 0
- 规范化:F(∅) = 0
2.子模性定义
定义1:基本形式
对于函数 f : 2^V → R,如果对于所有 A, B ⊆ V,均有:
$f(A) + f(B) ≥ f(A ∪ B) + f(A ∩ B)$ 则该函数是子模的。
等价形式:$f(A) − f(A ∩ B) ≥ f(A ∪ B) − f(B)$
定义2:边际效用递减
对于所有 $S ⊆ T ⊆ V$,对于所有 $v ∈ V T$:$f(S ∪ {v}) − f(S) ≥ f(T ∪ {v}) − f(T)$
经济学解释:对象在更大的上下文中增加的价值逐渐减少
定义3:群体边际效用递减
对于所有 S ⊆ T ⊆ V,且 C ⊆ V \ T:$f(S ∪ C) − f(S) ≥ f(T ∪ C) − f(T)$
3. 子模性的闭合性质
子模性在非负线性组合下具有闭合性质:
-
非负线性组合:若 f₁ 和 f₂ 都是子模函数,a₁, a₂ ≥ 0,则 a₁f₁ + a₂f₂ 是子模函数
-
集合限制:若 S ⊂ V 是固定集合,则 f’(A) = f(A ∩ S) 和 f(A) = f(Aᶜ) 都是子模的
-
期望保持:若 fθ(A) 是子模的,则 Σθ P(θ)fθ(A) 也是子模的
-
多目标优化:若 f₁, ···, fₘ 都是子模的,且 λᵢ > 0,则 Σᵢλᵢfᵢ(A) 也是子模的
4. 典型案例
案例1:传感器部署
-
边际效应:Δf(s|A) = f(A ∪ {s}) − f(A)
-
若 A = {1, 2},增加部署 s 的效果显著
-
若 A = {1, 2, 3},增加部署 s 的效果一般
-
验证子模性:∀A ⊂ B,s ∉ B,Δf(s|A) ≥ Δf(s|B)
案例2:计算不同颜色数量
-
给定一组球的集合 S,f(S) 计算不同颜色的数量
-
子模性:对象在更大上下文中增加的价值逐渐减少
案例3:集合覆盖
-
C 的覆盖定义为:f(C) = |⋃_{sᵢ∈C} sᵢ|
-
满足单调性和子模性
三、集合覆盖问题
1. k-最大覆盖问题
问题定义
- 集合覆盖:每个条目 u 是由某些基础元素组成的子集
- 覆盖函数:f(S) = |⋃_{u∈S} u|(所有属于 S 中子集的并集的大小)
- 边际覆盖增加:f(S ∪ {v}) − f(S)
k-最大覆盖问题
- 目标:寻找 k 个子集,使联合覆盖尽可能大
- 复杂性:NP-hard 问题(无多项式时间算法,除非 P=NP)
示例(k=2)
-
给定:
- 真实集合:{a, b, c, d, e, f, g, h, i, j, k, l}
- 子集:
- A₁ = {a, b, c, d}
- A₂ = {e, f, g, h}
- A₃ = {i, j, k, l}
- A₄ = {a, e}
- A₅ = {i, b, f, g}
- A₆ = {c, d, g, h, k, l}
- A₇ = {l}
-
计算:
- A₆ 有 6 个元素,A₁, A₂, A₃, A₅ 各有 4 个元素
- |A1 ∪ A6| = 8, |A2 ∪ A6| = 8, |A3 ∪ A6| = 8, |A5 ∪ A6| = 9
-
|A₅ ∪ A₆| = 9(最大)
-
结果:C = {A₅, A₆} 是最大覆盖集合
2. 抽取式文本摘要问题
给定:
- 关键词集合 W = {w₁, w₂, ···, wₙ}
- 句子集合 S = {s₁, s₂, ···, sₘ}
- 每个 sⱼ = {wₖ | wₖ ∈ W}
目标:找到 k 个句子,包含尽可能多的关键词
数学表达:
最大化:Σⱼ₌₁ⁿ Σᵢ₌₁ᵐ Xᵢsᵢⱼ
约束条件:Σᵢ₌₁ᵐ Xᵢ = k
其中:
- Xᵢ = 1(若 sᵢ ∈ C),0(否则)
- sᵢⱼ = 1(若 wᵢ ∈ sⱼ),0(否则)
3.子模覆盖
C的覆盖被定义为:f(C)=|⋃1_(s_i∈C)▒s_i |
令 C ⊂ D, 且 sk ∈ D, 我们有:
f(C∪{S_k })-f(C)=|s_k-⋃1_(S_i∈C)▒s_i |≥|s_k-⋃1_(s_i∈D)▒s_i |=f(D∪{s_k })-f(D)
此外, 由于 ⋃1_(s_i∈C)▒〖s_i⊂⋃1_(s_i∈D)▒s_i 〗 , 则:f (C) ≤ f (D).
4. 爬山算法(Greedy Algorithm)
算法流程
1. 初始化 C = ∅
2. for i = 1 to k do
3. c = arg max_{s∈S\C} [f(C ∪ {s}) − f(C)]
4. C = C ∪ {c}
5. output C
理论保证
若集合函数 f 是单调、子模的,且 f(∅) = 0,则贪心算法可达到 (1 − 1/e) 的近似率:
f(S) ≥ (1 − 1/e) max_{S'⊆V, |S'|=k} f(S')
其中 e ≈ 2.718(自然常数)
算法示例
-
给定:
- 关键词集合 W = {w₁, w₂, ···, w₈}
- 9个句子 s₁, s₂, …, s₉
- 目标:选择 k=3 个句子
-
第一轮:
- 计算每个句子的覆盖增益 Δ(Sᵢ)
- s₄ 具有最大覆盖增益(Δ = 4),被选中
- C = {s₄}
-
第二轮:
- 在剩余句子中计算边际增益
- s₅ 和 s₈ 具有最大边际增益(Δ = 2)
- 选择 s₅
- C = {s₄, s₅}
-
第三轮:
- s₁, s₈, s₉ 具有相同边际增益(Δ = 1)
- 选择 s₁
- C = {s₄, s₅, s₁}
-
最终输出:C = {s₄, s₅, s₁}
5. 最小规模集合覆盖问题
问题定义
-
输入:
- 元素集合 X = {e₁, e₂, …, eₙ}
- m 个子集 S₁, S₂, …, Sₘ ⊆ E
-
输出:找到集合 I ⊆ {1,2,…,m},满足:
- ⋃ᵢ∈I Sᵢ = X
- |I| 最小化
-
注意:顶点覆盖问题是集合覆盖问题的特例
实际案例
软件公司员工各有不同技能(C++, Python, Linux, Database, Network…)
- 项目需要多种技能 a₁, a₂, …
- 如何组建最精干的队伍完成项目?
贪心近似算法
Greedy-Set-Cover(X, F)
1. U ← X
2. I ← ∅
3. while U ≠ ∅
4. 选择 Sᵢ 使得 |Sᵢ ∩ U| 最大
5. U ← U − Sᵢ
6. I ← I ∪ {i}
7. return I
理论结果
定理:GREEDY-SET-COVER 是一个多项式时间的 ρ(n) 近似算法,其中:
ρ(n) = H(max{|S| : S ∈ F})
H 是调和级数:H(d) = 1 + 1/2 + 1/3 + … + 1/d